 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogitScope: A Framework for Analyzing LLM Uncertainty Through Information Metrics
Mar 26, 2026Understanding and quantifying uncertainty in large language model (LLM) outputs is critical for reliable deployment. However, traditional evaluation approaches provide limited insight into model confidence at individual token positions during generation. To address this issue, we introduce LogitScope, a lightweight framework for analyzing LLM uncertainty through token-level information metrics computed from probability distributions. By measuring metrics such as entropy and varentropy at each generation step, LogitScope reveals patterns in model confidence, identifies potential hallucinations, and exposes decision points where models exhibit high uncertainty, all without requiring labeled data or semantic interpretation. We demonstrate LogitScope's utility across diverse applications including uncertainty quantification, model behavior analysis, and production monitoring. The framework is model-agnostic, computationally efficient through lazy evaluation, and compatible with any HuggingFace model, enabling both researchers and practitioners to inspect LLM behavior during inference.
LLMON: An LLM-native Markup Language to Leverage Structure and Semantics at the LLM Interface
Mar 23, 2026Textual Large Language Models (LLMs) provide a simple and familiar interface: a string of text is used for both input and output. However, the information conveyed to an LLM often has a richer structure and semantics, which is not conveyed in a string. For example, most prompts contain both instructions ("Summarize this paper into a paragraph") and data (the paper to summarize), but these are usually not distinguished when passed to the model. This can lead to model confusion and security risks, such as prompt injection attacks. This work addresses this shortcoming by introducing an LLM-native mark-up language, LLMON (LLM Object Notation, pronounced "Lemon"), that enables the structure and semantic metadata of the text to be communicated in a natural way to an LLM. This information can then be used during model training, model prompting, and inference implementation, leading to improvements in model accuracy, safety, and security. This is analogous to how programming language types can be used for many purposes, such as static checking, code generation, dynamic checking, and IDE highlighting. We discuss the general design requirements of an LLM-native markup language, introduce the LLMON markup language and show how it meets these design requirements, describe how the information contained in a LLMON artifact can benefit model training and inference implementation, and provide some preliminary empirical evidence of its value for both of these use cases. We also discuss broader issues and research opportunities that are enabled with an LLM-native approach.
TSR: Trajectory-Search Rollouts for Multi-Turn RL of LLM Agents
Feb 12, 2026Advances in large language models (LLMs) are driving a shift toward using reinforcement learning (RL) to train agents from iterative, multi-turn interactions across tasks. However, multi-turn RL remains challenging as rewards are often sparse or delayed, and environments can be stochastic. In this regime, naive trajectory sampling can hinder exploitation and induce mode collapse. We propose TSR (Trajectory-Search Rollouts), a training-time approach that repurposes test-time scaling ideas for improved per-turn rollout generation. TSR performs lightweight tree-style search to construct high-quality trajectories by selecting high-scoring actions at each turn using task-specific feedback. This improves rollout quality and stabilizes learning while leaving the underlying optimization objective unchanged, making TSR optimizer-agnostic. We instantiate TSR with best-of-N, beam, and shallow lookahead search, and pair it with PPO and GRPO, achieving up to 15% performance gains and more stable learning on Sokoban, FrozenLake, and WebShop tasks at a one-time increase in training compute. By moving search from inference time to the rollout stage of training, TSR provides a simple and general mechanism for stronger multi-turn agent learning, complementary to existing frameworks and rejection-sampling-style selection methods.
NC-Bench: An LLM Benchmark for Evaluating Conversational Competence
Jan 10, 2026The Natural Conversation Benchmark (NC-Bench) introduce a new approach to evaluating the general conversational competence of large language models (LLMs). Unlike prior benchmarks that focus on the content of model behavior, NC-Bench focuses on the form and structure of natural conversation. Grounded in the IBM Natural Conversation Framework (NCF), NC-Bench comprises three distinct sets. The Basic Conversation Competence set evaluates fundamental sequence management practices, such as answering inquiries, repairing responses, and closing conversational pairs. The RAG set applies the same sequence management patterns as the first set but incorporates retrieval-augmented generation (RAG). The Complex Request set extends the evaluation to complex requests involving more intricate sequence management patterns. Each benchmark tests a model's ability to produce contextually appropriate conversational actions in response to characteristic interaction patterns. Initial evaluations across 6 open-source models and 14 interaction patterns show that models perform well on basic answering tasks, struggle more with repair tasks (especially repeat), have mixed performance on closing sequences, and find complex multi-turn requests most challenging, with Qwen models excelling on the Basic set and Granite models on the RAG set and the Complex Request set. By operationalizing fundamental principles of human conversation, NC-Bench provides a lightweight, extensible, and theory-grounded framework for assessing and improving the conversational abilities of LLMs beyond topical or task-specific benchmarks.
