 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGneissWeb: Preparing High Quality Data for LLMs at Scale
Feb 19, 2025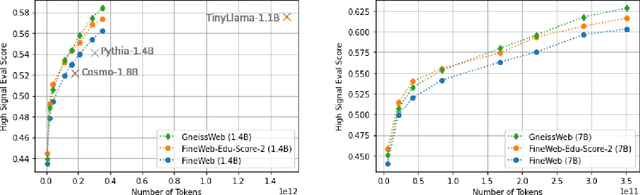
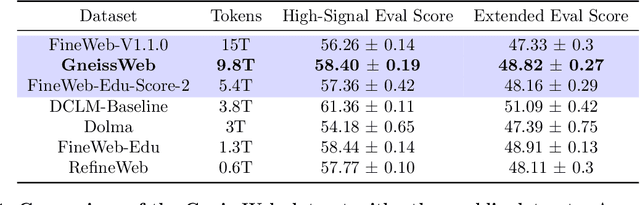
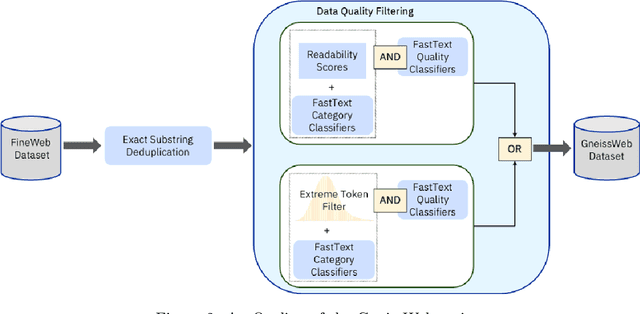

Data quantity and quality play a vital role in determining the performance of Large Language Models (LLMs). High-quality data, in particular, can significantly boost the LLM's ability to generalize on a wide range of downstream tasks. Large pre-training datasets for leading LLMs remain inaccessible to the public, whereas many open datasets are small in size (less than 5 trillion tokens), limiting their suitability for training large models. In this paper, we introduce GneissWeb, a large dataset yielding around 10 trillion tokens that caters to the data quality and quantity requirements of training LLMs. Our GneissWeb recipe that produced the dataset consists of sharded exact sub-string deduplication and a judiciously constructed ensemble of quality filters. GneissWeb achieves a favorable trade-off between data quality and quantity, producing models that outperform models trained on state-of-the-art open large datasets (5+ trillion tokens). We show that models trained using GneissWeb dataset outperform those trained on FineWeb-V1.1.0 by 2.73 percentage points in terms of average score computed on a set of 11 commonly used benchmarks (both zero-shot and few-shot) for pre-training dataset evaluation. When the evaluation set is extended to 20 benchmarks (both zero-shot and few-shot), models trained using GneissWeb still achieve a 1.75 percentage points advantage over those trained on FineWeb-V1.1.0.
Data-Prep-Kit: getting your data ready for LLM application development
Sep 26, 2024



Data preparation is the first and a very important step towards any Large Language Model (LLM) development. This paper introduces an easy-to-use, extensible, and scale-flexible open-source data preparation toolkit called Data Prep Kit (DPK). DPK is architected and designed to enable users to scale their data preparation to their needs. With DPK they can prepare data on a local machine or effortlessly scale to run on a cluster with thousands of CPU Cores. DPK comes with a highly scalable, yet extensible set of modules that transform natural language and code data. If the user needs additional transforms, they can be easily developed using extensive DPK support for transform creation. These modules can be used independently or pipelined to perform a series of operations. In this paper, we describe DPK architecture and show its performance from a small scale to a very large number of CPUs. The modules from DPK have been used for the preparation of Granite Models [1] [2]. We believe DPK is a valuable contribution to the AI community to easily prepare data to enhance the performance of their LLM models or to fine-tune models with Retrieval-Augmented Generation (RAG).
Scaling Granite Code Models to 128K Context
Jul 18, 2024This paper introduces long-context Granite code models that support effective context windows of up to 128K tokens. Our solution for scaling context length of Granite 3B/8B code models from 2K/4K to 128K consists of a light-weight continual pretraining by gradually increasing its RoPE base frequency with repository-level file packing and length-upsampled long-context data. Additionally, we also release instruction-tuned models with long-context support which are derived by further finetuning the long context base models on a mix of permissively licensed short and long-context instruction-response pairs. While comparing to the original short-context Granite code models, our long-context models achieve significant improvements on long-context tasks without any noticeable performance degradation on regular code completion benchmarks (e.g., HumanEval). We release all our long-context Granite code models under an Apache 2.0 license for both research and commercial use.
