 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGneissWeb: Preparing High Quality Data for LLMs at Scale
Feb 19, 2025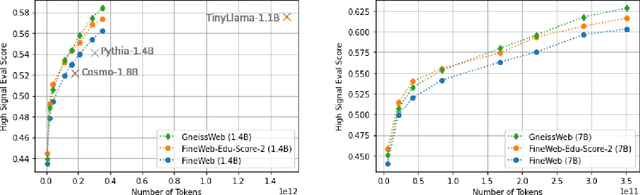
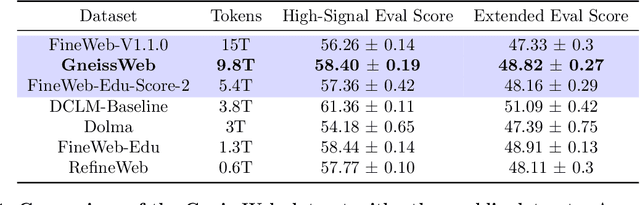
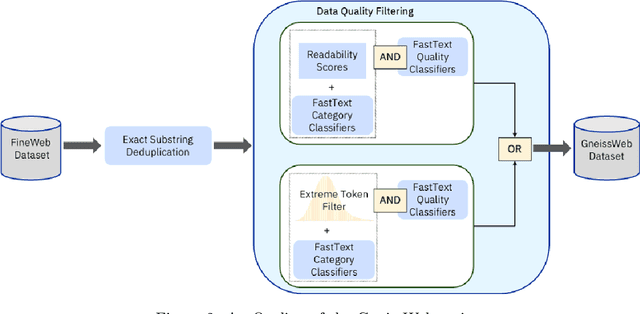

Data quantity and quality play a vital role in determining the performance of Large Language Models (LLMs). High-quality data, in particular, can significantly boost the LLM's ability to generalize on a wide range of downstream tasks. Large pre-training datasets for leading LLMs remain inaccessible to the public, whereas many open datasets are small in size (less than 5 trillion tokens), limiting their suitability for training large models. In this paper, we introduce GneissWeb, a large dataset yielding around 10 trillion tokens that caters to the data quality and quantity requirements of training LLMs. Our GneissWeb recipe that produced the dataset consists of sharded exact sub-string deduplication and a judiciously constructed ensemble of quality filters. GneissWeb achieves a favorable trade-off between data quality and quantity, producing models that outperform models trained on state-of-the-art open large datasets (5+ trillion tokens). We show that models trained using GneissWeb dataset outperform those trained on FineWeb-V1.1.0 by 2.73 percentage points in terms of average score computed on a set of 11 commonly used benchmarks (both zero-shot and few-shot) for pre-training dataset evaluation. When the evaluation set is extended to 20 benchmarks (both zero-shot and few-shot), models trained using GneissWeb still achieve a 1.75 percentage points advantage over those trained on FineWeb-V1.1.0.
Machine learning algorithms to predict the risk of rupture of intracranial aneurysms: a systematic review
Dec 06, 2024Purpose: Subarachnoid haemorrhage is a potentially fatal consequence of intracranial aneurysm rupture, however, it is difficult to predict if aneurysms will rupture. Prophylactic treatment of an intracranial aneurysm also involves risk, hence identifying rupture-prone aneurysms is of substantial clinical importance. This systematic review aims to evaluate the performance of machine learning algorithms for predicting intracranial aneurysm rupture risk. Methods: MEDLINE, Embase, Cochrane Library and Web of Science were searched until December 2023. Studies incorporating any machine learning algorithm to predict the risk of rupture of an intracranial aneurysm were included. Risk of bias was assessed using the Prediction Model Risk of Bias Assessment Tool (PROBAST). PROSPERO registration: CRD42023452509. Results: Out of 10,307 records screened, 20 studies met the eligibility criteria for this review incorporating a total of 20,286 aneurysm cases. The machine learning models gave a 0.66-0.90 range for performance accuracy. The models were compared to current clinical standards in six studies and gave mixed results. Most studies posed high or unclear risks of bias and concerns for applicability, limiting the inferences that can be drawn from them. There was insufficient homogenous data for a meta-analysis. Conclusions: Machine learning can be applied to predict the risk of rupture for intracranial aneurysms. However, the evidence does not comprehensively demonstrate superiority to existing practice, limiting its role as a clinical adjunct. Further prospective multicentre studies of recent machine learning tools are needed to prove clinical validation before they are implemented in the clinic.
