 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCIFE: Code Instruction-Following Evaluation
Dec 19, 2025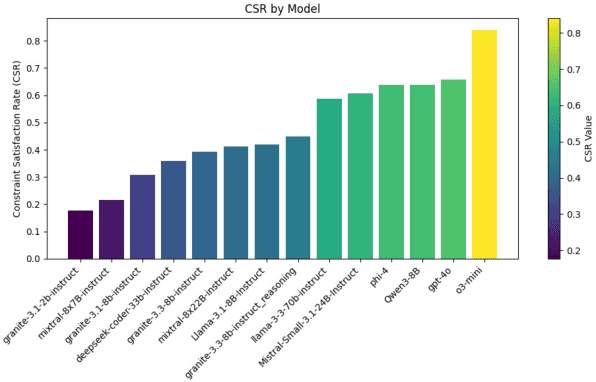
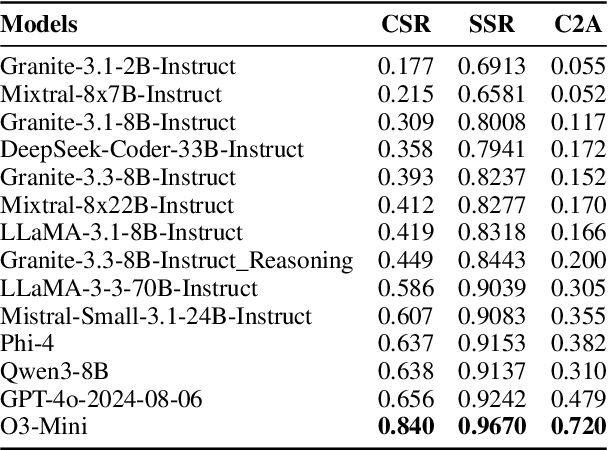
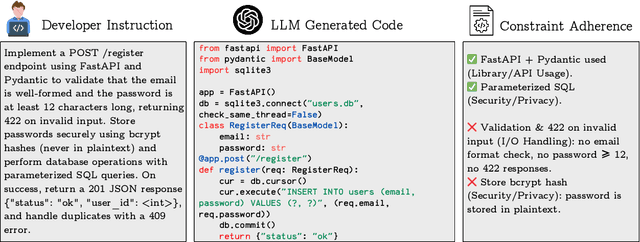

Large Language Models (LLMs) are increasingly applied to real-world code generation, where functional correctness alone is insufficient for reliable deployment, developers also expect adherence to explicit requirements for robustness, formatting, and security. Existing benchmarks primarily assess correctness through test-case execution, offering limited insight into how reliably models follow such constraints. We introduce a benchmark of 1,000 Python tasks, each paired with an average of 7 developer-specified constraints spanning 13 categories. Constraints are curated through a four-stage human-LLM pipeline to ensure they are atomic, relevant, and objective. We evaluate 14 open- and closed-source models using complementary adherence metrics and propose the C2A Score, a composite measure that jointly captures correctness and constraint compliance. Results reveal a substantial gap between partial and strict satisfaction, while strong models achieve over 90% partial adherence, strict adherence remains between 39-66%. These findings highlight that trustworthy code generation requires not only correctness but also consistent adherence to developer intent.
LLM-Aided Customizable Profiling of Code Data Based On Programming Language Concepts
Mar 19, 2025



Data profiling is critical in machine learning for generating descriptive statistics, supporting both deeper understanding and downstream tasks like data valuation and curation. This work addresses profiling specifically in the context of code datasets for Large Language Models (code-LLMs), where data quality directly influences tasks such as code generation and summarization. Characterizing code datasets in terms of programming language concepts enables better insights and targeted data curation. Our proposed methodology decomposes code data profiling into two phases: (1) an offline phase where LLMs are leveraged to derive and learn rules for extracting syntactic and semantic concepts across various programming languages, including previously unseen or low-resource languages, and (2) an online deterministic phase applying these derived rules for efficient real-time analysis. This hybrid approach is customizable, extensible to new syntactic and semantic constructs, and scalable to multiple languages. Experimentally, our LLM-aided method achieves a mean accuracy of 90.33% for syntactic extraction rules and semantic classification accuracies averaging 80% and 77% across languages and semantic concepts, respectively.
ILAEDA: An Imitation Learning Based Approach for Automatic Exploratory Data Analysis
Oct 15, 2024



