 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeILAEDA: An Imitation Learning Based Approach for Automatic Exploratory Data Analysis
Oct 15, 2024



Automating end-to-end Exploratory Data Analysis (AutoEDA) is a challenging open problem, often tackled through Reinforcement Learning (RL) by learning to predict a sequence of analysis operations (FILTER, GROUP, etc). Defining rewards for each operation is a challenging task and existing methods rely on various \emph{interestingness measures} to craft reward functions to capture the importance of each operation. In this work, we argue that not all of the essential features of what makes an operation important can be accurately captured mathematically using rewards. We propose an AutoEDA model trained through imitation learning from expert EDA sessions, bypassing the need for manually defined interestingness measures. Our method, based on generative adversarial imitation learning (GAIL), generalizes well across datasets, even with limited expert data. We also introduce a novel approach for generating synthetic EDA demonstrations for training. Our method outperforms the existing state-of-the-art end-to-end EDA approach on benchmarks by upto 3x, showing strong performance and generalization, while naturally capturing diverse interestingness measures in generated EDA sessions.
Comparative analysis of segmentation and generative models for fingerprint retrieval task
Sep 13, 2022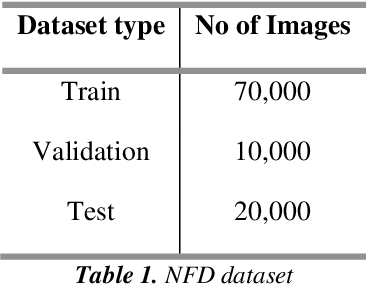
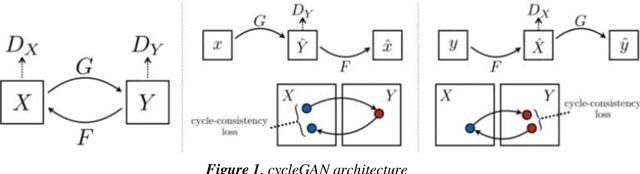
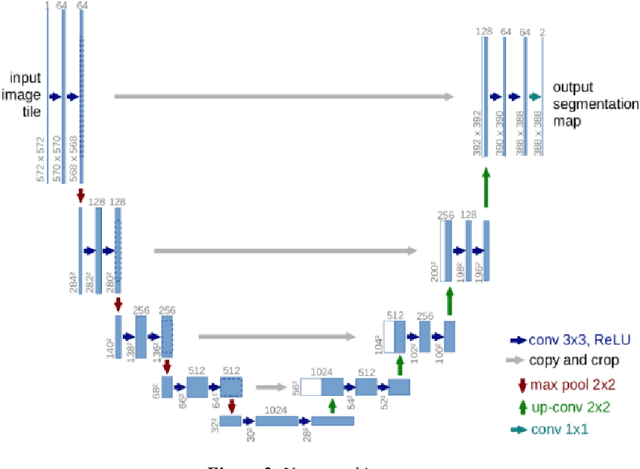
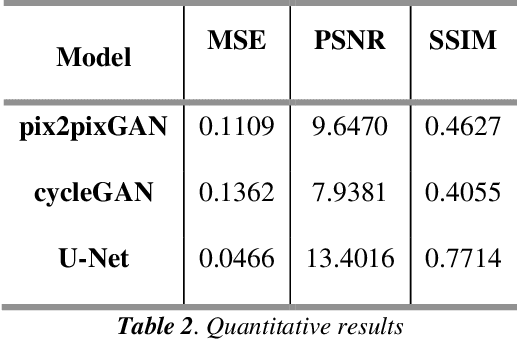
Biometric Authentication like Fingerprints has become an integral part of the modern technology for authentication and verification of users. It is pervasive in more ways than most of us are aware of. However, these fingerprint images deteriorate in quality if the fingers are dirty, wet, injured or when sensors malfunction. Therefore, extricating the original fingerprint by removing the noise and inpainting it to restructure the image is crucial for its authentication. Hence, this paper proposes a deep learning approach to address these issues using Generative (GAN) and Segmentation models. Qualitative and Quantitative comparison has been done between pix2pixGAN and cycleGAN (generative models) as well as U-net (segmentation model). To train the model, we created our own dataset NFD - Noisy Fingerprint Dataset meticulously with different backgrounds along with scratches in some images to make it more realistic and robust. In our research, the u-net model performed better than the GAN networks
Application of image-to-image translation in improving pedestrian detection
Sep 08, 2022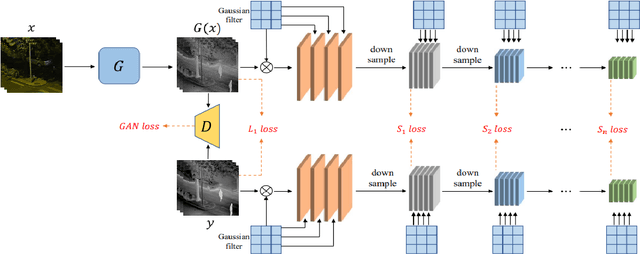
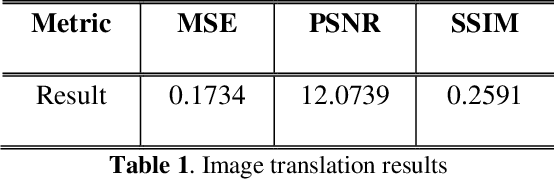

The lack of effective target regions makes it difficult to perform several visual functions in low intensity light, including pedestrian recognition, and image-to-image translation. In this situation, with the accumulation of high-quality information by the combined use of infrared and visible images it is possible to detect pedestrians even in low light. In this study we are going to use advanced deep learning models like pix2pixGAN and YOLOv7 on LLVIP dataset, containing visible-infrared image pairs for low light vision. This dataset contains 33672 images and most of the images were captured in dark scenes, tightly synchronized with time and location.