Data-Prep-Kit: getting your data ready for LLM application development
Sep 26, 2024



Data preparation is the first and a very important step towards any Large Language Model (LLM) development. This paper introduces an easy-to-use, extensible, and scale-flexible open-source data preparation toolkit called Data Prep Kit (DPK). DPK is architected and designed to enable users to scale their data preparation to their needs. With DPK they can prepare data on a local machine or effortlessly scale to run on a cluster with thousands of CPU Cores. DPK comes with a highly scalable, yet extensible set of modules that transform natural language and code data. If the user needs additional transforms, they can be easily developed using extensive DPK support for transform creation. These modules can be used independently or pipelined to perform a series of operations. In this paper, we describe DPK architecture and show its performance from a small scale to a very large number of CPUs. The modules from DPK have been used for the preparation of Granite Models [1] [2]. We believe DPK is a valuable contribution to the AI community to easily prepare data to enhance the performance of their LLM models or to fine-tune models with Retrieval-Augmented Generation (RAG).
Letter to the Editor: What are the legal and ethical considerations of submitting radiology reports to ChatGPT?
May 09, 2024This letter critically examines the recent article by Infante et al. assessing the utility of large language models (LLMs) like GPT-4, Perplexity, and Bard in identifying urgent findings in emergency radiology reports. While acknowledging the potential of LLMs in generating labels for computer vision, concerns are raised about the ethical implications of using patient data without explicit approval, highlighting the necessity of stringent data protection measures under GDPR.
AutoAI-TS: AutoAI for Time Series Forecasting
Mar 08, 2021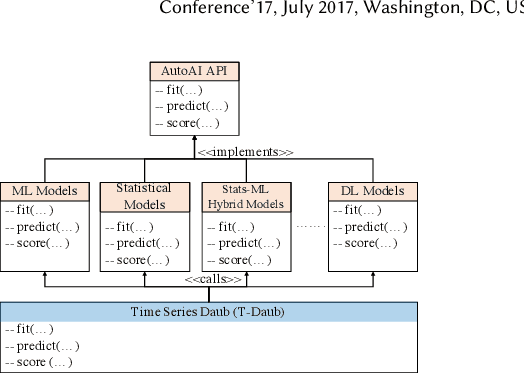
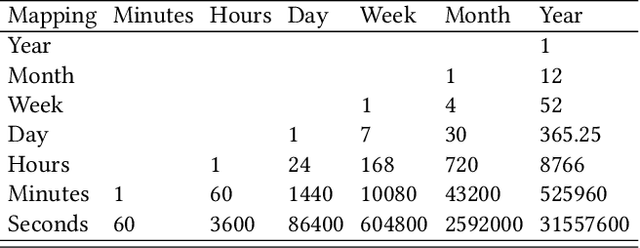
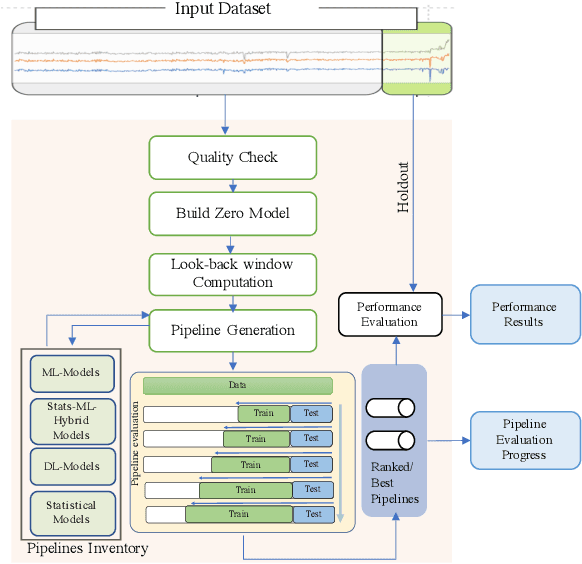
A large number of time series forecasting models including traditional statistical models, machine learning models and more recently deep learning have been proposed in the literature. However, choosing the right model along with good parameter values that performs well on a given data is still challenging. Automatically providing a good set of models to users for a given dataset saves both time and effort from using trial-and-error approaches with a wide variety of available models along with parameter optimization. We present AutoAI for Time Series Forecasting (AutoAI-TS) that provides users with a zero configuration (zero-conf ) system to efficiently train, optimize and choose best forecasting model among various classes of models for the given dataset. With its flexible zero-conf design, AutoAI-TS automatically performs all the data preparation, model creation, parameter optimization, training and model selection for users and provides a trained model that is ready to use. For given data, AutoAI-TS utilizes a wide variety of models including classical statistical models, Machine Learning (ML) models, statistical-ML hybrid models and deep learning models along with various transformations to create forecasting pipelines. It then evaluates and ranks pipelines using the proposed T-Daub mechanism to choose the best pipeline. The paper describe in detail all the technical aspects of AutoAI-TS along with extensive benchmarking on a variety of real world data sets for various use-cases. Benchmark results show that AutoAI-TS, with no manual configuration from the user, automatically trains and selects pipelines that on average outperform existing state-of-the-art time series forecasting toolkits.