MermaidSeqBench: An Evaluation Benchmark for LLM-to-Mermaid Sequence Diagram Generation
Nov 18, 2025Large language models (LLMs) have demonstrated excellent capabilities in generating structured diagrams from natural language descriptions. In particular, they have shown great promise in generating sequence diagrams for software engineering, typically represented in a text-based syntax such as Mermaid. However, systematic evaluations in this space remain underdeveloped as there is a lack of existing benchmarks to assess the LLM's correctness in this task. To address this shortcoming, we introduce MermaidSeqBench, a human-verified and LLM-synthetically-extended benchmark for assessing an LLM's capabilities in generating Mermaid sequence diagrams from textual prompts. The benchmark consists of a core set of 132 samples, starting from a small set of manually crafted and verified flows. These were expanded via a hybrid methodology combining human annotation, in-context LLM prompting, and rule-based variation generation. Our benchmark uses an LLM-as-a-judge model to assess Mermaid sequence diagram generation across fine-grained metrics, including syntax correctness, activation handling, error handling, and practical usability. We perform initial evaluations on numerous state-of-the-art LLMs and utilize multiple LLM judge models to demonstrate the effectiveness and flexibility of our benchmark. Our results reveal significant capability gaps across models and evaluation modes. Our proposed benchmark provides a foundation for advancing research in structured diagram generation and for developing more rigorous, fine-grained evaluation methodologies.
When Data is the Algorithm: A Systematic Study and Curation of Preference Optimization Datasets
Nov 14, 2025Aligning large language models (LLMs) is a central objective of post-training, often achieved through reward modeling and reinforcement learning methods. Among these, direct preference optimization (DPO) has emerged as a widely adopted technique that fine-tunes LLMs on preferred completions over less favorable ones. While most frontier LLMs do not disclose their curated preference pairs, the broader LLM community has released several open-source DPO datasets, including TuluDPO, ORPO, UltraFeedback, HelpSteer, and Code-Preference-Pairs. However, systematic comparisons remain scarce, largely due to the high computational cost and the lack of rich quality annotations, making it difficult to understand how preferences were selected, which task types they span, and how well they reflect human judgment on a per-sample level. In this work, we present the first comprehensive, data-centric analysis of popular open-source DPO corpora. We leverage the Magpie framework to annotate each sample for task category, input quality, and preference reward, a reward-model-based signal that validates the preference order without relying on human annotations. This enables a scalable, fine-grained inspection of preference quality across datasets, revealing structural and qualitative discrepancies in reward margins. Building on these insights, we systematically curate a new DPO mixture, UltraMix, that draws selectively from all five corpora while removing noisy or redundant samples. UltraMix is 30% smaller than the best-performing individual dataset yet exceeds its performance across key benchmarks. We publicly release all annotations, metadata, and our curated mixture to facilitate future research in data-centric preference optimization.
