 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention with Markov: A Framework for Principled Analysis of Transformers via Markov Chains
Paper and Code
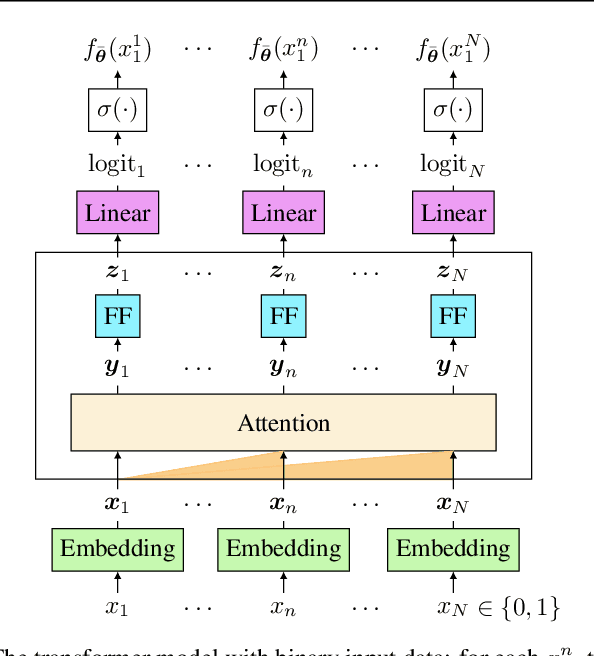

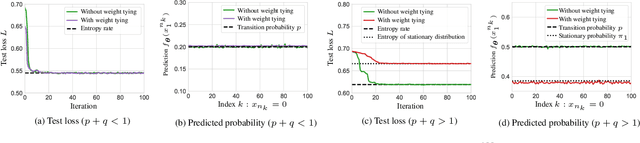

In recent years, attention-based transformers have achieved tremendous success across a variety of disciplines including natural languages. A key ingredient behind their success is the generative pretraining procedure, during which these models are trained on a large text corpus in an auto-regressive manner. To shed light on this phenomenon, we propose a new framework that allows both theory and systematic experiments to study the sequential modeling capabilities of transformers through the lens of Markov chains. Inspired by the Markovianity of natural languages, we model the data as a Markovian source and utilize this framework to systematically study the interplay between the data-distributional properties, the transformer architecture, the learnt distribution, and the final model performance. In particular, we theoretically characterize the loss landscape of single-layer transformers and show the existence of global minima and bad local minima contingent upon the specific data characteristics and the transformer architecture. Backed by experiments, we demonstrate that our theoretical findings are in congruence with the empirical results. We further investigate these findings in the broader context of higher order Markov chains and deeper architectures, and outline open problems in this arena. Code is available at \url{https://github.com/Bond1995/Markov}.