 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvably Learning Attention with Queries
Jan 23, 2026We study the problem of learning Transformer-based sequence models with black-box access to their outputs. In this setting, a learner may adaptively query the oracle with any sequence of vectors and observe the corresponding real-valued output. We begin with the simplest case, a single-head softmax-attention regressor. We show that for a model with width $d$, there is an elementary algorithm to learn the parameters of single-head attention exactly with $O(d^2)$ queries. Further, we show that if there exists an algorithm to learn ReLU feedforward networks (FFNs), then the single-head algorithm can be easily adapted to learn one-layer Transformers with single-head attention. Next, motivated by the regime where the head dimension $r \ll d$, we provide a randomised algorithm that learns single-head attention-based models with $O(rd)$ queries via compressed sensing arguments. We also study robustness to noisy oracle access, proving that under mild norm and margin conditions, the parameters can be estimated to $\varepsilon$ accuracy with a polynomial number of queries even when outputs are only provided up to additive tolerance. Finally, we show that multi-head attention parameters are not identifiable from value queries in general -- distinct parameterisations can induce the same input-output map. Hence, guarantees analogous to the single-head setting are impossible without additional structural assumptions.
ReGuidance: A Simple Diffusion Wrapper for Boosting Sample Quality on Hard Inverse Problems
Jun 12, 2025There has been a flurry of activity around using pretrained diffusion models as informed data priors for solving inverse problems, and more generally around steering these models using reward models. Training-free methods like diffusion posterior sampling (DPS) and its many variants have offered flexible heuristic algorithms for these tasks, but when the reward is not informative enough, e.g., in hard inverse problems with low signal-to-noise ratio, these techniques veer off the data manifold, failing to produce realistic outputs. In this work, we devise a simple wrapper, ReGuidance, for boosting both the sample realism and reward achieved by these methods. Given a candidate solution $\hat{x}$ produced by an algorithm of the user's choice, we propose inverting the solution by running the unconditional probability flow ODE in reverse starting from $\hat{x}$, and then using the resulting latent as an initialization for DPS. We evaluate our wrapper on hard inverse problems like large box in-painting and super-resolution with high upscaling. Whereas state-of-the-art baselines visibly fail, we find that applying our wrapper on top of these baselines significantly boosts sample quality and measurement consistency. We complement these findings with theory proving that on certain multimodal data distributions, ReGuidance simultaneously boosts the reward and brings the candidate solution closer to the data manifold. To our knowledge, this constitutes the first rigorous algorithmic guarantee for DPS.
Does Generation Require Memorization? Creative Diffusion Models using Ambient Diffusion
Feb 28, 2025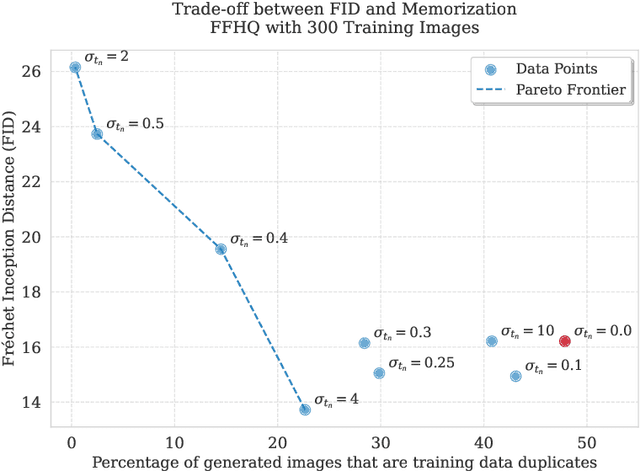
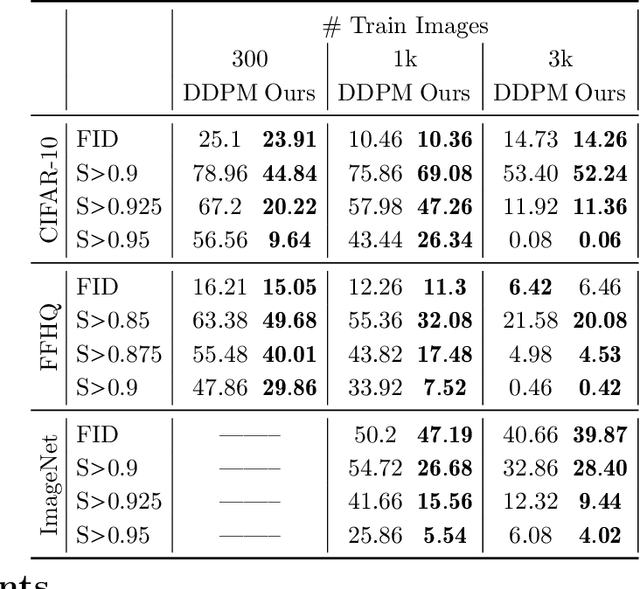

