 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete Tilt Matching
Apr 20, 2026Masked diffusion large language models (dLLMs) are a promising alternative to autoregressive generation. While reinforcement learning (RL) methods have recently been adapted to dLLM fine-tuning, their objectives typically depend on sequence-level marginal likelihoods, which are intractable for masked diffusion models. To address this, we derive Discrete Tilt Matching (DTM), a likelihood-free method that recasts dLLM fine-tuning as state-level matching of local unmasking posteriors under reward tilting. DTM takes the form of a weighted cross-entropy objective with explicit minimizer, and admits control variates that improve training stability. On a synthetic maze-planning task, we analyze how DTM's annealing schedule and control variates affect training stability and prevent mode collapse. At scale, fine-tuning LLaDA-8B-Instruct with DTM yields strong gains on Sudoku and Countdown while remaining competitive on MATH500 and GSM8K.
The Interspeech 2026 Audio Reasoning Challenge: Evaluating Reasoning Process Quality for Audio Reasoning Models and Agents
Feb 15, 2026Recent Large Audio Language Models (LALMs) excel in understanding but often lack transparent reasoning. To address this "black-box" limitation, we organized the Audio Reasoning Challenge at Interspeech 2026, the first shared task dedicated to evaluating Chain-of-Thought (CoT) quality in the audio domain. The challenge introduced MMAR-Rubrics, a novel instance-level protocol assessing the factuality and logic of reasoning chains. Featured Single Model and Agent tracks, the competition attracting 156 teams from 18 countries and regions. Results show agent systems currently lead in reasoning quality, utilizing iterative tool orchestration and cross-modal analysis. Besides, single models are rapidly advancing via reinforcement learning and sophisticated data pipeline. We details the challenge design, methodology, and a comprehensive analysis of state-of-the-art systems, providing new insights for explainable audio intelligence.
Stop Training for the Worst: Progressive Unmasking Accelerates Masked Diffusion Training
Feb 10, 2026Masked Diffusion Models (MDMs) have emerged as a promising approach for generative modeling in discrete spaces. By generating sequences in any order and allowing for parallel decoding, they enable fast inference and strong performance on non-causal tasks. However, this flexibility comes with a training complexity trade-off: MDMs train on an exponentially large set of masking patterns, which is not only computationally expensive, but also creates a train--test mismatch between the random masks used in training and the highly structured masks induced by inference-time unmasking. In this work, we propose Progressive UnMAsking (PUMA), a simple modification of the forward masking process that aligns training-time and inference-time masking patterns, thereby focusing optimization on inference-aligned masks and speeding up training. Empirically, PUMA speeds up pretraining at the 125M scale by $\approx 2.5\times$ and offers complementary advantages on top of common recipes like autoregressive initialization. We open-source our codebase at https://github.com/JaeyeonKim01/PUMA.
Fine-Tuning Masked Diffusion for Provable Self-Correction
Oct 01, 2025A natural desideratum for generative models is self-correction--detecting and revising low-quality tokens at inference. While Masked Diffusion Models (MDMs) have emerged as a promising approach for generative modeling in discrete spaces, their capacity for self-correction remains poorly understood. Prior attempts to incorporate self-correction into MDMs either require overhauling MDM architectures/training or rely on imprecise proxies for token quality, limiting their applicability. Motivated by this, we introduce PRISM--Plug-in Remasking for Inference-time Self-correction of Masked Diffusions--a lightweight, model-agnostic approach that applies to any pretrained MDM. Theoretically, PRISM defines a self-correction loss that provably learns per-token quality scores, without RL or a verifier. These quality scores are computed in the same forward pass with MDM and used to detect low-quality tokens. Empirically, PRISM advances MDM inference across domains and scales: Sudoku; unconditional text (170M); and code with LLaDA (8B).
Selective Underfitting in Diffusion Models
Oct 01, 2025Diffusion models have emerged as the principal paradigm for generative modeling across various domains. During training, they learn the score function, which in turn is used to generate samples at inference. They raise a basic yet unsolved question: which score do they actually learn? In principle, a diffusion model that matches the empirical score in the entire data space would simply reproduce the training data, failing to generate novel samples. Recent work addresses this question by arguing that diffusion models underfit the empirical score due to training-time inductive biases. In this work, we refine this perspective, introducing the notion of selective underfitting: instead of underfitting the score everywhere, better diffusion models more accurately approximate the score in certain regions of input space, while underfitting it in others. We characterize these regions and design empirical interventions to validate our perspective. Our results establish that selective underfitting is essential for understanding diffusion models, yielding new, testable insights into their generalization and generative performance.
