 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Tokenization via Reinforcement Patching: End-to-end Training and Zero-shot Transfer
Mar 27, 2026Efficiently aggregating spatial or temporal horizons to acquire compact representations has become a unifying principle in modern deep learning models, yet learning data-adaptive representations for long-horizon sequence data, especially continuous sequences like time series, remains an open challenge. While fixed-size patching has improved scalability and performance, discovering variable-sized, data-driven patches end-to-end often forces models to rely on soft discretization, specific backbones, or heuristic rules. In this work, we propose Reinforcement Patching (ReinPatch), the first framework to jointly optimize a sequence patching policy and its downstream sequence backbone model using reinforcement learning. By formulating patch boundary placement as a discrete decision process optimized via Group Relative Policy Gradient (GRPG), ReinPatch bypasses the need for continuous relaxations and performs dynamic patching policy optimization in a natural manner. Moreover, our method allows strict enforcement of a desired compression rate, freeing the downstream backbone to scale efficiently, and naturally supports multi-level hierarchical modeling. We evaluate ReinPatch on time-series forecasting datasets, where it demonstrates compelling performance compared to state-of-the-art data-driven patching strategies. Furthermore, our detached design allows the patching module to be extracted as a standalone foundation patcher, providing the community with visual and empirical insights into the segmentation behaviors preferred by a purely performance-driven neural patching strategy.
TERMINATOR: Learning Optimal Exit Points for Early Stopping in Chain-of-Thought Reasoning
Mar 13, 2026Large Reasoning Models (LRMs) achieve impressive performance on complex reasoning tasks via Chain-of-Thought (CoT) reasoning, which enables them to generate intermediate thinking tokens before arriving at the final answer. However, LRMs often suffer from significant overthinking, spending excessive compute time even after the answer is generated early on. Prior work has identified the existence of an optimal reasoning length such that truncating reasoning at this point significantly shortens CoT outputs with virtually no change in performance. However, determining optimal CoT lengths for practical datasets is highly non-trivial as they are fully task and model-dependent. In this paper, we precisely address this and design TERMINATOR, an early-exit strategy for LRMs at inference to mitigate overthinking. The central idea underpinning TERMINATOR is that the first arrival of an LRM's final answer is often predictable, and we leverage these first answer positions to create a novel dataset of optimal reasoning lengths to train TERMINATOR. Powered by this approach, TERMINATOR achieves significant reductions in CoT lengths of 14%-55% on average across four challenging practical datasets: MATH-500, AIME 2025, HumanEval, and GPQA, whilst outperforming current state-of-the-art methods.
Fine-Tuning Masked Diffusion for Provable Self-Correction
Oct 01, 2025A natural desideratum for generative models is self-correction--detecting and revising low-quality tokens at inference. While Masked Diffusion Models (MDMs) have emerged as a promising approach for generative modeling in discrete spaces, their capacity for self-correction remains poorly understood. Prior attempts to incorporate self-correction into MDMs either require overhauling MDM architectures/training or rely on imprecise proxies for token quality, limiting their applicability. Motivated by this, we introduce PRISM--Plug-in Remasking for Inference-time Self-correction of Masked Diffusions--a lightweight, model-agnostic approach that applies to any pretrained MDM. Theoretically, PRISM defines a self-correction loss that provably learns per-token quality scores, without RL or a verifier. These quality scores are computed in the same forward pass with MDM and used to detect low-quality tokens. Empirically, PRISM advances MDM inference across domains and scales: Sudoku; unconditional text (170M); and code with LLaDA (8B).
Importance Sampling via Score-based Generative Models
Feb 07, 2025



