 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImportance Sampling via Score-based Generative Models
Feb 07, 2025



Importance sampling, which involves sampling from a probability density function (PDF) proportional to the product of an importance weight function and a base PDF, is a powerful technique with applications in variance reduction, biased or customized sampling, data augmentation, and beyond. Inspired by the growing availability of score-based generative models (SGMs), we propose an entirely training-free Importance sampling framework that relies solely on an SGM for the base PDF. Our key innovation is realizing the importance sampling process as a backward diffusion process, expressed in terms of the score function of the base PDF and the specified importance weight function--both readily available--eliminating the need for any additional training. We conduct a thorough analysis demonstrating the method's scalability and effectiveness across diverse datasets and tasks, including importance sampling for industrial and natural images with neural importance weight functions. The training-free aspect of our method is particularly compelling in real-world scenarios where a single base distribution underlies multiple biased sampling tasks, each requiring a different importance weight function. To the best of our knowledge our approach is the first importance sampling framework to achieve this.
Learning RL-Policies for Joint Beamforming Without Exploration: A Batch Constrained Off-Policy Approach
Oct 12, 2023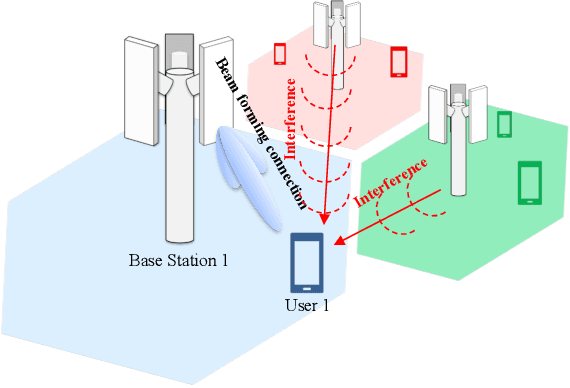
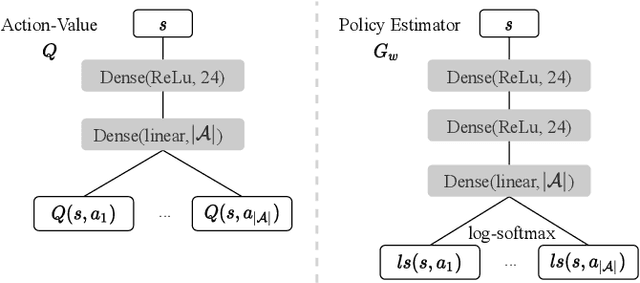
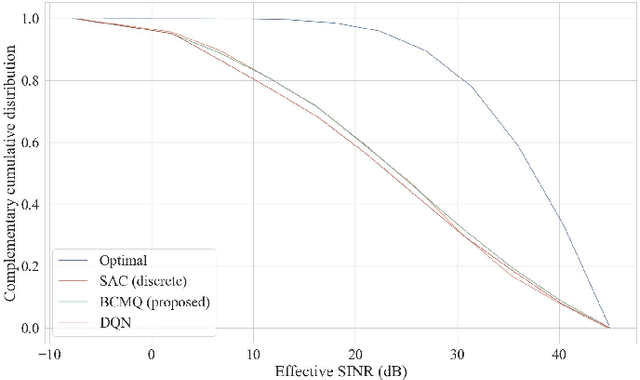
In this project, we consider the problem of network parameter optimization for rate maximization. We frame this as a joint optimization problem of power control, beam forming, and interference cancellation. We consider the setting where multiple Base Stations (BSs) are communicating with multiple user equipments (UEs). Because of the exponential computational complexity of brute force search, we instead solve this non-convex optimization problem using deep reinforcement learning (RL) techniques. The modern communication systems are notorious for their difficulty in exactly modeling their behaviour. This limits us in using RL based algorithms as interaction with the environment is needed for the agent to explore and learn efficiently. Further, it is ill advised to deploy the algorithm in real world for exploration and learning because of the high cost of failure. In contrast to the previous RL-based solutions proposed, such as deep-Q network (DQN) based control, we propose taking an offline model based approach. We specifically consider discrete batch constrained deep Q-learning (BCQ) and show that performance similar to DQN can be acheived with only a fraction of the data and without the need for exploration. This results in maximizing sample efficiency and minimizing risk in the deployment of a new algorithm to commercial networks. We provide the entire resource of the project, including code and data, at the following link: https://github.com/Heasung-Kim/ safe-rl-deployment-for-5g.