Granite Code Models: A Family of Open Foundation Models for Code Intelligence
May 07, 2024



Large Language Models (LLMs) trained on code are revolutionizing the software development process. Increasingly, code LLMs are being integrated into software development environments to improve the productivity of human programmers, and LLM-based agents are beginning to show promise for handling complex tasks autonomously. Realizing the full potential of code LLMs requires a wide range of capabilities, including code generation, fixing bugs, explaining and documenting code, maintaining repositories, and more. In this work, we introduce the Granite series of decoder-only code models for code generative tasks, trained with code written in 116 programming languages. The Granite Code models family consists of models ranging in size from 3 to 34 billion parameters, suitable for applications ranging from complex application modernization tasks to on-device memory-constrained use cases. Evaluation on a comprehensive set of tasks demonstrates that Granite Code models consistently reaches state-of-the-art performance among available open-source code LLMs. The Granite Code model family was optimized for enterprise software development workflows and performs well across a range of coding tasks (e.g. code generation, fixing and explanation), making it a versatile all around code model. We release all our Granite Code models under an Apache 2.0 license for both research and commercial use.
Modality-aware Transformer for Time series Forecasting
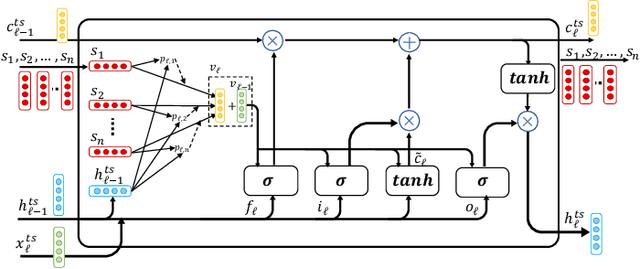
Oct 02, 2023Time series forecasting presents a significant challenge, particularly when its accuracy relies on external data sources rather than solely on historical values. This issue is prevalent in the financial sector, where the future behavior of time series is often intricately linked to information derived from various textual reports and a multitude of economic indicators. In practice, the key challenge lies in constructing a reliable time series forecasting model capable of harnessing data from diverse sources and extracting valuable insights to predict the target time series accurately. In this work, we tackle this challenging problem and introduce a novel multimodal transformer-based model named the Modality-aware Transformer. Our model excels in exploring the power of both categorical text and numerical timeseries to forecast the target time series effectively while providing insights through its neural attention mechanism. To achieve this, we develop feature-level attention layers that encourage the model to focus on the most relevant features within each data modality. By incorporating the proposed feature-level attention, we develop a novel Intra-modal multi-head attention (MHA), Inter-modal MHA and Modality-target MHA in a way that both feature and temporal attentions are incorporated in MHAs. This enables the MHAs to generate temporal attentions with consideration of modality and feature importance which leads to more informative embeddings. The proposed modality-aware structure enables the model to effectively exploit information within each modality as well as foster cross-modal understanding. Our extensive experiments on financial datasets demonstrate that Modality-aware Transformer outperforms existing methods, offering a novel and practical solution to the complex challenges of multi-modality time series forecasting.