Fixing It in Post: A Comparative Study of LLM Post-Training Data Quality and Model Performance
Jun 06, 2025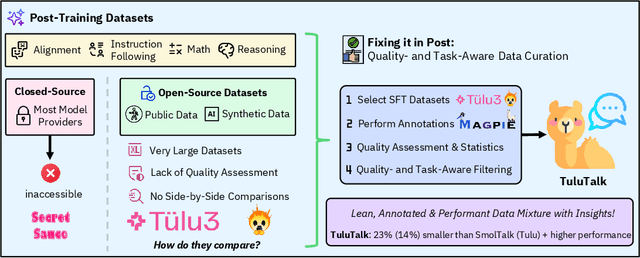


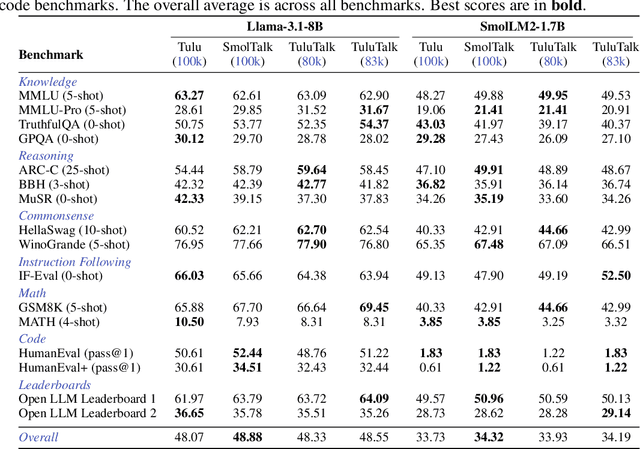
Recent work on large language models (LLMs) has increasingly focused on post-training and alignment with datasets curated to enhance instruction following, world knowledge, and specialized skills. However, most post-training datasets used in leading open- and closed-source LLMs remain inaccessible to the public, with limited information about their construction process. This lack of transparency has motivated the recent development of open-source post-training corpora. While training on these open alternatives can yield performance comparable to that of leading models, systematic comparisons remain challenging due to the significant computational cost of conducting them rigorously at scale, and are therefore largely absent. As a result, it remains unclear how specific samples, task types, or curation strategies influence downstream performance when assessing data quality. In this work, we conduct the first comprehensive side-by-side analysis of two prominent open post-training datasets: Tulu-3-SFT-Mix and SmolTalk. Using the Magpie framework, we annotate each sample with detailed quality metrics, including turn structure (single-turn vs. multi-turn), task category, input quality, and response quality, and we derive statistics that reveal structural and qualitative similarities and differences between the two datasets. Based on these insights, we design a principled curation recipe that produces a new data mixture, TuluTalk, which contains 14% fewer samples than either source dataset while matching or exceeding their performance on key benchmarks. Our findings offer actionable insights for constructing more effective post-training datasets that improve model performance within practical resource limits. To support future research, we publicly release both the annotated source datasets and our curated TuluTalk mixture.
How Is Generative AI Used for Persona Development?: A Systematic Review of 52 Research Articles
Apr 07, 2025

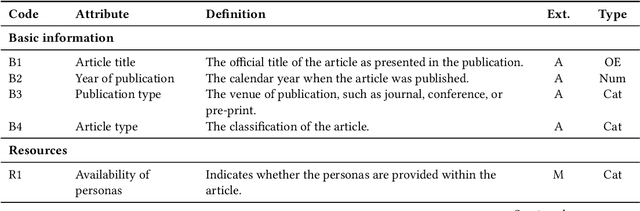
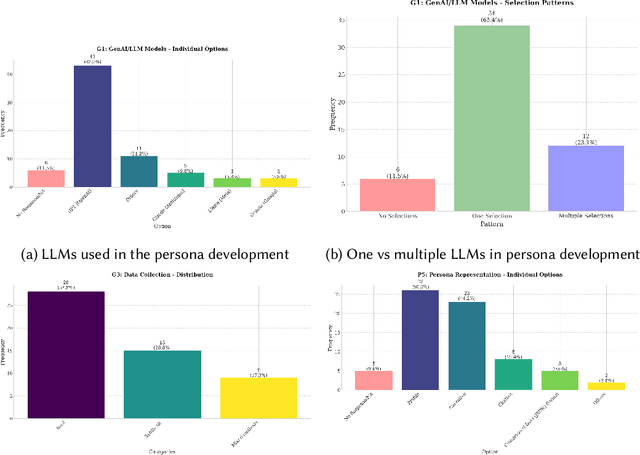
Although Generative AI (GenAI) has the potential for persona development, many challenges must be addressed. This research systematically reviews 52 articles from 2022-2024, with important findings. First, closed commercial models are frequently used in persona development, creating a monoculture Second, GenAI is used in various stages of persona development (data collection, segmentation, enrichment, and evaluation). Third, similar to other quantitative persona development techniques, there are major gaps in persona evaluation for AI generated personas. Fourth, human-AI collaboration models are underdeveloped, despite human oversight being crucial for maintaining ethical standards. These findings imply that realizing the full potential of AI-generated personas will require substantial efforts across academia and industry. To that end, we provide a list of research avenues to inspire future work.