ERGO: Efficient High-Resolution Visual Understanding for Vision-Language Models
Sep 26, 2025Efficient processing of high-resolution images is crucial for real-world vision-language applications. However, existing Large Vision-Language Models (LVLMs) incur substantial computational overhead due to the large number of vision tokens. With the advent of "thinking with images" models, reasoning now extends beyond text to the visual domain. This capability motivates our two-stage "coarse-to-fine" reasoning pipeline: first, a downsampled image is analyzed to identify task-relevant regions; then, only these regions are cropped at full resolution and processed in a subsequent reasoning stage. This approach reduces computational cost while preserving fine-grained visual details where necessary. A major challenge lies in inferring which regions are truly relevant to a given query. Recent related methods often fail in the first stage after input-image downsampling, due to perception-driven reasoning, where clear visual information is required for effective reasoning. To address this issue, we propose ERGO (Efficient Reasoning & Guided Observation) that performs reasoning-driven perception-leveraging multimodal context to determine where to focus. Our model can account for perceptual uncertainty, expanding the cropped region to cover visually ambiguous areas for answering questions. To this end, we develop simple yet effective reward components in a reinforcement learning framework for coarse-to-fine perception. Across multiple datasets, our approach delivers higher accuracy than the original model and competitive methods, with greater efficiency. For instance, ERGO surpasses Qwen2.5-VL-7B on the V* benchmark by 4.7 points while using only 23% of the vision tokens, achieving a 3x inference speedup. The code and models can be found at: https://github.com/nota-github/ERGO.
WoW-Bench: Evaluating Fine-Grained Acoustic Perception in Audio-Language Models via Marine Mammal Vocalizations
Aug 28, 2025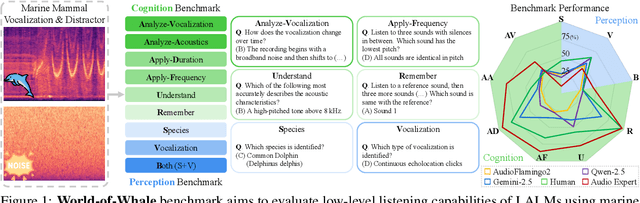

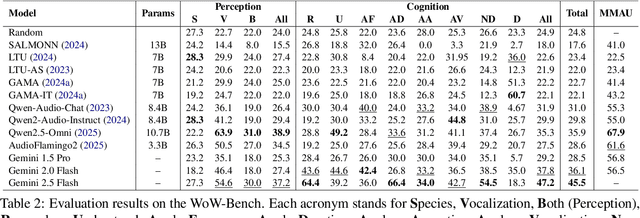
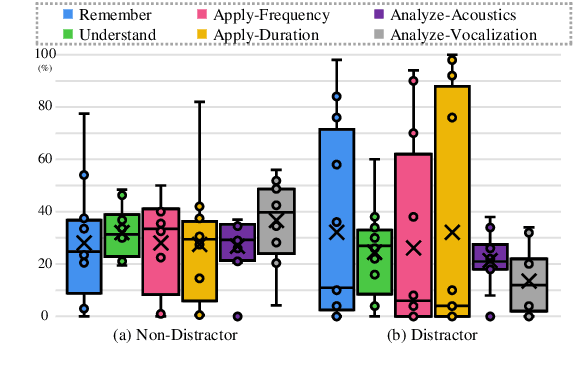
Large audio language models (LALMs) extend language understanding into the auditory domain, yet their ability to perform low-level listening, such as pitch and duration detection, remains underexplored. However, low-level listening is critical for real-world, out-of-distribution tasks where models must reason about unfamiliar sounds based on fine-grained acoustic cues. To address this gap, we introduce the World-of-Whale benchmark (WoW-Bench) to evaluate low-level auditory perception and cognition using marine mammal vocalizations. WoW-bench is composed of a Perception benchmark for categorizing novel sounds and a Cognition benchmark, inspired by Bloom's taxonomy, to assess the abilities to remember, understand, apply, and analyze sound events. For the Cognition benchmark, we additionally introduce distractor questions to evaluate whether models are truly solving problems through listening rather than relying on other heuristics. Experiments with state-of-the-art LALMs show performance far below human levels, indicating a need for stronger auditory grounding in LALMs.
