 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdgeMask-DG*: Learning Domain-Invariant Graph Structures via Adversarial Edge Masking
Feb 05, 2026Structural shifts pose a significant challenge for graph neural networks, as graph topology acts as a covariate that can vary across domains. Existing domain generalization methods rely on fixed structural augmentations or training on globally perturbed graphs, mechanisms that do not pinpoint which specific edges encode domain-invariant information. We argue that domain-invariant structural information is not rigidly tied to a single topology but resides in the consensus across multiple graph structures derived from topology and feature similarity. To capture this, we first propose EdgeMask-DG, a novel min-max algorithm where an edge masker learns to find worst-case continuous masks subject to a sparsity constraint, compelling a task GNN to perform effectively under these adversarial structural perturbations. Building upon this, we introduce EdgeMask-DG*, an extension that applies this adversarial masking principle to an enriched graph. This enriched graph combines the original topology with feature-derived edges, allowing the model to discover invariances even when the original topology is noisy or domain-specific. EdgeMask-DG* is the first to systematically combine adaptive adversarial topology search with feature-enriched graphs. We provide a formal justification for our approach from a robust optimization perspective. We demonstrate that EdgeMask-DG* achieves new state-of-the-art performance on diverse graph domain generalization benchmarks, including citation networks, social networks, and temporal graphs. Notably, on the Cora OOD benchmark, EdgeMask-DG* lifts the worst-case domain accuracy to 78.0\%, a +3.8 pp improvement over the prior state of the art (74.2\%). The source code for our experiments can be found here: https://anonymous.4open.science/r/TMLR-EAEF/
DFORD: Directional Feedback based Online Ordinal Regression Learning
Dec 22, 2025In this paper, we introduce directional feedback in the ordinal regression setting, in which the learner receives feedback on whether the predicted label is on the left or the right side of the actual label. This is a weak supervision setting for ordinal regression compared to the full information setting, where the learner can access the labels. We propose an online algorithm for ordinal regression using directional feedback. The proposed algorithm uses an exploration-exploitation scheme to learn from directional feedback efficiently. Furthermore, we introduce its kernel-based variant to learn non-linear ordinal regression models in an online setting. We use a truncation trick to make the kernel implementation more memory efficient. The proposed algorithm maintains the ordering of the thresholds in the expected sense. Moreover, it achieves the expected regret of $\mathcal{O}(\log T)$. We compare our approach with a full information and a weakly supervised algorithm for ordinal regression on synthetic and real-world datasets. The proposed approach, which learns using directional feedback, performs comparably (sometimes better) to its full information counterpart.
Robust Object Detection with Pseudo Labels from VLMs using Per-Object Co-teaching
Nov 13, 2025



Foundation models, especially vision-language models (VLMs), offer compelling zero-shot object detection for applications like autonomous driving, a domain where manual labelling is prohibitively expensive. However, their detection latency and tendency to hallucinate predictions render them unsuitable for direct deployment. This work introduces a novel pipeline that addresses this challenge by leveraging VLMs to automatically generate pseudo-labels for training efficient, real-time object detectors. Our key innovation is a per-object co-teaching-based training strategy that mitigates the inherent noise in VLM-generated labels. The proposed per-object coteaching approach filters noisy bounding boxes from training instead of filtering the entire image. Specifically, two YOLO models learn collaboratively, filtering out unreliable boxes from each mini-batch based on their peers' per-object loss values. Overall, our pipeline provides an efficient, robust, and scalable approach to train high-performance object detectors for autonomous driving, significantly reducing reliance on costly human annotation. Experimental results on the KITTI dataset demonstrate that our method outperforms a baseline YOLOv5m model, achieving a significant mAP@0.5 boost ($31.12\%$ to $46.61\%$) while maintaining real-time detection latency. Furthermore, we show that supplementing our pseudo-labelled data with a small fraction of ground truth labels ($10\%$) leads to further performance gains, reaching $57.97\%$ mAP@0.5 on the KITTI dataset. We observe similar performance improvements for the ACDC and BDD100k datasets.
Achieving Fair PCA Using Joint Eigenvalue Decomposition
Feb 24, 2025Principal Component Analysis (PCA) is a widely used method for dimensionality reduction, but it often overlooks fairness, especially when working with data that includes demographic characteristics. This can lead to biased representations that disproportionately affect certain groups. To address this issue, our approach incorporates Joint Eigenvalue Decomposition (JEVD), a technique that enables the simultaneous diagonalization of multiple matrices, ensuring fair and efficient representations. We formally show that the optimal solution of JEVD leads to a fair PCA solution. By integrating JEVD with PCA, we strike an optimal balance between preserving data structure and promoting fairness across diverse groups. We demonstrate that our method outperforms existing baseline approaches in fairness and representational quality on various datasets. It retains the core advantages of PCA while ensuring that sensitive demographic attributes do not create disparities in the reduced representation.