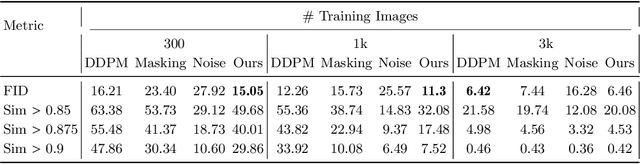
There is strong empirical evidence that the state-of-the-art diffusion modeling paradigm leads to models that memorize the training set, especially when the training set is small. Prior methods to mitigate the memorization problem often lead to a decrease in image quality. Is it possible to obtain strong and creative generative models, i.e., models that achieve high generation quality and low memorization? Despite the current pessimistic landscape of results, we make significant progress in pushing the trade-off between fidelity and memorization. We first provide theoretical evidence that memorization in diffusion models is only necessary for denoising problems at low noise scales (usually used in generating high-frequency details). Using this theoretical insight, we propose a simple, principled method to train the diffusion models using noisy data at large noise scales. We show that our method significantly reduces memorization without decreasing the image quality, for both text-conditional and unconditional models and for a variety of data availability settings.
Train for the Worst, Plan for the Best: Understanding Token Ordering in Masked Diffusions
Feb 10, 2025In recent years, masked diffusion models (MDMs) have emerged as a promising alternative approach for generative modeling over discrete domains. Compared to autoregressive models (ARMs), MDMs trade off complexity at training time with flexibility at inference time. At training time, they must learn to solve an exponentially large number of infilling problems, but at inference time, they can decode tokens in essentially arbitrary order. In this work, we closely examine these two competing effects. On the training front, we theoretically and empirically demonstrate that MDMs indeed train on computationally intractable subproblems compared to their autoregressive counterparts. On the inference front, we show that a suitable strategy for adaptively choosing the token decoding order significantly enhances the capabilities of MDMs, allowing them to sidestep hard subproblems. On logic puzzles like Sudoku, we show that adaptive inference can boost solving accuracy in pretrained MDMs from $<7$% to $\approx 90$%, even outperforming ARMs with $7\times$ as many parameters and that were explicitly trained via teacher forcing to learn the right order of decoding.
Causal Language Modeling Can Elicit Search and Reasoning Capabilities on Logic Puzzles
Sep 16, 2024



Causal language modeling using the Transformer architecture has yielded remarkable capabilities in Large Language Models (LLMs) over the last few years. However, the extent to which fundamental search and reasoning capabilities emerged within LLMs remains a topic of ongoing debate. In this work, we study if causal language modeling can learn a complex task such as solving Sudoku puzzles. To solve a Sudoku, the model is first required to search over all empty cells of the puzzle to decide on a cell to fill and then apply an appropriate strategy to fill the decided cell. Sometimes, the application of a strategy only results in thinning down the possible values in a cell rather than concluding the exact value of the cell. In such cases, multiple strategies are applied one after the other to fill a single cell. We observe that Transformer models trained on this synthetic task can indeed learn to solve Sudokus (our model solves $94.21\%$ of the puzzles fully correctly) when trained on a logical sequence of steps taken by a solver. We find that training Transformers with the logical sequence of steps is necessary and without such training, they fail to learn Sudoku. We also extend our analysis to Zebra puzzles (known as Einstein puzzles) and show that the model solves $92.04 \%$ of the puzzles fully correctly. In addition, we study the internal representations of the trained Transformer and find that through linear probing, we can decode information about the set of possible values in any given cell from them, pointing to the presence of a strong reasoning engine implicit in the Transformer weights.
Learning general Gaussian mixtures with efficient score matching
Apr 29, 2024
We study the problem of learning mixtures of $k$ Gaussians in $d$ dimensions. We make no separation assumptions on the underlying mixture components: we only require that the covariance matrices have bounded condition number and that the means and covariances lie in a ball of bounded radius. We give an algorithm that draws $d^{\mathrm{poly}(k/\varepsilon)}$ samples from the target mixture, runs in sample-polynomial time, and constructs a sampler whose output distribution is $\varepsilon$-far from the unknown mixture in total variation. Prior works for this problem either (i) required exponential runtime in the dimension $d$, (ii) placed strong assumptions on the instance (e.g., spherical covariances or clusterability), or (iii) had doubly exponential dependence on the number of components $k$. Our approach departs from commonly used techniques for this problem like the method of moments. Instead, we leverage a recently developed reduction, based on diffusion models, from distribution learning to a supervised learning task called score matching. We give an algorithm for the latter by proving a structural result showing that the score function of a Gaussian mixture can be approximated by a piecewise-polynomial function, and there is an efficient algorithm for finding it. To our knowledge, this is the first example of diffusion models achieving a state-of-the-art theoretical guarantee for an unsupervised learning task.
Simple Mechanisms for Representing, Indexing and Manipulating Concepts
Oct 18, 2023