Maximal Domain Independent Representations Improve Transfer Learning
Jun 01, 2023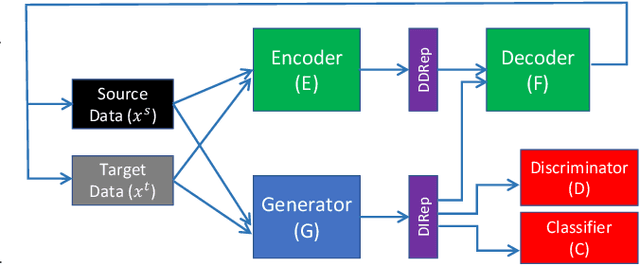
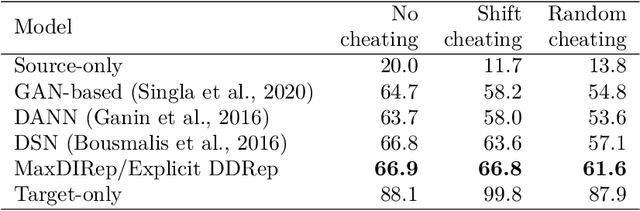
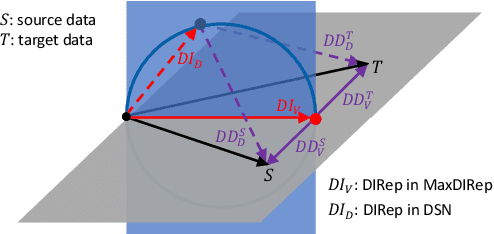

Domain adaptation (DA) adapts a training dataset from a source domain for use in a learning task in a target domain in combination with data available at the target. One popular approach for DA is to create a domain-independent representation (DIRep) learned by a generator from all input samples and then train a classifier on top of it using all labeled samples. A domain discriminator is added to train the generator adversarially to exclude domain specific features from the DIRep. However, this approach tends to generate insufficient information for accurate classification learning. In this paper, we present a novel approach that integrates the adversarial model with a variational autoencoder. In addition to the DIRep, we introduce a domain-dependent representation (DDRep) such that information from both DIRep and DDRep is sufficient to reconstruct samples from both domains. We further penalize the size of the DDRep to drive as much information as possible to the DIRep, which maximizes the accuracy of the classifier in labeling samples in both domains. We empirically evaluate our model using synthetic datasets and demonstrate that spurious class-related features introduced in the source domain are successfully absorbed by the DDRep. This leaves a rich and clean DIRep for accurate transfer learning in the target domain. We further demonstrate its superior performance against other algorithms for a number of common image datasets. We also show we can take advantage of pretrained models.
AutoAI-TS: AutoAI for Time Series Forecasting
Mar 08, 2021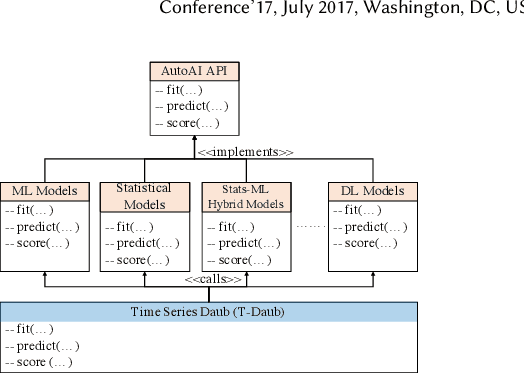
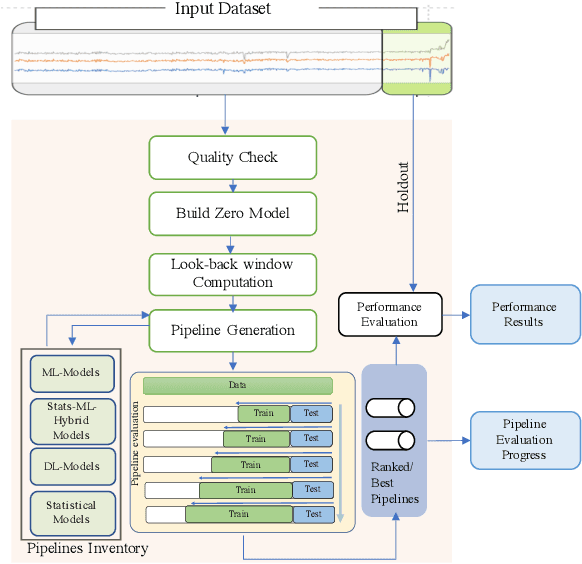
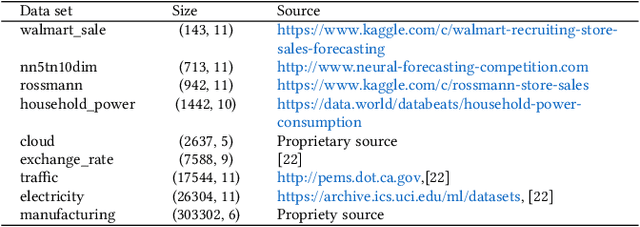
A large number of time series forecasting models including traditional statistical models, machine learning models and more recently deep learning have been proposed in the literature. However, choosing the right model along with good parameter values that performs well on a given data is still challenging. Automatically providing a good set of models to users for a given dataset saves both time and effort from using trial-and-error approaches with a wide variety of available models along with parameter optimization. We present AutoAI for Time Series Forecasting (AutoAI-TS) that provides users with a zero configuration (zero-conf ) system to efficiently train, optimize and choose best forecasting model among various classes of models for the given dataset. With its flexible zero-conf design, AutoAI-TS automatically performs all the data preparation, model creation, parameter optimization, training and model selection for users and provides a trained model that is ready to use. For given data, AutoAI-TS utilizes a wide variety of models including classical statistical models, Machine Learning (ML) models, statistical-ML hybrid models and deep learning models along with various transformations to create forecasting pipelines. It then evaluates and ranks pipelines using the proposed T-Daub mechanism to choose the best pipeline. The paper describe in detail all the technical aspects of AutoAI-TS along with extensive benchmarking on a variety of real world data sets for various use-cases. Benchmark results show that AutoAI-TS, with no manual configuration from the user, automatically trains and selects pipelines that on average outperform existing state-of-the-art time series forecasting toolkits.