Optimal Strategies for Federated Learning Maintaining Client Privacy
Jan 24, 2025



Federated Learning (FL) emerged as a learning method to enable the server to train models over data distributed among various clients. These clients are protective about their data being leaked to the server, any other client, or an external adversary, and hence, locally train the model and share it with the server rather than sharing the data. The introduction of sophisticated inferencing attacks enabled the leakage of information about data through access to model parameters. To tackle this challenge, privacy-preserving federated learning aims to achieve differential privacy through learning algorithms like DP-SGD. However, such methods involve adding noise to the model, data, or gradients, reducing the model's performance. This work provides a theoretical analysis of the tradeoff between model performance and communication complexity of the FL system. We formally prove that training for one local epoch per global round of training gives optimal performance while preserving the same privacy budget. We also investigate the change of utility (tied to privacy) of FL models with a change in the number of clients and observe that when clients are training using DP-SGD and argue that for the same privacy budget, the utility improved with increased clients. We validate our findings through experiments on real-world datasets. The results from this paper aim to improve the performance of privacy-preserving federated learning systems.
Predict Confidently, Predict Right: Abstention in Dynamic Graph Learning
Jan 14, 2025Many real-world systems can be modeled as dynamic graphs, where nodes and edges evolve over time, requiring specialized models to capture their evolving dynamics in risk-sensitive applications effectively. Temporal graph neural networks (GNNs) are one such category of specialized models. For the first time, our approach integrates a reject option strategy within the framework of GNNs for continuous-time dynamic graphs. This allows the model to strategically abstain from making predictions when the uncertainty is high and confidence is low, thus minimizing the risk of critical misclassification and enhancing the results and reliability. We propose a coverage-based abstention prediction model to implement the reject option that maximizes prediction within a specified coverage. It improves the prediction score for link prediction and node classification tasks. Temporal GNNs deal with extremely skewed datasets for the next state prediction or node classification task. In the case of class imbalance, our method can be further tuned to provide a higher weightage to the minority class. Exhaustive experiments are presented on four datasets for dynamic link prediction and two datasets for dynamic node classification tasks. This demonstrates the effectiveness of our approach in improving the reliability and area under the curve (AUC)/ average precision (AP) scores for predictions in dynamic graph scenarios. The results highlight our model's ability to efficiently handle the trade-offs between prediction confidence and coverage, making it a dependable solution for applications requiring high precision in dynamic and uncertain environments.
Node Classification With Integrated Reject Option
Dec 04, 2024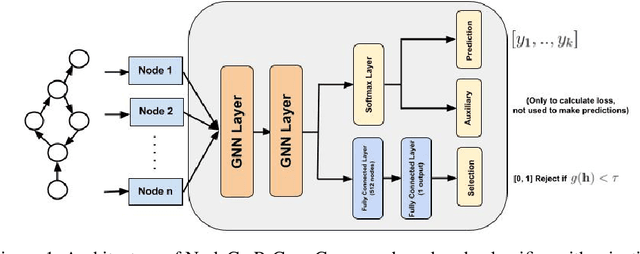
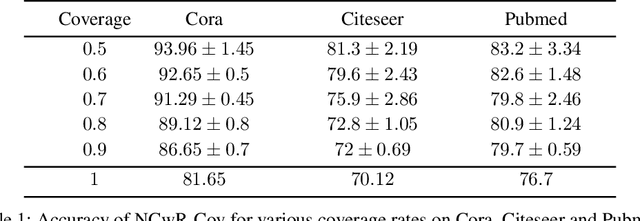
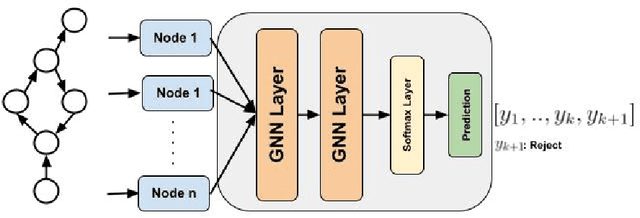
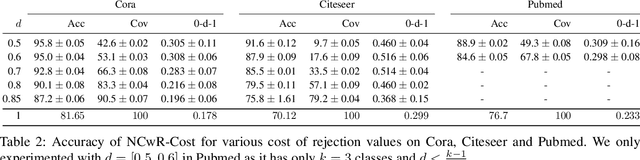
One of the key tasks in graph learning is node classification. While Graph neural networks have been used for various applications, their adaptivity to reject option setting is not previously explored. In this paper, we propose NCwR, a novel approach to node classification in Graph Neural Networks (GNNs) with an integrated reject option, which allows the model to abstain from making predictions when uncertainty is high. We propose both cost-based and coverage-based methods for classification with abstention in node classification setting using GNNs. We perform experiments using our method on three standard citation network datasets Cora, Citeseer and Pubmed and compare with relevant baselines. We also model the Legal judgment prediction problem on ILDC dataset as a node classification problem where nodes represent legal cases and edges represent citations. We further interpret the model by analyzing the cases that the model abstains from predicting by visualizing which part of the input features influenced this decision.