Importance sampling, which involves sampling from a probability density function (PDF) proportional to the product of an importance weight function and a base PDF, is a powerful technique with applications in variance reduction, biased or customized sampling, data augmentation, and beyond. Inspired by the growing availability of score-based generative models (SGMs), we propose an entirely training-free Importance sampling framework that relies solely on an SGM for the base PDF. Our key innovation is realizing the importance sampling process as a backward diffusion process, expressed in terms of the score function of the base PDF and the specified importance weight function--both readily available--eliminating the need for any additional training. We conduct a thorough analysis demonstrating the method's scalability and effectiveness across diverse datasets and tasks, including importance sampling for industrial and natural images with neural importance weight functions. The training-free aspect of our method is particularly compelling in real-world scenarios where a single base distribution underlies multiple biased sampling tasks, each requiring a different importance weight function. To the best of our knowledge our approach is the first importance sampling framework to achieve this.
Neural Cover Selection for Image Steganography
Oct 23, 2024
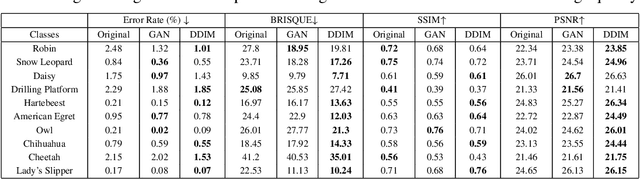
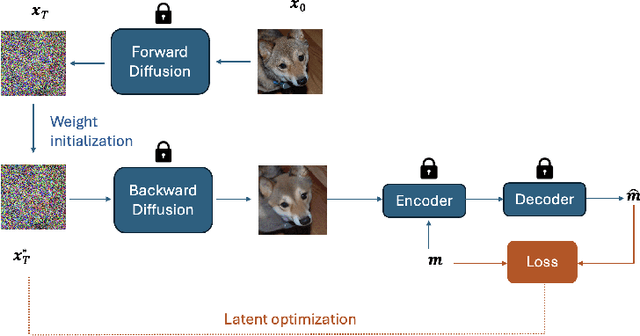
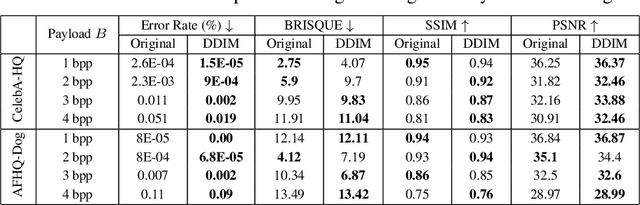
In steganography, selecting an optimal cover image, referred to as cover selection, is pivotal for effective message concealment. Traditional methods have typically employed exhaustive searches to identify images that conform to specific perceptual or complexity metrics. However, the relationship between these metrics and the actual message hiding efficacy of an image is unclear, often yielding less-than-ideal steganographic outcomes. Inspired by recent advancements in generative models, we introduce a novel cover selection framework, which involves optimizing within the latent space of pretrained generative models to identify the most suitable cover images, distinguishing itself from traditional exhaustive search methods. Our method shows significant advantages in message recovery and image quality. We also conduct an information-theoretic analysis of the generated cover images, revealing that message hiding predominantly occurs in low-variance pixels, reflecting the waterfilling algorithm's principles in parallel Gaussian channels. Our code can be found at: https://github.com/karlchahine/Neural-Cover-Selection-for-Image-Steganography.
Generating High Dimensional User-Specific Wireless Channels using Diffusion Models
Sep 05, 2024



Deep neural network (DNN)-based algorithms are emerging as an important tool for many physical and MAC layer functions in future wireless communication systems, including for large multi-antenna channels. However, training such models typically requires a large dataset of high-dimensional channel measurements, which are very difficult and expensive to obtain. This paper introduces a novel method for generating synthetic wireless channel data using diffusion-based models to produce user-specific channels that accurately reflect real-world wireless environments. Our approach employs a conditional denoising diffusion implicit models (cDDIM) framework, effectively capturing the relationship between user location and multi-antenna channel characteristics. We generate synthetic high fidelity channel samples using user positions as conditional inputs, creating larger augmented datasets to overcome measurement scarcity. The utility of this method is demonstrated through its efficacy in training various downstream tasks such as channel compression and beam alignment. Our approach significantly improves over prior methods, such as adding noise or using generative adversarial networks (GANs), especially in scenarios with limited initial measurements.
Fundamental Limits of Prompt Compression: A Rate-Distortion Framework for Black-Box Language Models
Jul 22, 2024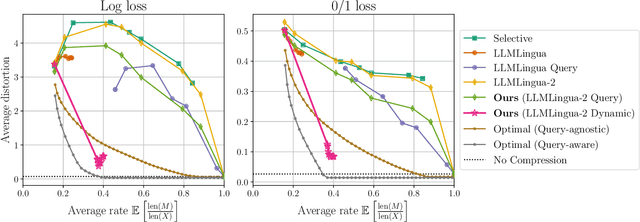
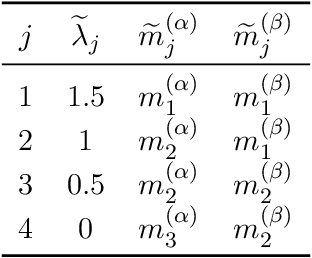
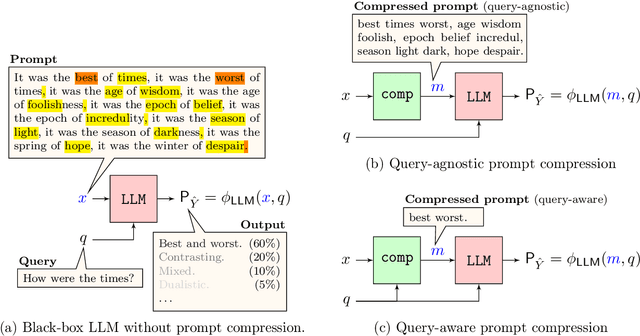