ViSAGe: Video-to-Spatial Audio Generation
Jun 13, 2025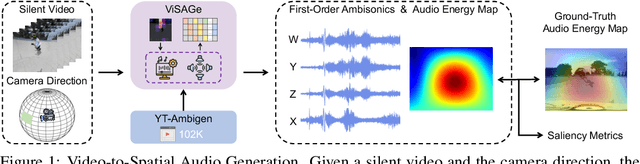
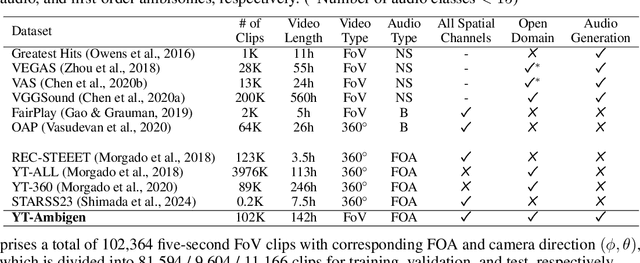
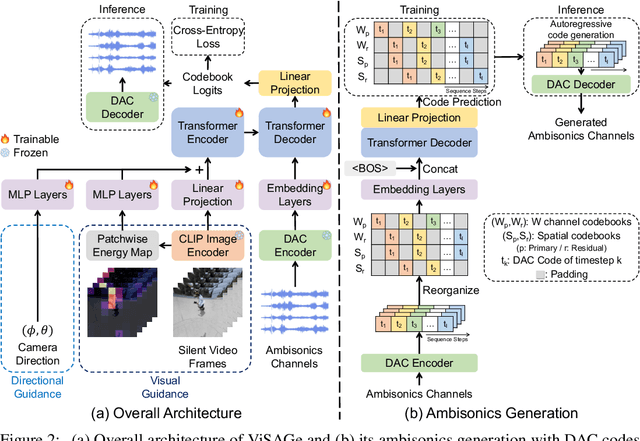
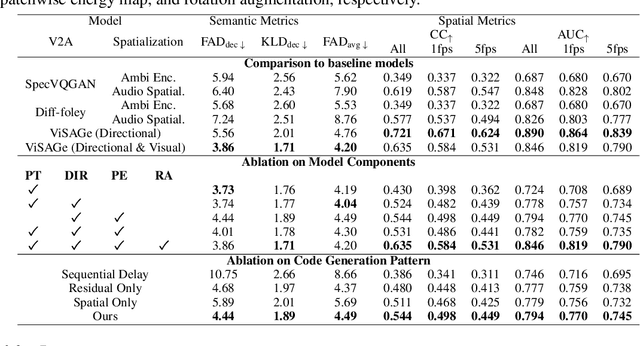
Spatial audio is essential for enhancing the immersiveness of audio-visual experiences, yet its production typically demands complex recording systems and specialized expertise. In this work, we address a novel problem of generating first-order ambisonics, a widely used spatial audio format, directly from silent videos. To support this task, we introduce YT-Ambigen, a dataset comprising 102K 5-second YouTube video clips paired with corresponding first-order ambisonics. We also propose new evaluation metrics to assess the spatial aspect of generated audio based on audio energy maps and saliency metrics. Furthermore, we present Video-to-Spatial Audio Generation (ViSAGe), an end-to-end framework that generates first-order ambisonics from silent video frames by leveraging CLIP visual features, autoregressive neural audio codec modeling with both directional and visual guidance. Experimental results demonstrate that ViSAGe produces plausible and coherent first-order ambisonics, outperforming two-stage approaches consisting of video-to-audio generation and audio spatialization. Qualitative examples further illustrate that ViSAGe generates temporally aligned high-quality spatial audio that adapts to viewpoint changes.
