 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInferring Effects of Major Events through Discontinuity Forecasting of Population Anxiety
Aug 29, 2025Estimating community-specific mental health effects of local events is vital for public health policy. While forecasting mental health scores alone offers limited insights into the impact of events on community well-being, quasi-experimental designs like the Longitudinal Regression Discontinuity Design (LRDD) from econometrics help researchers derive more effects that are more likely to be causal from observational data. LRDDs aim to extrapolate the size of changes in an outcome (e.g. a discontinuity in running scores for anxiety) due to a time-specific event. Here, we propose adapting LRDDs beyond traditional forecasting into a statistical learning framework whereby future discontinuities (i.e. time-specific shifts) and changes in slope (i.e. linear trajectories) are estimated given a location's history of the score, dynamic covariates (other running assessments), and exogenous variables (static representations). Applying our framework to predict discontinuities in the anxiety of US counties from COVID-19 events, we found the task was difficult but more achievable as the sophistication of models was increased, with the best results coming from integrating exogenous and dynamic covariates. Our approach shows strong improvement ($r=+.46$ for discontinuity and $r = +.65$ for slope) over traditional static community representations. Discontinuity forecasting raises new possibilities for estimating the idiosyncratic effects of potential future or hypothetical events on specific communities.
MAQuA: Adaptive Question-Asking for Multidimensional Mental Health Screening using Item Response Theory
Aug 10, 2025Recent advances in large language models (LLMs) offer new opportunities for scalable, interactive mental health assessment, but excessive querying by LLMs burdens users and is inefficient for real-world screening across transdiagnostic symptom profiles. We introduce MAQuA, an adaptive question-asking framework for simultaneous, multidimensional mental health screening. Combining multi-outcome modeling on language responses with item response theory (IRT) and factor analysis, MAQuA selects the questions with most informative responses across multiple dimensions at each turn to optimize diagnostic information, improving accuracy and potentially reducing response burden. Empirical results on a novel dataset reveal that MAQuA reduces the number of assessment questions required for score stabilization by 50-87% compared to random ordering (e.g., achieving stable depression scores with 71% fewer questions and eating disorder scores with 85% fewer questions). MAQuA demonstrates robust performance across both internalizing (depression, anxiety) and externalizing (substance use, eating disorder) domains, with early stopping strategies further reducing patient time and burden. These findings position MAQuA as a powerful and efficient tool for scalable, nuanced, and interactive mental health screening, advancing the integration of LLM-based agents into real-world clinical workflows.
Capturing Human Cognitive Styles with Language: Towards an Experimental Evaluation Paradigm
Feb 18, 2025



While NLP models often seek to capture cognitive states via language, the validity of predicted states is determined by comparing them to annotations created without access the cognitive states of the authors. In behavioral sciences, cognitive states are instead measured via experiments. Here, we introduce an experiment-based framework for evaluating language-based cognitive style models against human behavior. We explore the phenomenon of decision making, and its relationship to the linguistic style of an individual talking about a recent decision they made. The participants then follow a classical decision-making experiment that captures their cognitive style, determined by how preferences change during a decision exercise. We find that language features, intended to capture cognitive style, can predict participants' decision style with moderate-to-high accuracy (AUC ~ 0.8), demonstrating that cognitive style can be partly captured and revealed by discourse patterns.
Unifying the Extremes: Developing a Unified Model for Detecting and Predicting Extremist Traits and Radicalization
Jan 08, 2025



The proliferation of ideological movements into extremist factions via social media has become a global concern. While radicalization has been studied extensively within the context of specific ideologies, our ability to accurately characterize extremism in more generalizable terms remains underdeveloped. In this paper, we propose a novel method for extracting and analyzing extremist discourse across a range of online community forums. By focusing on verbal behavioral signatures of extremist traits, we develop a framework for quantifying extremism at both user and community levels. Our research identifies 11 distinct factors, which we term ``The Extremist Eleven,'' as a generalized psychosocial model of extremism. Applying our method to various online communities, we demonstrate an ability to characterize ideologically diverse communities across the 11 extremist traits. We demonstrate the power of this method by analyzing user histories from members of the incel community. We find that our framework accurately predicts which users join the incel community up to 10 months before their actual entry with an AUC of $>0.6$, steadily increasing to AUC ~0.9 three to four months before the event. Further, we find that upon entry into an extremist forum, the users tend to maintain their level of extremism within the community, while still remaining distinguishable from the general online discourse. Our findings contribute to the study of extremism by introducing a more holistic, cross-ideological approach that transcends traditional, trait-specific models.
PsychAdapter: Adapting LLM Transformers to Reflect Traits, Personality and Mental Health
Dec 22, 2024



