 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQUIS: Question-guided Insights Generation for Automated Exploratory Data Analysis
Oct 14, 2024Discovering meaningful insights from a large dataset, known as Exploratory Data Analysis (EDA), is a challenging task that requires thorough exploration and analysis of the data. Automated Data Exploration (ADE) systems use goal-oriented methods with Large Language Models and Reinforcement Learning towards full automation. However, these methods require human involvement to anticipate goals that may limit insight extraction, while fully automated systems demand significant computational resources and retraining for new datasets. We introduce QUIS, a fully automated EDA system that operates in two stages: insight generation (ISGen) driven by question generation (QUGen). The QUGen module generates questions in iterations, refining them from previous iterations to enhance coverage without human intervention or manually curated examples. The ISGen module analyzes data to produce multiple relevant insights in response to each question, requiring no prior training and enabling QUIS to adapt to new datasets.
An Automatic Prompt Generation System for Tabular Data Tasks
May 09, 2024



Efficient processing of tabular data is important in various industries, especially when working with datasets containing a large number of columns. Large language models (LLMs) have demonstrated their ability on several tasks through carefully crafted prompts. However, creating effective prompts for tabular datasets is challenging due to the structured nature of the data and the need to manage numerous columns. This paper presents an innovative auto-prompt generation system suitable for multiple LLMs, with minimal training. It proposes two novel methods; 1) A Reinforcement Learning-based algorithm for identifying and sequencing task-relevant columns 2) Cell-level similarity-based approach for enhancing few-shot example selection. Our approach has been extensively tested across 66 datasets, demonstrating improved performance in three downstream tasks: data imputation, error detection, and entity matching using two distinct LLMs; Google flan-t5-xxl and Mixtral 8x7B.
Deep hierarchical reinforcement agents for automated penetration testing
Sep 14, 2021
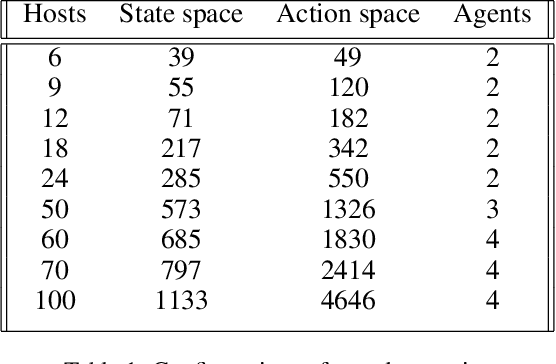

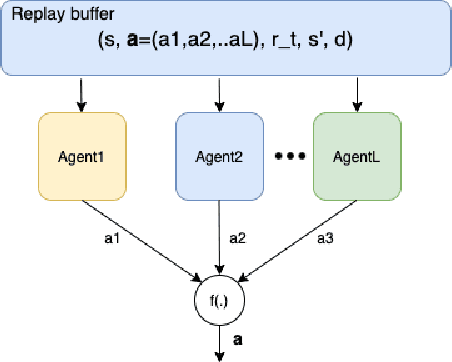
Penetration testing the organised attack of a computer system in order to test existing defences has been used extensively to evaluate network security. This is a time consuming process and requires in-depth knowledge for the establishment of a strategy that resembles a real cyber-attack. This paper presents a novel deep reinforcement learning architecture with hierarchically structured agents called HA-DRL, which employs an algebraic action decomposition strategy to address the large discrete action space of an autonomous penetration testing simulator where the number of actions is exponentially increased with the complexity of the designed cybersecurity network. The proposed architecture is shown to find the optimal attacking policy faster and more stably than a conventional deep Q-learning agent which is commonly used as a method to apply artificial intelligence in automatic penetration testing.