 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Tokenization via Reinforcement Patching: End-to-end Training and Zero-shot Transfer
Mar 27, 2026Efficiently aggregating spatial or temporal horizons to acquire compact representations has become a unifying principle in modern deep learning models, yet learning data-adaptive representations for long-horizon sequence data, especially continuous sequences like time series, remains an open challenge. While fixed-size patching has improved scalability and performance, discovering variable-sized, data-driven patches end-to-end often forces models to rely on soft discretization, specific backbones, or heuristic rules. In this work, we propose Reinforcement Patching (ReinPatch), the first framework to jointly optimize a sequence patching policy and its downstream sequence backbone model using reinforcement learning. By formulating patch boundary placement as a discrete decision process optimized via Group Relative Policy Gradient (GRPG), ReinPatch bypasses the need for continuous relaxations and performs dynamic patching policy optimization in a natural manner. Moreover, our method allows strict enforcement of a desired compression rate, freeing the downstream backbone to scale efficiently, and naturally supports multi-level hierarchical modeling. We evaluate ReinPatch on time-series forecasting datasets, where it demonstrates compelling performance compared to state-of-the-art data-driven patching strategies. Furthermore, our detached design allows the patching module to be extracted as a standalone foundation patcher, providing the community with visual and empirical insights into the segmentation behaviors preferred by a purely performance-driven neural patching strategy.
TimeSqueeze: Dynamic Patching for Efficient Time Series Forecasting
Mar 11, 2026Transformer-based time series foundation models face a fundamental trade-off in choice of tokenization: point-wise embeddings preserve temporal fidelity but scale poorly with sequence length, whereas fixed-length patching improves efficiency by imposing uniform boundaries that may disrupt natural transitions and blur informative local dynamics. In order to address these limitations, we introduce TimeSqueeze, a dynamic patching mechanism that adaptively selects patch boundaries within each sequence based on local signal complexity. TimeSqueeze first applies a lightweight state-space encoder to extract full-resolution point-wise features, then performs content-aware segmentation by allocating short patches to information-dense regions and long patches to smooth or redundant segments. This variable-resolution compression preserves critical temporal structure while substantially reducing the token sequence presented to the Transformer backbone. Specifically for large-scale pretraining, TimeSqueeze attains up to 20x faster convergence and 8x higher data efficiency compared to equivalent point-token baselines. Experiments across long-horizon forecasting benchmarks show that TimeSqueeze consistently outperforms comparable architectures that use either point-wise tokenization or fixed-size patching.
Exploring Explainability in Video Action Recognition
Apr 13, 2024



Image Classification and Video Action Recognition are perhaps the two most foundational tasks in computer vision. Consequently, explaining the inner workings of trained deep neural networks is of prime importance. While numerous efforts focus on explaining the decisions of trained deep neural networks in image classification, exploration in the domain of its temporal version, video action recognition, has been scant. In this work, we take a deeper look at this problem. We begin by revisiting Grad-CAM, one of the popular feature attribution methods for Image Classification, and its extension to Video Action Recognition tasks and examine the method's limitations. To address these, we introduce Video-TCAV, by building on TCAV for Image Classification tasks, which aims to quantify the importance of specific concepts in the decision-making process of Video Action Recognition models. As the scalable generation of concepts is still an open problem, we propose a machine-assisted approach to generate spatial and spatiotemporal concepts relevant to Video Action Recognition for testing Video-TCAV. We then establish the importance of temporally-varying concepts by demonstrating the superiority of dynamic spatiotemporal concepts over trivial spatial concepts. In conclusion, we introduce a framework for investigating hypotheses in action recognition and quantitatively testing them, thus advancing research in the explainability of deep neural networks used in video action recognition.
LIGHTCODE: Light Analytical and Neural Codes for Channels with Feedback
Mar 16, 2024The design of reliable and efficient codes for channels with feedback remains a longstanding challenge in communication theory. While significant improvements have been achieved by leveraging deep learning techniques, neural codes often suffer from high computational costs, a lack of interpretability, and limited practicality in resource-constrained settings. We focus on designing low-complexity coding schemes that are interpretable and more suitable for communication systems. We advance both analytical and neural codes. First, we demonstrate that POWERBLAST, an analytical coding scheme inspired by Schalkwijk-Kailath (SK) and Gallager-Nakiboglu (GN) schemes, achieves notable reliability improvements over both SK and GN schemes, outperforming neural codes in high signal-to-noise ratio (SNR) regions. Next, to enhance reliability in low-SNR regions, we propose LIGHTCODE, a lightweight neural code that achieves state-of-the-art reliability while using a fraction of memory and compute compared to existing deep-learning-based codes. Finally, we systematically analyze the learned codes, establishing connections between LIGHTCODE and POWERBLAST, identifying components crucial for performance, and providing interpretation aided by linear regression analysis.