Artificial intelligence-based language generators are now a part of most people's lives. However, by default, they tend to generate "average" language without reflecting the ways in which people differ. Here, we propose a lightweight modification to the standard language model transformer architecture - "PsychAdapter" - that uses empirically derived trait-language patterns to generate natural language for specified personality, demographic, and mental health characteristics (with or without prompting). We applied PsychAdapters to modify OpenAI's GPT-2, Google's Gemma, and Meta's Llama 3 and found generated text to reflect the desired traits. For example, expert raters evaluated PsychAdapter's generated text output and found it matched intended trait levels with 87.3% average accuracy for Big Five personalities, and 96.7% for depression and life satisfaction. PsychAdapter is a novel method to introduce psychological behavior patterns into language models at the foundation level, independent of prompting, by influencing every transformer layer. This approach can create chatbots with specific personality profiles, clinical training tools that mirror language associated with psychological conditionals, and machine translations that match an authors reading or education level without taking up LLM context windows. PsychAdapter also allows for the exploration psychological constructs through natural language expression, extending the natural language processing toolkit to study human psychology.
Explaining GPT-4's Schema of Depression Using Machine Behavior Analysis
Nov 21, 2024



Use of large language models such as ChatGPT (GPT-4) for mental health support has grown rapidly, emerging as a promising route to assess and help people with mood disorders, like depression. However, we have a limited understanding of GPT-4's schema of mental disorders, that is, how it internally associates and interprets symptoms. In this work, we leveraged contemporary measurement theory to decode how GPT-4 interrelates depressive symptoms to inform both clinical utility and theoretical understanding. We found GPT-4's assessment of depression: (a) had high overall convergent validity (r = .71 with self-report on 955 samples, and r = .81 with experts judgments on 209 samples); (b) had moderately high internal consistency (symptom inter-correlates r = .23 to .78 ) that largely aligned with literature and self-report; except that GPT-4 (c) underemphasized suicidality's -- and overemphasized psychomotor's -- relationship with other symptoms, and (d) had symptom inference patterns that suggest nuanced hypotheses (e.g. sleep and fatigue are influenced by most other symptoms while feelings of worthlessness/guilt is mostly influenced by depressed mood).
SOCIALITE-LLAMA: An Instruction-Tuned Model for Social Scientific Tasks
Feb 03, 2024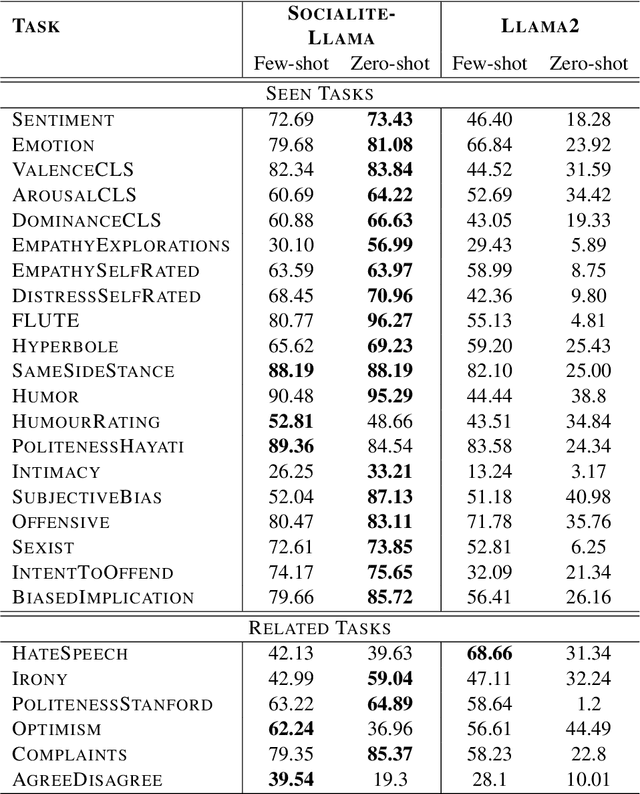