"The Squawk Bot": Joint Learning of Time Series and Text Data Modalities for Automated Financial Information Filtering
Dec 20, 2019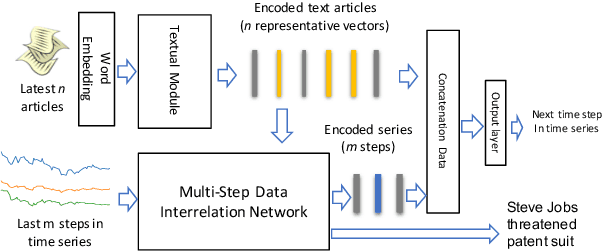
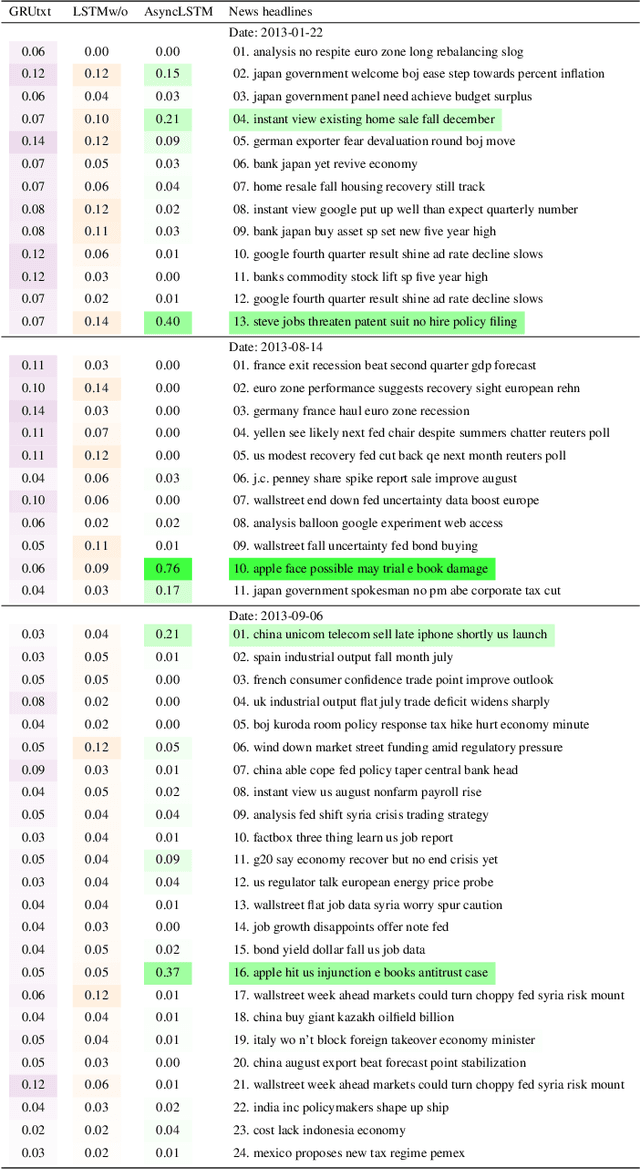
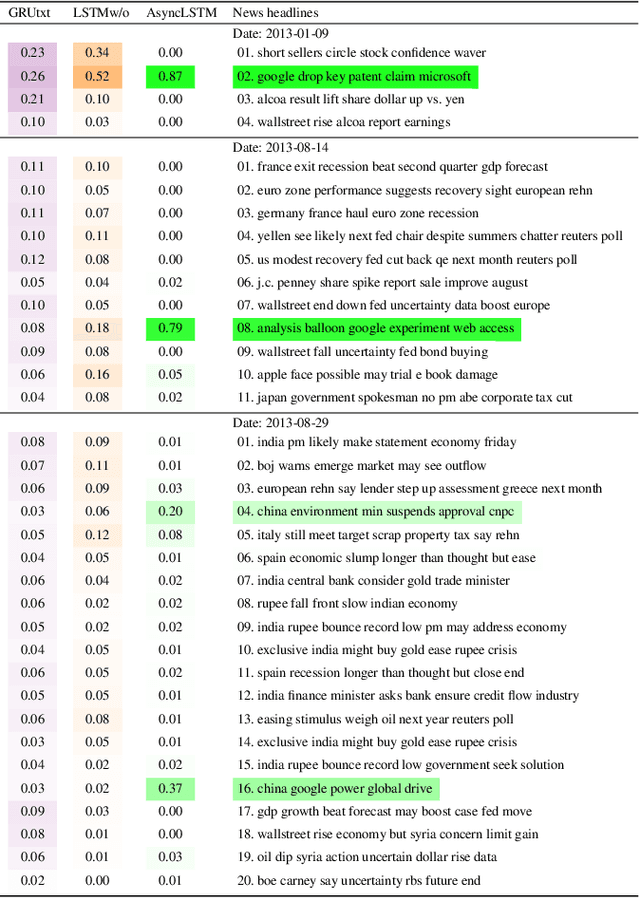
Multimodal analysis that uses numerical time series and textual corpora as input data sources is becoming a promising approach, especially in the financial industry. However, the main focus of such analysis has been on achieving high prediction accuracy while little effort has been spent on the important task of understanding the association between the two data modalities. Performance on the time series hence receives little explanation though human-understandable textual information is available. In this work, we address the problem of given a numerical time series, and a general corpus of textual stories collected in the same period of the time series, the task is to timely discover a succinct set of textual stories associated with that time series. Towards this goal, we propose a novel multi-modal neural model called MSIN that jointly learns both numerical time series and categorical text articles in order to unearth the association between them. Through multiple steps of data interrelation between the two data modalities, MSIN learns to focus on a small subset of text articles that best align with the performance in the time series. This succinct set is timely discovered and presented as recommended documents, acting as automated information filtering, for the given time series. We empirically evaluate the performance of our model on discovering relevant news articles for two stock time series from Apple and Google companies, along with the daily news articles collected from the Thomson Reuters over a period of seven consecutive years. The experimental results demonstrate that MSIN achieves up to 84.9% and 87.2% in recalling the ground truth articles respectively to the two examined time series, far more superior to state-of-the-art algorithms that rely on conventional attention mechanism in deep learning.
