 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKEYword based Sampling (KEYS) for Large Language Models
Jun 02, 2023

Question answering (Q/A) can be formulated as a generative task (Mitra, 2017) where the task is to generate an answer given the question and the passage (knowledge, if available). Recent advances in QA task is focused a lot on language model advancements and less on other areas such as sampling(Krishna et al., 2021), (Nakano et al., 2021). Keywords play very important role for humans in language generation. (Humans formulate keywords and use grammar to connect those keywords and work). In the research community, very little focus is on how humans generate answers to a question and how this behavior can be incorporated in a language model. In this paper, we want to explore these two areas combined, i.e., how sampling can be to used generate answers which are close to human-like behavior and factually correct. Hence, the type of decoding algorithm we think should be used for Q/A tasks should also depend on the keywords. These keywords can be obtained from the question, passage or internet results. We use knowledge distillation techniques to extract keywords and sample using these extracted keywords on top of vanilla decoding algorithms when formulating the answer to generate a human-like answer. In this paper, we show that our decoding method outperforms most commonly used decoding methods for Q/A task
Human-Centered Metrics for Dialog System Evaluation
May 24, 2023



We present metrics for evaluating dialog systems through a psychologically-grounded "human" lens: conversational agents express a diversity of both states (short-term factors like emotions) and traits (longer-term factors like personality) just as people do. These interpretable metrics consist of five measures from established psychology constructs that can be applied both across dialogs and on turns within dialogs: emotional entropy, linguistic style and emotion matching, as well as agreeableness and empathy. We compare these human metrics against 6 state-of-the-art automatic metrics (e.g. BARTScore and BLEURT) on 7 standard dialog system data sets. We also introduce a novel data set, the Three Bot Dialog Evaluation Corpus, which consists of annotated conversations from ChatGPT, GPT-3, and BlenderBot. We demonstrate the proposed human metrics offer novel information, are uncorrelated with automatic metrics, and lead to increased accuracy beyond existing automatic metrics for predicting crowd-sourced dialog judgements. The interpretability and unique signal of our proposed human-centered framework make it a valuable tool for evaluating and improving dialog systems.
How to Choose How to Choose Your Chatbot: A Massively Multi-System MultiReference Data Set for Dialog Metric Evaluation
May 23, 2023
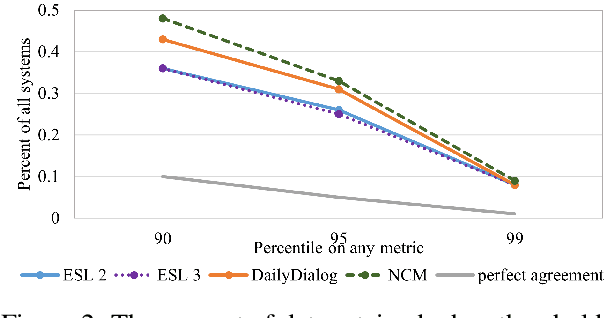
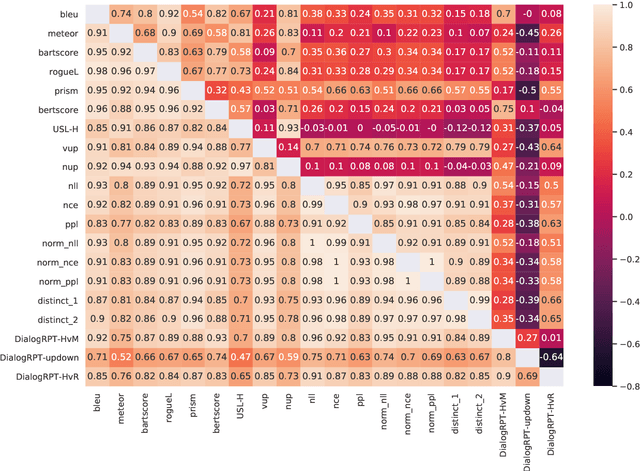
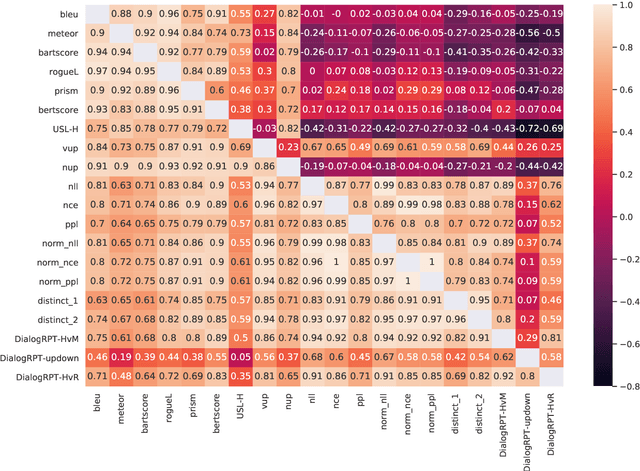
We release MMSMR, a Massively Multi-System MultiReference dataset to enable future work on metrics and evaluation for dialog. Automatic metrics for dialogue evaluation should be robust proxies for human judgments; however, the verification of robustness is currently far from satisfactory. To quantify the robustness correlation and understand what is necessary in a test set, we create and release an 8-reference dialog dataset by extending single-reference evaluation sets and introduce this new language learning conversation dataset. We then train 1750 systems and evaluate them on our novel test set and the DailyDialog dataset. We release the novel test set, and model hyper parameters, inference outputs, and metric scores for each system on a variety of datasets.