Social science NLP tasks, such as emotion or humor detection, are required to capture the semantics along with the implicit pragmatics from text, often with limited amounts of training data. Instruction tuning has been shown to improve the many capabilities of large language models (LLMs) such as commonsense reasoning, reading comprehension, and computer programming. However, little is known about the effectiveness of instruction tuning on the social domain where implicit pragmatic cues are often needed to be captured. We explore the use of instruction tuning for social science NLP tasks and introduce Socialite-Llama -- an open-source, instruction-tuned Llama. On a suite of 20 social science tasks, Socialite-Llama improves upon the performance of Llama as well as matches or improves upon the performance of a state-of-the-art, multi-task finetuned model on a majority of them. Further, Socialite-Llama also leads to improvement on 5 out of 6 related social tasks as compared to Llama, suggesting instruction tuning can lead to generalized social understanding. All resources including our code, model and dataset can be found through bit.ly/socialitellama.
Comparing Human-Centered Language Modeling: Is it Better to Model Groups, Individual Traits, or Both?
Jan 23, 2024



Natural language processing has made progress in incorporating human context into its models, but whether it is more effective to use group-wise attributes (e.g., over-45-year-olds) or model individuals remains open. Group attributes are technically easier but coarse: not all 45-year-olds write the same way. In contrast, modeling individuals captures the complexity of each person's identity. It allows for a more personalized representation, but we may have to model an infinite number of users and require data that may be impossible to get. We compare modeling human context via group attributes, individual users, and combined approaches. Combining group and individual features significantly benefits user-level regression tasks like age estimation or personality assessment from a user's documents. Modeling individual users significantly improves the performance of single document-level classification tasks like stance and topic detection. We also find that individual-user modeling does well even without user's historical data.
Adaptive Language-based Mental Health Assessment with Item-Response Theory
Nov 11, 2023Mental health issues widely vary across individuals - the manifestations of signs and symptoms can be fairly heterogeneous. Recently, language-based depression and anxiety assessments have shown promise for capturing this heterogeneous nature by evaluating a patient's own language, but such approaches require a large sample of words per person to be accurate. In this work, we introduce adaptive language-based assessment - the task of iteratively estimating an individual's psychological score based on limited language responses to questions that the model also decides to ask. To this end, we explore two statistical learning-based approaches for measurement/scoring: classical test theory (CTT) and item response theory (IRT). We find that using adaptive testing in general can significantly reduce the number of questions required to achieve high validity (r ~ 0.7) with standardized tests, bringing down from 11 total questions down to 3 for depression and 5 for anxiety. Given the combinatorial nature of the problem, we empirically evaluate multiple strategies for both the ordering and scoring objectives, introducing two new methods: a semi-supervised item response theory based method (ALIRT), and a supervised actor-critic based model. While both of the models achieve significant improvements over random and fixed orderings, we find ALIRT to be a scalable model that achieves the highest accuracy with lower numbers of questions (e.g. achieves Pearson r ~ 0.93 after only 3 questions versus asking all 11 questions). Overall, ALIRT allows prompting a reduced number of questions without compromising accuracy or overhead computational costs.
Systematic Evaluation of GPT-3 for Zero-Shot Personality Estimation
Jun 01, 2023



Very large language models (LLMs) perform extremely well on a spectrum of NLP tasks in a zero-shot setting. However, little is known about their performance on human-level NLP problems which rely on understanding psychological concepts, such as assessing personality traits. In this work, we investigate the zero-shot ability of GPT-3 to estimate the Big 5 personality traits from users' social media posts. Through a set of systematic experiments, we find that zero-shot GPT-3 performance is somewhat close to an existing pre-trained SotA for broad classification upon injecting knowledge about the trait in the prompts. However, when prompted to provide fine-grained classification, its performance drops to close to a simple most frequent class (MFC) baseline. We further analyze where GPT-3 performs better, as well as worse, than a pretrained lexical model, illustrating systematic errors that suggest ways to improve LLMs on human-level NLP tasks.