seq2graph: Discovering Dynamic Dependencies from Multivariate Time Series with Multi-level Attention
Dec 07, 2018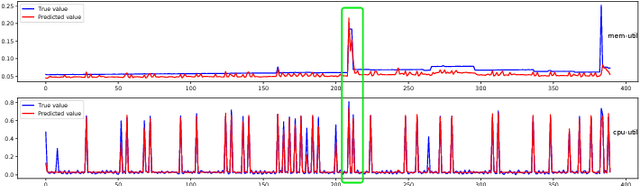
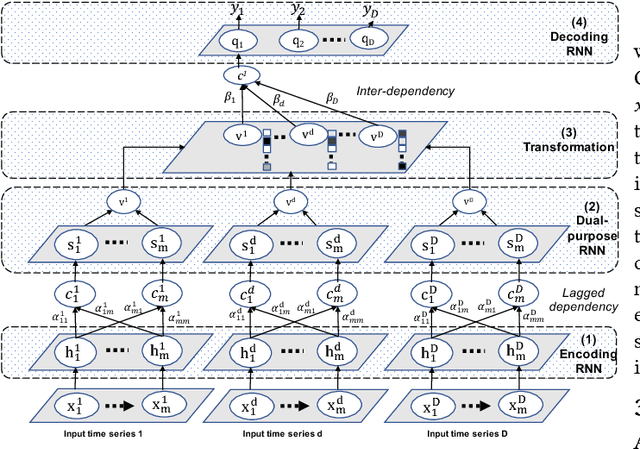
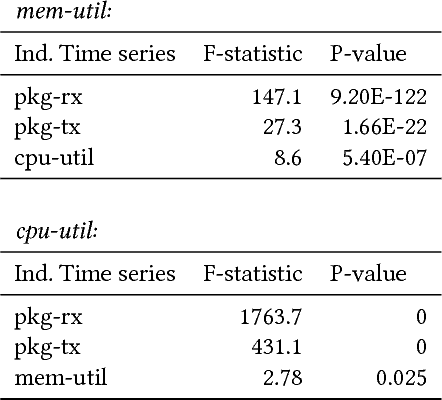

Discovering temporal lagged and inter-dependencies in multivariate time series data is an important task. However, in many real-world applications, such as commercial cloud management, manufacturing predictive maintenance, and portfolios performance analysis, such dependencies can be non-linear and time-variant, which makes it more challenging to extract such dependencies through traditional methods such as Granger causality or clustering. In this work, we present a novel deep learning model that uses multiple layers of customized gated recurrent units (GRUs) for discovering both time lagged behaviors as well as inter-timeseries dependencies in the form of directed weighted graphs. We introduce a key component of Dual-purpose recurrent neural network that decodes information in the temporal domain to discover lagged dependencies within each time series, and encodes them into a set of vectors which, collected from all component time series, form the informative inputs to discover inter-dependencies. Though the discovery of two types of dependencies are separated at different hierarchical levels, they are tightly connected and jointly trained in an end-to-end manner. With this joint training, learning of one type of dependency immediately impacts the learning of the other one, leading to overall accurate dependencies discovery. We empirically test our model on synthetic