Small-footprint slimmable networks for keyword spotting
Apr 21, 2023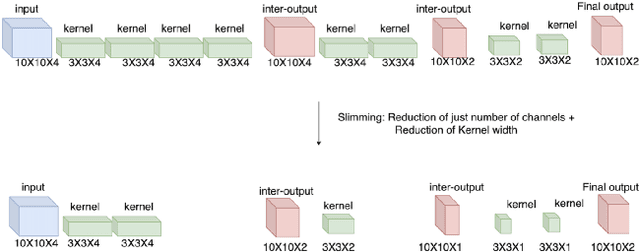
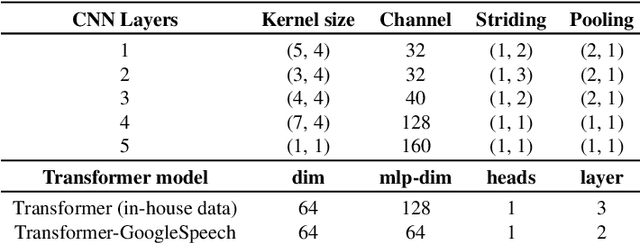
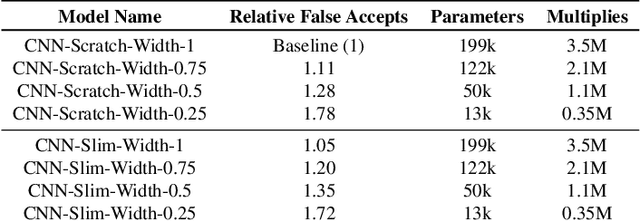
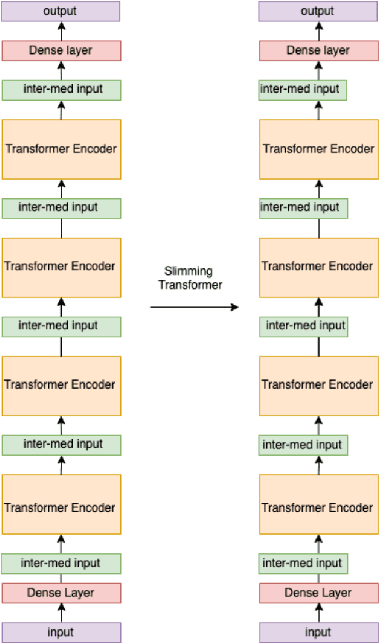
In this work, we present Slimmable Neural Networks applied to the problem of small-footprint keyword spotting. We show that slimmable neural networks allow us to create super-nets from Convolutioanl Neural Networks and Transformers, from which sub-networks of different sizes can be extracted. We demonstrate the usefulness of these models on in-house Alexa data and Google Speech Commands, and focus our efforts on models for the on-device use case, limiting ourselves to less than 250k parameters. We show that slimmable models can match (and in some cases, outperform) models trained from scratch. Slimmable neural networks are therefore a class of models particularly useful when the same functionality is to be replicated at different memory and compute budgets, with different accuracy requirements.
Automatic Number Plate Recognition using Random Forest Classifier
Mar 26, 2023Automatic Number Plate Recognition System (ANPRS) is a mass surveillance embedded system that recognizes the number plate of the vehicle. This system is generally used for traffic management applications. It should be very efficient in detecting the number plate in noisy as well as in low illumination and also within required time frame. This paper proposes a number plate recognition method by processing vehicle's rear or front image. After image is captured, processing is divided into four steps which are Pre-Processing, Number plate localization, Character segmentation and Character recognition. Pre-Processing enhances the image for further processing, number plate localization extracts the number plate region from the image, character segmentation separates the individual characters from the extracted number plate and character recognition identifies the optical characters by using random forest classification algorithm. Experimental results reveal that the accuracy of this method is 90.9%.