We formalize the problem of prompt compression for large language models (LLMs) and present a framework to unify token-level prompt compression methods which create hard prompts for black-box models. We derive the distortion-rate function for this setup as a linear program, and provide an efficient algorithm to compute this fundamental limit via the dual of the linear program. Using the distortion-rate function as the baseline, we study the performance of existing compression schemes on a synthetic dataset consisting of prompts generated from a Markov chain, natural language queries, and their respective answers. Our empirical analysis demonstrates the criticality of query-aware prompt compression, where the compressor has knowledge of the downstream task/query for the black-box LLM. We show that there is a large gap between the performance of current prompt compression methods and the optimal strategy, and propose a query-aware, variable-rate adaptation of a prior work to close the gap. We extend our experiments to a small natural language dataset to further confirm our findings on our synthetic dataset.
Enhancing K-user Interference Alignment for Discrete Constellations via Learning
Jul 21, 2024



In this paper, we consider a K-user interference channel where interference among the users is neither too strong nor too weak, a scenario that is relatively underexplored in the literature. We propose a novel deep learning-based approach to design the encoder and decoder functions that aim to maximize the sumrate of the interference channel for discrete constellations. We first consider the MaxSINR algorithm, a state-of-the-art linear scheme for Gaussian inputs, as the baseline and then propose a modified version of the algorithm for discrete inputs. We then propose a neural network-based approach that learns a constellation mapping with the objective of maximizing the sumrate. We provide numerical results to show that the constellations learned by the neural network-based approach provide enhanced alignments, not just in beamforming directions but also in terms of the effective constellation at the receiver, thereby leading to improved sum-rate performance.
Local to Global: Learning Dynamics and Effect of Initialization for Transformers
Jun 05, 2024



In recent years, transformer-based models have revolutionized deep learning, particularly in sequence modeling. To better understand this phenomenon, there is a growing interest in using Markov input processes to study transformers. However, our current understanding in this regard remains limited with many fundamental questions about how transformers learn Markov chains still unanswered. In this paper, we address this by focusing on first-order Markov chains and single-layer transformers, providing a comprehensive characterization of the learning dynamics in this context. Specifically, we prove that transformer parameters trained on next-token prediction loss can either converge to global or local minima, contingent on the initialization and the Markovian data properties, and we characterize the precise conditions under which this occurs. To the best of our knowledge, this is the first result of its kind highlighting the role of initialization. We further demonstrate that our theoretical findings are corroborated by empirical evidence. Based on these insights, we provide guidelines for the initialization of transformer parameters and demonstrate their effectiveness. Finally, we outline several open problems in this arena. Code is available at: \url{https://anonymous.4open.science/r/Local-to-Global-C70B/}.
LIGHTCODE: Light Analytical and Neural Codes for Channels with Feedback
Mar 16, 2024The design of reliable and efficient codes for channels with feedback remains a longstanding challenge in communication theory. While significant improvements have been achieved by leveraging deep learning techniques, neural codes often suffer from high computational costs, a lack of interpretability, and limited practicality in resource-constrained settings. We focus on designing low-complexity coding schemes that are interpretable and more suitable for communication systems. We advance both analytical and neural codes. First, we demonstrate that POWERBLAST, an analytical coding scheme inspired by Schalkwijk-Kailath (SK) and Gallager-Nakiboglu (GN) schemes, achieves notable reliability improvements over both SK and GN schemes, outperforming neural codes in high signal-to-noise ratio (SNR) regions. Next, to enhance reliability in low-SNR regions, we propose LIGHTCODE, a lightweight neural code that achieves state-of-the-art reliability while using a fraction of memory and compute compared to existing deep-learning-based codes. Finally, we systematically analyze the learned codes, establishing connections between LIGHTCODE and POWERBLAST, identifying components crucial for performance, and providing interpretation aided by linear regression analysis.