DeepPolar: Inventing Nonlinear Large-Kernel Polar Codes via Deep Learning
Feb 14, 2024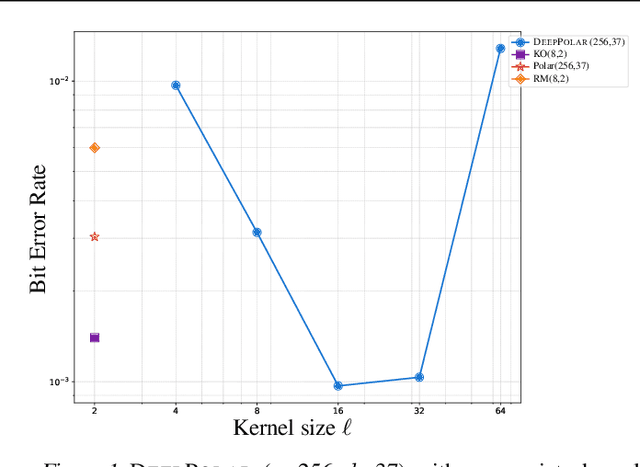
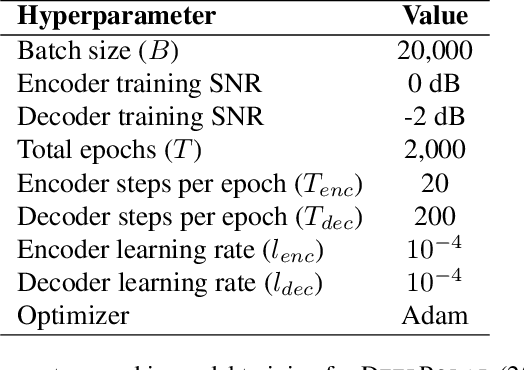

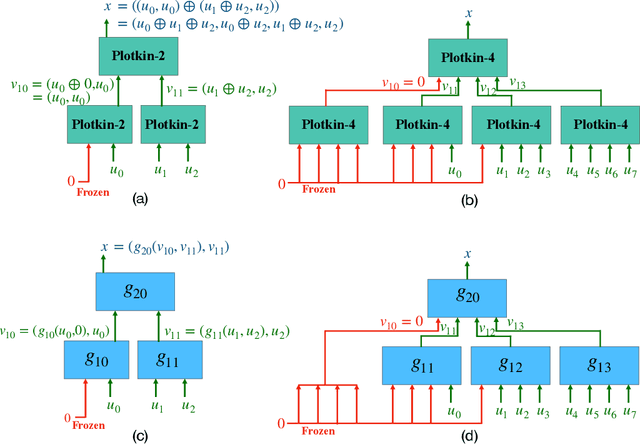
Polar codes, developed on the foundation of Arikan's polarization kernel, represent a breakthrough in coding theory and have emerged as the state-of-the-art error-correction-code in short-to-medium block length regimes. Importantly, recent research has indicated that the reliability of polar codes can be further enhanced by substituting Arikan's kernel with a larger one, leading to a faster polarization. However, for short-to-medium block length regimes, the development of polar codes that effectively employ large kernel sizes has not yet been realized. In this paper, we explore a novel, non-linear generalization of polar codes with an expanded kernel size, which we call DeepPolar codes. Our results show that DeepPolar codes effectively utilize the benefits of larger kernel size, resulting in enhanced reliability compared to both the existing neural codes and conventional polar codes.
Nested Construction of Polar Codes via Transformers
Jan 30, 2024Tailoring polar code construction for decoding algorithms beyond successive cancellation has remained a topic of significant interest in the field. However, despite the inherent nested structure of polar codes, the use of sequence models in polar code construction is understudied. In this work, we propose using a sequence modeling framework to iteratively construct a polar code for any given length and rate under various channel conditions. Simulations show that polar codes designed via sequential modeling using transformers outperform both 5G-NR sequence and Density Evolution based approaches for both AWGN and Rayleigh fading channels.