time series data in which the exact form of (non-linear) dependencies is known. We also evaluate its performance on two real-world applications, (i) performance monitoring data from a commercial cloud provider, which exhibit highly dynamic, non-linear, and volatile behavior and, (ii) sensor data from a manufacturing plant. We further show how our approach is able to capture these dependency behaviors via intuitive and interpretable dependency graphs and use them to generate highly accurate forecasts.
Outlier Detection from Network Data with Subnetwork Interpretation
Sep 30, 2016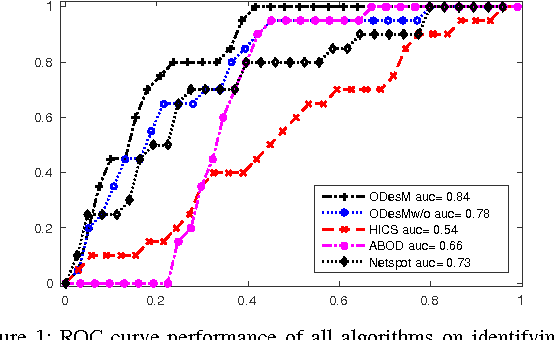
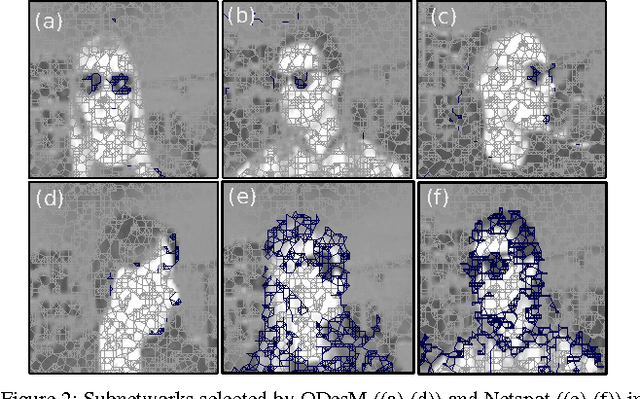
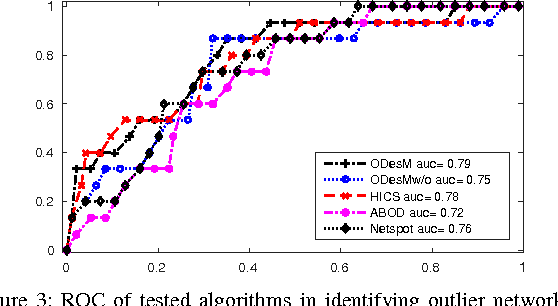
Detecting a small number of outliers from a set of data observations is always challenging. This problem is more difficult in the setting of multiple network samples, where computing the anomalous degree of a network sample is generally not sufficient. In fact, explaining why the network is exceptional, expressed in the form of subnetwork, is also equally important. In this paper, we develop a novel algorithm to address these two key problems. We treat each network sample as a potential outlier and identify subnetworks that mostly discriminate it from nearby regular samples. The algorithm is developed in the framework of network regression combined with the constraints on both network topology and L1-norm shrinkage to perform subnetwork discovery. Our method thus goes beyond subspace/subgraph discovery and we show that it converges to a global optimum. Evaluation on various real-world network datasets demonstrates that our algorithm not only outperforms baselines in both network and high dimensional setting, but also discovers highly relevant and interpretable local subnetworks, further enhancing our understanding of anomalous networks.