Deep networks typically learn concepts via classifiers, which involves setting up a model and training it via gradient descent to fit the concept-labeled data. We will argue instead that learning a concept could be done by looking at its moment statistics matrix to generate a concrete representation or signature of that concept. These signatures can be used to discover structure across the set of concepts and could recursively produce higher-level concepts by learning this structure from those signatures. When the concepts are `intersected', signatures of the concepts can be used to find a common theme across a number of related `intersected' concepts. This process could be used to keep a dictionary of concepts so that inputs could correctly identify and be routed to the set of concepts involved in the (latent) generation of the input.
Learning Mixtures of Gaussians Using the DDPM Objective
Jul 03, 2023Recent works have shown that diffusion models can learn essentially any distribution provided one can perform score estimation. Yet it remains poorly understood under what settings score estimation is possible, let alone when practical gradient-based algorithms for this task can provably succeed. In this work, we give the first provably efficient results along these lines for one of the most fundamental distribution families, Gaussian mixture models. We prove that gradient descent on the denoising diffusion probabilistic model (DDPM) objective can efficiently recover the ground truth parameters of the mixture model in the following two settings: 1) We show gradient descent with random initialization learns mixtures of two spherical Gaussians in $d$ dimensions with $1/\text{poly}(d)$-separated centers. 2) We show gradient descent with a warm start learns mixtures of $K$ spherical Gaussians with $\Omega(\sqrt{\log(\min(K,d))})$-separated centers. A key ingredient in our proofs is a new connection between score-based methods and two other approaches to distribution learning, the EM algorithm and spectral methods.
Ambient Diffusion: Learning Clean Distributions from Corrupted Data
May 30, 2023



We present the first diffusion-based framework that can learn an unknown distribution using only highly-corrupted samples. This problem arises in scientific applications where access to uncorrupted samples is impossible or expensive to acquire. Another benefit of our approach is the ability to train generative models that are less likely to memorize individual training samples since they never observe clean training data. Our main idea is to introduce additional measurement distortion during the diffusion process and require the model to predict the original corrupted image from the further corrupted image. We prove that our method leads to models that learn the conditional expectation of the full uncorrupted image given this additional measurement corruption. This holds for any corruption process that satisfies some technical conditions (and in particular includes inpainting and compressed sensing). We train models on standard benchmarks (CelebA, CIFAR-10 and AFHQ) and show that we can learn the distribution even when all the training samples have $90\%$ of their pixels missing. We also show that we can finetune foundation models on small corrupted datasets (e.g. MRI scans with block corruptions) and learn the clean distribution without memorizing the training set.
RISAN: Robust Instance Specific Abstention Network
Jul 07, 2021


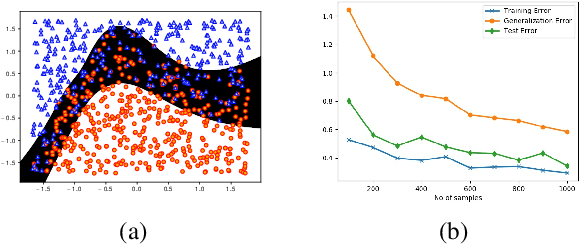
In this paper, we propose deep architectures for learning instance specific abstain (reject option) binary classifiers. The proposed approach uses double sigmoid loss function as described by Kulin Shah and Naresh Manwani in ("Online Active Learning of Reject Option Classifiers", AAAI, 2020), as a performance measure. We show that the double sigmoid loss is classification calibrated. We also show that the excess risk of 0-d-1 loss is upper bounded by the excess risk of double sigmoid loss. We derive the generalization error bounds for the proposed architecture for reject option classifiers. To show the effectiveness of the proposed approach, we experiment with several real world datasets. We observe that the proposed approach not only performs comparable to the state-of-the-art approaches, it is also robust against label noise. We also provide visualizations to observe the important features learned by the network corresponding to the abstaining decision.