Task-aware Distributed Source Coding under Dynamic Bandwidth
May 24, 2023Efficient compression of correlated data is essential to minimize communication overload in multi-sensor networks. In such networks, each sensor independently compresses the data and transmits them to a central node due to limited communication bandwidth. A decoder at the central node decompresses and passes the data to a pre-trained machine learning-based task to generate the final output. Thus, it is important to compress the features that are relevant to the task. Additionally, the final performance depends heavily on the total available bandwidth. In practice, it is common to encounter varying availability in bandwidth, and higher bandwidth results in better performance of the task. We design a novel distributed compression framework composed of independent encoders and a joint decoder, which we call neural distributed principal component analysis (NDPCA). NDPCA flexibly compresses data from multiple sources to any available bandwidth with a single model, reducing computing and storage overhead. NDPCA achieves this by learning low-rank task representations and efficiently distributing bandwidth among sensors, thus providing a graceful trade-off between performance and bandwidth. Experiments show that NDPCA improves the success rate of multi-view robotic arm manipulation by 9% and the accuracy of object detection tasks on satellite imagery by 14% compared to an autoencoder with uniform bandwidth allocation.
TinyTurbo: Efficient Turbo Decoders on Edge
Sep 30, 2022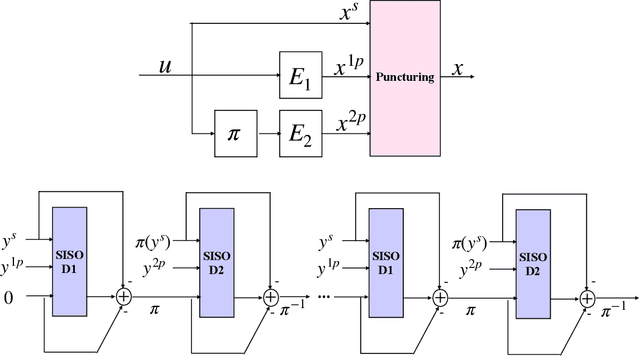

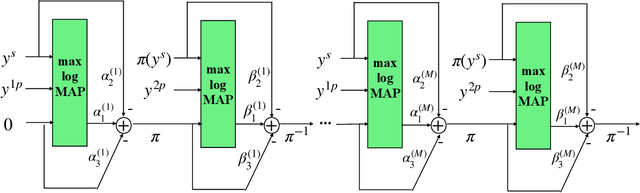
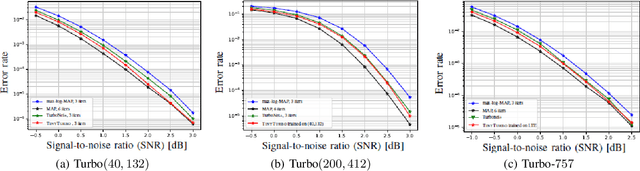
In this paper, we introduce a neural-augmented decoder for Turbo codes called TINYTURBO . TINYTURBO has complexity comparable to the classical max-log-MAP algorithm but has much better reliability than the max-log-MAP baseline and performs close to the MAP algorithm. We show that TINYTURBO exhibits strong robustness on a variety of practical channels of interest, such as EPA and EVA channels, which are included in the LTE standards. We also show that TINYTURBO strongly generalizes across different rate, blocklengths, and trellises. We verify the reliability and efficiency of TINYTURBO via over-the-air experiments.
* 10 pages, 6 figures. Published at the 2022 IEEE International Symposium on Information Theory (ISIT)
Neural Augmented Min-Sum Decoding of Short Block Codes for Fading Channels
May 21, 2022



In the decoding of linear block codes, it was shown that noticeable gains in terms of bit error rate can be achieved by introducing learnable parameters to the Belief Propagation (BP) decoder. Despite the success of these methods, there are two key open problems. The first is the lack of analysis for channels other than AWGN. The second is the interpretation of the weights learned and their effect on the reliability of the BP decoder. In this work, we aim to bridge this gap by looking at non-AWGN channels such as Extended Typical Urban (ETU) channel. We study the effect of entangling the weights and how the performance holds across different channel settings for the min-sum version of BP decoder. We show that while entanglement has little degradation in the AWGN channel, a significant loss is observed in more complex channels. We also provide insights into the weights learned and their connection to the structure of the underlying code. Finally, we evaluate our algorithm on the over-the-air channels using Software Defined Radios.