NEURO-DRAM: a 3D recurrent visual attention model for interpretable neuroimaging classification
Oct 18, 2019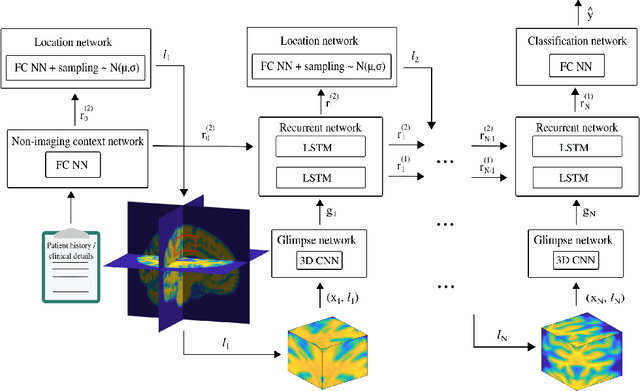
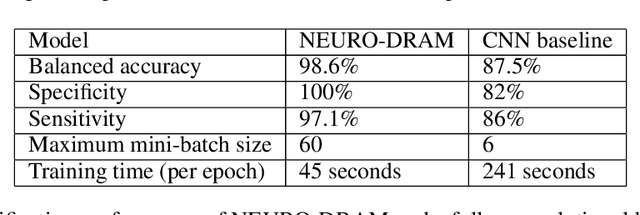

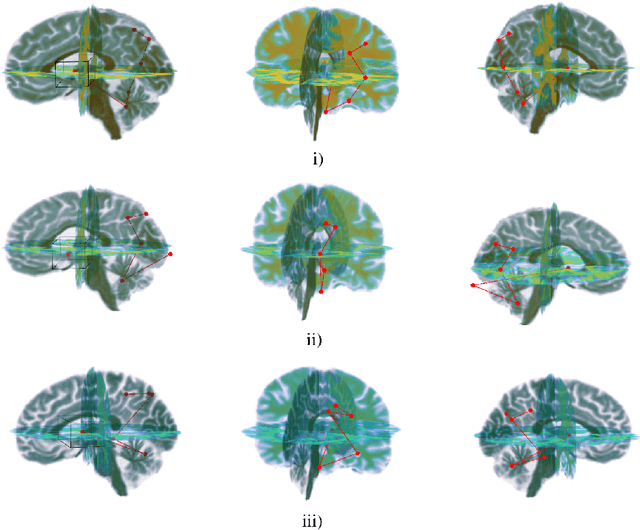
Deep learning is attracting significant interest in the neuroimaging community as a means to diagnose psychiatric and neurological disorders from structural magnetic resonance images. However, there is a tendency amongst researchers to adopt architectures optimized for traditional computer vision tasks, rather than design networks customized for neuroimaging data. We address this by introducing NEURO-DRAM, a 3D recurrent visual attention model tailored for neuroimaging classification. The model comprises an agent which, trained by reinforcement learning, learns to navigate through volumetric images, selectively attending to the most informative regions for a given task. When applied to Alzheimer's disease prediction, NEURODRAM achieves state-of-the-art classification accuracy on an out-of-sample dataset, significantly outperforming a baseline convolutional neural network. When further applied to the task of predicting which patients with mild cognitive impairment will be diagnosed with Alzheimer's disease within two years, the model achieves state-of-the-art accuracy with no additional training. Encouragingly, the agent learns, without explicit instruction, a search policy in agreement with standardized radiological hallmarks of Alzheimer's disease, suggesting a route to automated biomarker discovery for more poorly understood disorders.