SafeMERGE: Preserving Safety Alignment in Fine-Tuned Large Language Models via Selective Layer-Wise Model Merging
Mar 21, 2025
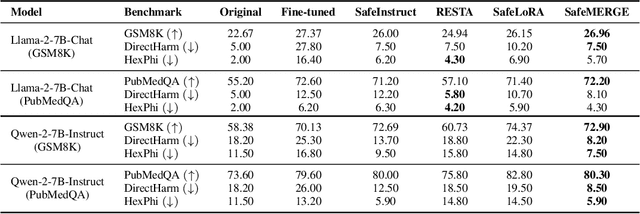
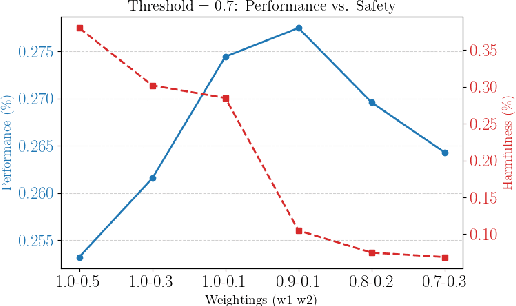
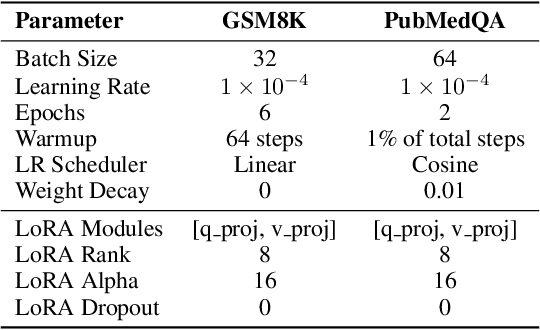
Fine-tuning large language models (LLMs) on downstream tasks can inadvertently erode their safety alignment, even for benign fine-tuning datasets. We address this challenge by proposing SafeMERGE, a post-fine-tuning framework that preserves safety while maintaining task utility. It achieves this by selectively merging fine-tuned and safety-aligned model layers only when those deviate from safe behavior, measured by a cosine similarity criterion. We evaluate SafeMERGE against other fine-tuning- and post-fine-tuning-stage approaches for Llama-2-7B-Chat and Qwen-2-7B-Instruct models on GSM8K and PubMedQA tasks while exploring different merging strategies. We find that SafeMERGE consistently reduces harmful outputs compared to other baselines without significantly sacrificing performance, sometimes even enhancing it. The results suggest that our selective, subspace-guided, and per-layer merging method provides an effective safeguard against the inadvertent loss of safety in fine-tuned LLMs while outperforming simpler post-fine-tuning-stage defenses.
GneissWeb: Preparing High Quality Data for LLMs at Scale
Feb 19, 2025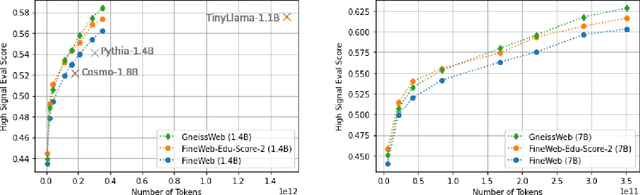
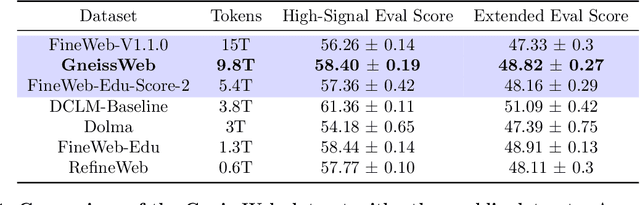
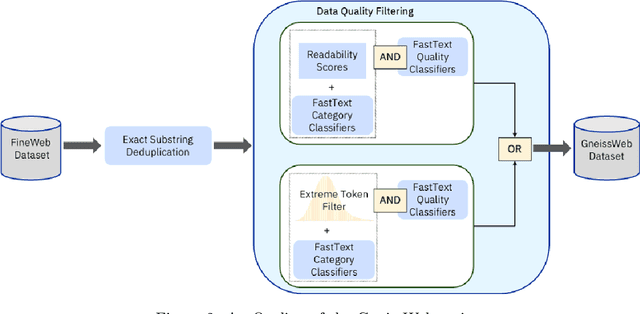

Data quantity and quality play a vital role in determining the performance of Large Language Models (LLMs). High-quality data, in particular, can significantly boost the LLM's ability to generalize on a wide range of downstream tasks. Large pre-training datasets for leading LLMs remain inaccessible to the public, whereas many open datasets are small in size (less than 5 trillion tokens), limiting their suitability for training large models. In this paper, we introduce GneissWeb, a large dataset yielding around 10 trillion tokens that caters to the data quality and quantity requirements of training LLMs. Our GneissWeb recipe that produced the dataset consists of sharded exact sub-string deduplication and a judiciously constructed ensemble of quality filters. GneissWeb achieves a favorable trade-off between data quality and quantity, producing models that outperform models trained on state-of-the-art open large datasets (5+ trillion tokens). We show that models trained using GneissWeb dataset outperform those trained on FineWeb-V1.1.0 by 2.73 percentage points in terms of average score computed on a set of 11 commonly used benchmarks (both zero-shot and few-shot) for pre-training dataset evaluation. When the evaluation set is extended to 20 benchmarks (both zero-shot and few-shot), models trained using GneissWeb still achieve a 1.75 percentage points advantage over those trained on FineWeb-V1.1.0.