Automating end-to-end Exploratory Data Analysis (AutoEDA) is a challenging open problem, often tackled through Reinforcement Learning (RL) by learning to predict a sequence of analysis operations (FILTER, GROUP, etc). Defining rewards for each operation is a challenging task and existing methods rely on various \emph{interestingness measures} to craft reward functions to capture the importance of each operation. In this work, we argue that not all of the essential features of what makes an operation important can be accurately captured mathematically using rewards. We propose an AutoEDA model trained through imitation learning from expert EDA sessions, bypassing the need for manually defined interestingness measures. Our method, based on generative adversarial imitation learning (GAIL), generalizes well across datasets, even with limited expert data. We also introduce a novel approach for generating synthetic EDA demonstrations for training. Our method outperforms the existing state-of-the-art end-to-end EDA approach on benchmarks by upto 3x, showing strong performance and generalization, while naturally capturing diverse interestingness measures in generated EDA sessions.
Data-Prep-Kit: getting your data ready for LLM application development
Sep 26, 2024



Data preparation is the first and a very important step towards any Large Language Model (LLM) development. This paper introduces an easy-to-use, extensible, and scale-flexible open-source data preparation toolkit called Data Prep Kit (DPK). DPK is architected and designed to enable users to scale their data preparation to their needs. With DPK they can prepare data on a local machine or effortlessly scale to run on a cluster with thousands of CPU Cores. DPK comes with a highly scalable, yet extensible set of modules that transform natural language and code data. If the user needs additional transforms, they can be easily developed using extensive DPK support for transform creation. These modules can be used independently or pipelined to perform a series of operations. In this paper, we describe DPK architecture and show its performance from a small scale to a very large number of CPUs. The modules from DPK have been used for the preparation of Granite Models [1] [2]. We believe DPK is a valuable contribution to the AI community to easily prepare data to enhance the performance of their LLM models or to fine-tune models with Retrieval-Augmented Generation (RAG).
Scaling Granite Code Models to 128K Context
Jul 18, 2024This paper introduces long-context Granite code models that support effective context windows of up to 128K tokens. Our solution for scaling context length of Granite 3B/8B code models from 2K/4K to 128K consists of a light-weight continual pretraining by gradually increasing its RoPE base frequency with repository-level file packing and length-upsampled long-context data. Additionally, we also release instruction-tuned models with long-context support which are derived by further finetuning the long context base models on a mix of permissively licensed short and long-context instruction-response pairs. While comparing to the original short-context Granite code models, our long-context models achieve significant improvements on long-context tasks without any noticeable performance degradation on regular code completion benchmarks (e.g., HumanEval). We release all our long-context Granite code models under an Apache 2.0 license for both research and commercial use.
An Automatic Prompt Generation System for Tabular Data Tasks
May 09, 2024



Efficient processing of tabular data is important in various industries, especially when working with datasets containing a large number of columns. Large language models (LLMs) have demonstrated their ability on several tasks through carefully crafted prompts. However, creating effective prompts for tabular datasets is challenging due to the structured nature of the data and the need to manage numerous columns. This paper presents an innovative auto-prompt generation system suitable for multiple LLMs, with minimal training. It proposes two novel methods; 1) A Reinforcement Learning-based algorithm for identifying and sequencing task-relevant columns 2) Cell-level similarity-based approach for enhancing few-shot example selection. Our approach has been extensively tested across 66 datasets, demonstrating improved performance in three downstream tasks: data imputation, error detection, and entity matching using two distinct LLMs; Google flan-t5-xxl and Mixtral 8x7B.
Granite Code Models: A Family of Open Foundation Models for Code Intelligence
May 07, 2024



Large Language Models (LLMs) trained on code are revolutionizing the software development process. Increasingly, code LLMs are being integrated into software development environments to improve the productivity of human programmers, and LLM-based agents are beginning to show promise for handling complex tasks autonomously. Realizing the full potential of code LLMs requires a wide range of capabilities, including code generation, fixing bugs, explaining and documenting code, maintaining repositories, and more. In this work, we introduce the Granite series of decoder-only code models for code generative tasks, trained with code written in 116 programming languages. The Granite Code models family consists of models ranging in size from 3 to 34 billion parameters, suitable for applications ranging from complex application modernization tasks to on-device memory-constrained use cases. Evaluation on a comprehensive set of tasks demonstrates that Granite Code models consistently reaches state-of-the-art performance among available open-source code LLMs. The Granite Code model family was optimized for enterprise software development workflows and performs well across a range of coding tasks (e.g. code generation, fixing and explanation), making it a versatile all around code model. We release all our Granite Code models under an Apache 2.0 license for both research and commercial use.
xLP: Explainable Link Prediction for Master Data Management
Mar 14, 2024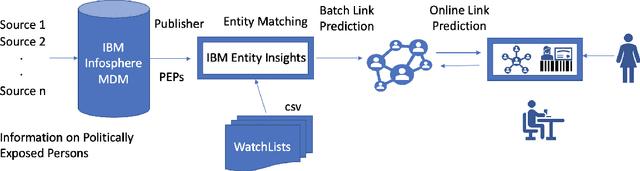
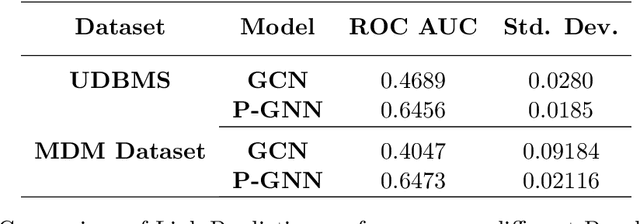
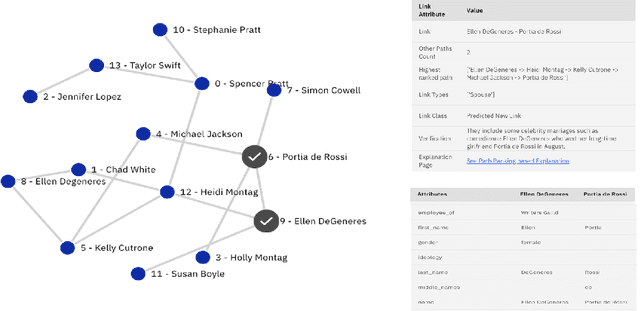