Multi-Domain Audio Question Answering Toward Acoustic Content Reasoning in The DCASE 2025 Challenge
May 12, 2025We present Task 5 of the DCASE 2025 Challenge: an Audio Question Answering (AQA) benchmark spanning multiple domains of sound understanding. This task defines three QA subsets (Bioacoustics, Temporal Soundscapes, and Complex QA) to test audio-language models on interactive question-answering over diverse acoustic scenes. We describe the dataset composition (from marine mammal calls to soundscapes and complex real-world clips), the evaluation protocol (top-1 accuracy with answer-shuffling robustness), and baseline systems (Qwen2-Audio-7B, AudioFlamingo 2, Gemini-2-Flash). Preliminary results on the development set are compared, showing strong variation across models and subsets. This challenge aims to advance the audio understanding and reasoning capabilities of audio-language models toward human-level acuity, which are crucial for enabling AI agents to perceive and interact about the world effectively.
Efficient LLaMA-3.2-Vision by Trimming Cross-attended Visual Features
Apr 01, 2025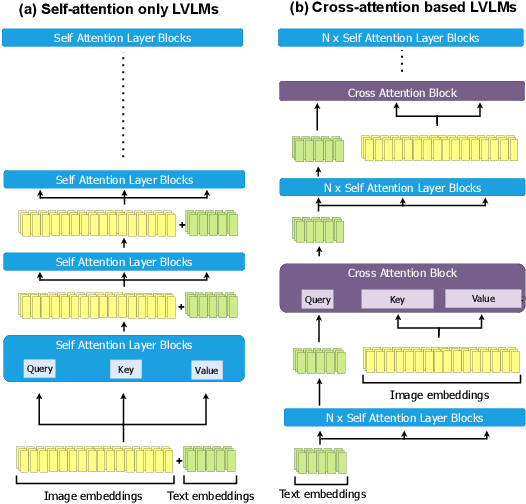
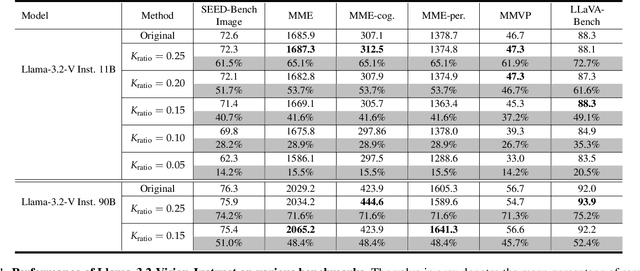
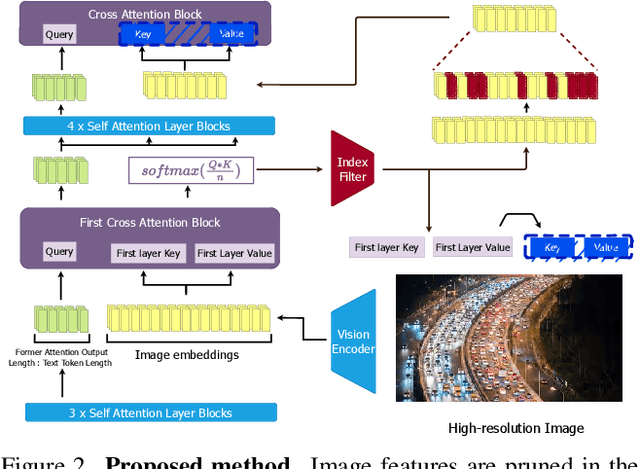
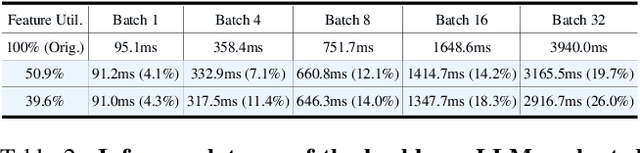
Visual token reduction lowers inference costs caused by extensive image features in large vision-language models (LVLMs). Unlike relevant studies that prune tokens in self-attention-only LVLMs, our work uniquely addresses cross-attention-based models, which achieve superior performance. We identify that the key-value (KV) cache size for image tokens in cross-attention layers significantly exceeds that of text tokens in self-attention layers, posing a major compute bottleneck. To mitigate this issue, we exploit the sparse nature in cross-attention maps to selectively prune redundant visual features. Our Trimmed Llama effectively reduces KV cache demands without requiring additional training. By benefiting from 50%-reduced visual features, our model can reduce inference latency and memory usage while achieving benchmark parity.