ILAEDA: An Imitation Learning Based Approach for Automatic Exploratory Data Analysis
Oct 15, 2024



Automating end-to-end Exploratory Data Analysis (AutoEDA) is a challenging open problem, often tackled through Reinforcement Learning (RL) by learning to predict a sequence of analysis operations (FILTER, GROUP, etc). Defining rewards for each operation is a challenging task and existing methods rely on various \emph{interestingness measures} to craft reward functions to capture the importance of each operation. In this work, we argue that not all of the essential features of what makes an operation important can be accurately captured mathematically using rewards. We propose an AutoEDA model trained through imitation learning from expert EDA sessions, bypassing the need for manually defined interestingness measures. Our method, based on generative adversarial imitation learning (GAIL), generalizes well across datasets, even with limited expert data. We also introduce a novel approach for generating synthetic EDA demonstrations for training. Our method outperforms the existing state-of-the-art end-to-end EDA approach on benchmarks by upto 3x, showing strong performance and generalization, while naturally capturing diverse interestingness measures in generated EDA sessions.
Towards Calibrated Losses for Adversarial Robust Reject Option Classification
Oct 14, 2024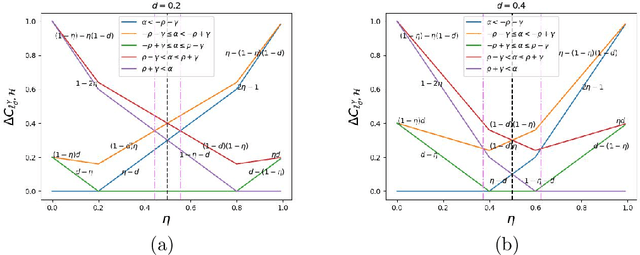
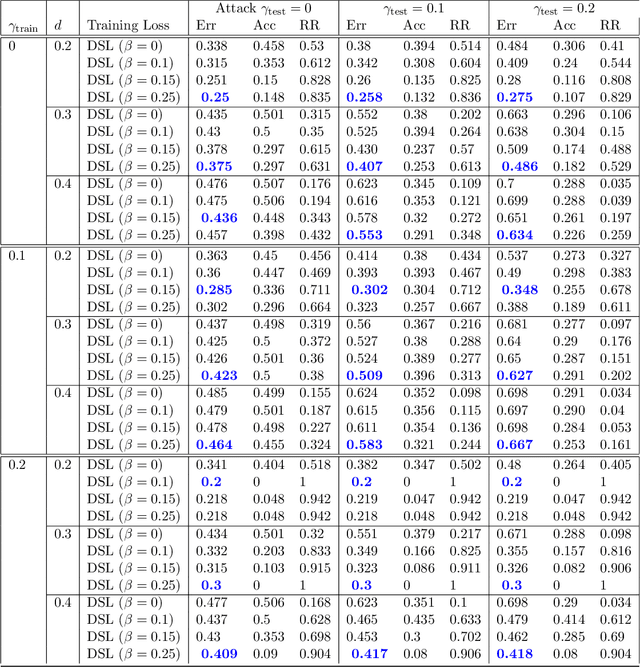
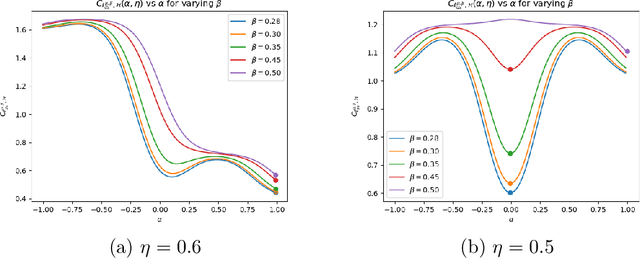
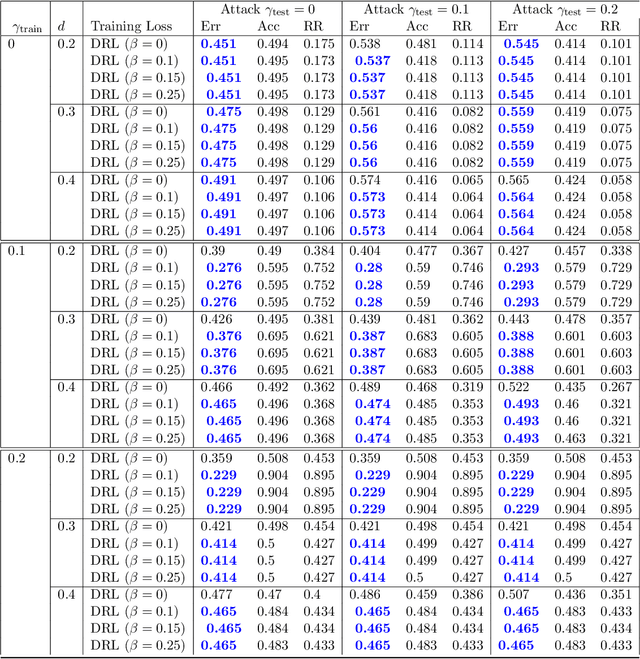
Robustness towards adversarial attacks is a vital property for classifiers in several applications such as autonomous driving, medical diagnosis, etc. Also, in such scenarios, where the cost of misclassification is very high, knowing when to abstain from prediction becomes crucial. A natural question is which surrogates can be used to ensure learning in scenarios where the input points are adversarially perturbed and the classifier can abstain from prediction? This paper aims to characterize and design surrogates calibrated in "Adversarial Robust Reject Option" setting. First, we propose an adversarial robust reject option loss $\ell_{d}^{\gamma}$ and analyze it for the hypothesis set of linear classifiers ($\mathcal{H}_{\textrm{lin}}$). Next, we provide a complete characterization result for any surrogate to be $(\ell_{d}^{\gamma},\mathcal{H}_{\textrm{lin}})$- calibrated. To demonstrate the difficulty in designing surrogates to $\ell_{d}^{\gamma}$, we show negative calibration results for convex surrogates and quasi-concave conditional risk cases (these gave positive calibration in adversarial setting without reject option). We also empirically argue that Shifted Double Ramp Loss (DRL) and Shifted Double Sigmoid Loss (DSL) satisfy the calibration conditions. Finally, we demonstrate the robustness of shifted DRL and shifted DSL against adversarial perturbations on a synthetically generated dataset.
SARI: Simplistic Average and Robust Identification based Noisy Partial Label Learning
Feb 07, 2024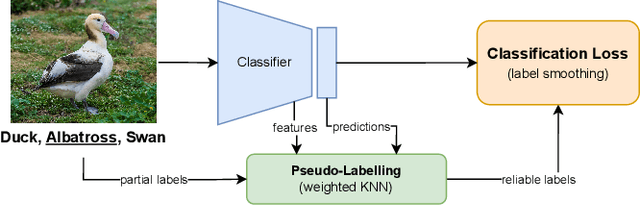

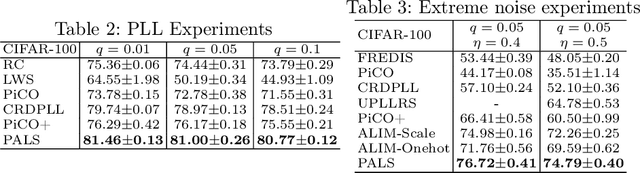

Partial label learning (PLL) is a weakly-supervised learning paradigm where each training instance is paired with a set of candidate labels (partial label), one of which is the true label. Noisy PLL (NPLL) relaxes this constraint by allowing some partial labels to not contain the true label, enhancing the practicality of the problem. Our work centers on NPLL and presents a minimalistic framework called SARI that initially assigns pseudo-labels to images by exploiting the noisy partial labels through a weighted nearest neighbour algorithm. These pseudo-label and image pairs are then used to train a deep neural network classifier with label smoothing and standard regularization techniques. The classifier's features and predictions are subsequently employed to refine and enhance the accuracy of pseudo-labels. SARI combines the strengths of Average Based Strategies (in pseudo labelling) and Identification Based Strategies (in classifier training) from the literature. We perform thorough experiments on seven datasets and compare SARI against nine NPLL and PLL methods from the prior art. SARI achieves state-of-the-art results in almost all studied settings, obtaining substantial gains in fine-grained classification and extreme noise settings.