Explaining neural model predictions to users requires creativity. Especially in enterprise applications, where there are costs associated with users' time, and their trust in the model predictions is critical for adoption. For link prediction in master data management, we have built a number of explainability solutions drawing from research in interpretability, fact verification, path ranking, neuro-symbolic reasoning and self-explaining AI. In this demo, we present explanations for link prediction in a creative way, to allow users to choose explanations they are more comfortable with.
Multi-Intent Detection in User Provided Annotations for Programming by Examples Systems
Jul 08, 2023



In mapping enterprise applications, data mapping remains a fundamental part of integration development, but its time consuming. An increasing number of applications lack naming standards, and nested field structures further add complexity for the integration developers. Once the mapping is done, data transformation is the next challenge for the users since each application expects data to be in a certain format. Also, while building integration flow, developers need to understand the format of the source and target data field and come up with transformation program that can change data from source to target format. The problem of automatic generation of a transformation program through program synthesis paradigm from some specifications has been studied since the early days of Artificial Intelligence (AI). Programming by Example (PBE) is one such kind of technique that targets automatic inferencing of a computer program to accomplish a format or string conversion task from user-provided input and output samples. To learn the correct intent, a diverse set of samples from the user is required. However, there is a possibility that the user fails to provide a diverse set of samples. This can lead to multiple intents or ambiguity in the input and output samples. Hence, PBE systems can get confused in generating the correct intent program. In this paper, we propose a deep neural network based ambiguity prediction model, which analyzes the input-output strings and maps them to a different set of properties responsible for multiple intent. Users can analyze these properties and accordingly can provide new samples or modify existing samples which can help in building a better PBE system for mapping enterprise applications.
Identifying Semantically Difficult Samples to Improve Text Classification
Feb 13, 2023
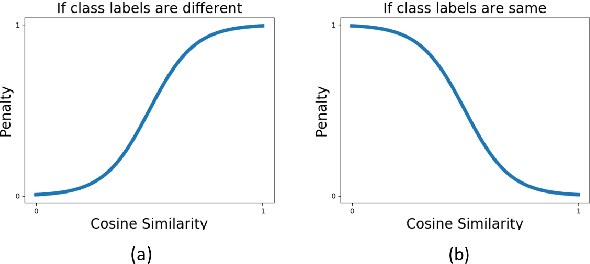
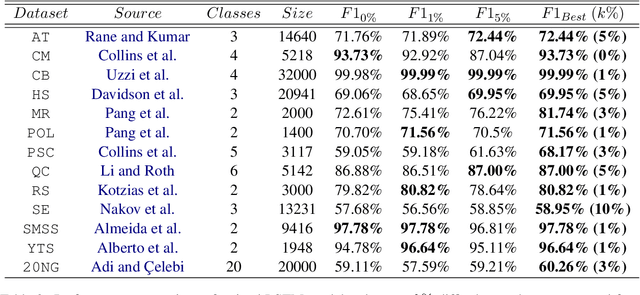

In this paper, we investigate the effect of addressing difficult samples from a given text dataset on the downstream text classification task. We define difficult samples as being non-obvious cases for text classification by analysing them in the semantic embedding space; specifically - (i) semantically similar samples that belong to different classes and (ii) semantically dissimilar samples that belong to the same class. We propose a penalty function to measure the overall difficulty score of every sample in the dataset. We conduct exhaustive experiments on 13 standard datasets to show a consistent improvement of up to 9% and discuss qualitative results to show effectiveness of our approach in identifying difficult samples for a text classification model.