 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Generation Require Memorization? Creative Diffusion Models using Ambient Diffusion
Paper and Code
Feb 28, 2025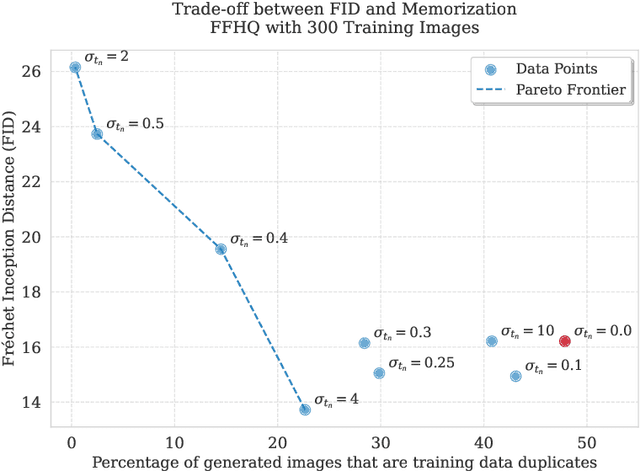
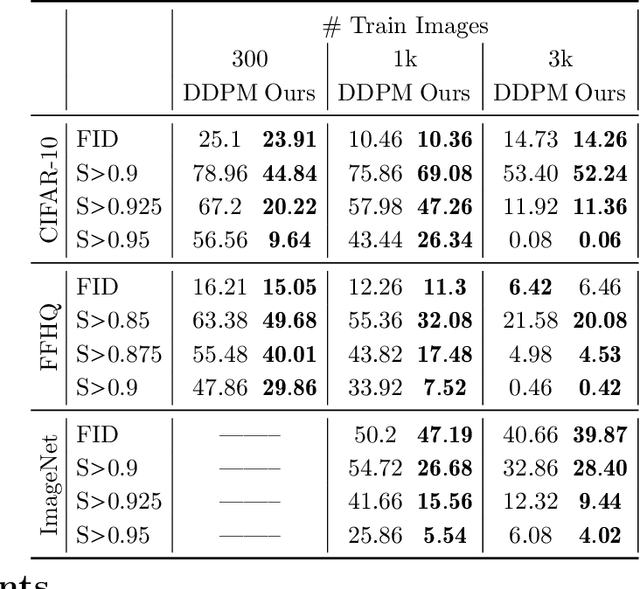

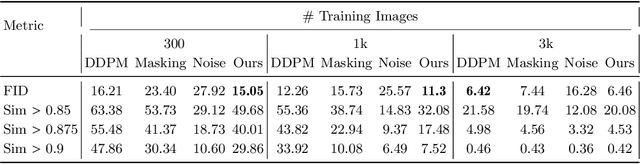
There is strong empirical evidence that the state-of-the-art diffusion modeling paradigm leads to models that memorize the training set, especially when the training set is small. Prior methods to mitigate the memorization problem often lead to a decrease in image quality. Is it possible to obtain strong and creative generative models, i.e., models that achieve high generation quality and low memorization? Despite the current pessimistic landscape of results, we make significant progress in pushing the trade-off between fidelity and memorization. We first provide theoretical evidence that memorization in diffusion models is only necessary for denoising problems at low noise scales (usually used in generating high-frequency details). Using this theoretical insight, we propose a simple, principled method to train the diffusion models using noisy data at large noise scales. We show that our method significantly reduces memorization without decreasing the image quality, for both text-conditional and unconditional models and for a variety of data availability settings.