 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePsychAdapter: Adapting LLM Transformers to Reflect Traits, Personality and Mental Health
Dec 22, 2024



Artificial intelligence-based language generators are now a part of most people's lives. However, by default, they tend to generate "average" language without reflecting the ways in which people differ. Here, we propose a lightweight modification to the standard language model transformer architecture - "PsychAdapter" - that uses empirically derived trait-language patterns to generate natural language for specified personality, demographic, and mental health characteristics (with or without prompting). We applied PsychAdapters to modify OpenAI's GPT-2, Google's Gemma, and Meta's Llama 3 and found generated text to reflect the desired traits. For example, expert raters evaluated PsychAdapter's generated text output and found it matched intended trait levels with 87.3% average accuracy for Big Five personalities, and 96.7% for depression and life satisfaction. PsychAdapter is a novel method to introduce psychological behavior patterns into language models at the foundation level, independent of prompting, by influencing every transformer layer. This approach can create chatbots with specific personality profiles, clinical training tools that mirror language associated with psychological conditionals, and machine translations that match an authors reading or education level without taking up LLM context windows. PsychAdapter also allows for the exploration psychological constructs through natural language expression, extending the natural language processing toolkit to study human psychology.
Baby Bear: Seeking a Just Right Rating Scale for Scalar Annotations
Aug 19, 2024Our goal is a mechanism for efficiently assigning scalar ratings to each of a large set of elements. For example, "what percent positive or negative is this product review?" When sample sizes are small, prior work has advocated for methods such as Best Worst Scaling (BWS) as being more robust than direct ordinal annotation ("Likert scales"). Here we first introduce IBWS, which iteratively collects annotations through Best-Worst Scaling, resulting in robustly ranked crowd-sourced data. While effective, IBWS is too expensive for large-scale tasks. Using the results of IBWS as a best-desired outcome, we evaluate various direct assessment methods to determine what is both cost-efficient and best correlating to a large scale BWS annotation strategy. Finally, we illustrate in the domains of dialogue and sentiment how these annotations can support robust learning-to-rank models.
Human-Centered Metrics for Dialog System Evaluation
May 24, 2023



We present metrics for evaluating dialog systems through a psychologically-grounded "human" lens: conversational agents express a diversity of both states (short-term factors like emotions) and traits (longer-term factors like personality) just as people do. These interpretable metrics consist of five measures from established psychology constructs that can be applied both across dialogs and on turns within dialogs: emotional entropy, linguistic style and emotion matching, as well as agreeableness and empathy. We compare these human metrics against 6 state-of-the-art automatic metrics (e.g. BARTScore and BLEURT) on 7 standard dialog system data sets. We also introduce a novel data set, the Three Bot Dialog Evaluation Corpus, which consists of annotated conversations from ChatGPT, GPT-3, and BlenderBot. We demonstrate the proposed human metrics offer novel information, are uncorrelated with automatic metrics, and lead to increased accuracy beyond existing automatic metrics for predicting crowd-sourced dialog judgements. The interpretability and unique signal of our proposed human-centered framework make it a valuable tool for evaluating and improving dialog systems.
Lived Experience Matters: Automatic Detection of Stigma toward People Who Use Substances on Social Media
Feb 04, 2023

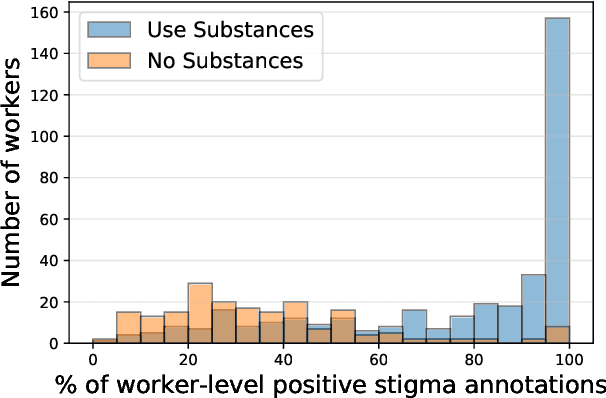
Stigma toward people who use substances (PWUS) is a leading barrier to seeking treatment. Further, those in treatment are more likely to drop out if they experience higher levels of stigmatization. While related concepts of hate speech and toxicity, including those targeted toward vulnerable populations, have been the focus of automatic content moderation research, stigma and, in particular, people who use substances have not. This paper explores stigma toward PWUS using a data set of roughly 5,000 public Reddit posts. We performed a crowd-sourced annotation task where workers are asked to annotate each post for the presence of stigma toward PWUS and answer a series of questions related to their experiences with substance use. Results show that workers who use substances or know someone with a substance use disorder are more likely to rate a post as stigmatizing. Building on this, we use a supervised machine learning framework that centers workers with lived substance use experience to label each Reddit post as stigmatizing. Modeling person-level demographics in addition to comment-level language results in a classification accuracy (as measured by AUC) of 0.69 -- a 17% increase over modeling language alone. Finally, we explore the linguist cues which distinguish stigmatizing content: PWUS substances and those who don't agree that language around othering ("people", "they") and terms like "addict" are stigmatizing, while PWUS (as opposed to those who do not) find discussions around specific substances more stigmatizing. Our findings offer insights into the nature of perceived stigma in substance use. Additionally, these results further establish the subjective nature of such machine learning tasks, highlighting the need for understanding their social contexts.
Deriving Verb Predicates By Clustering Verbs with Arguments
Aug 01, 2017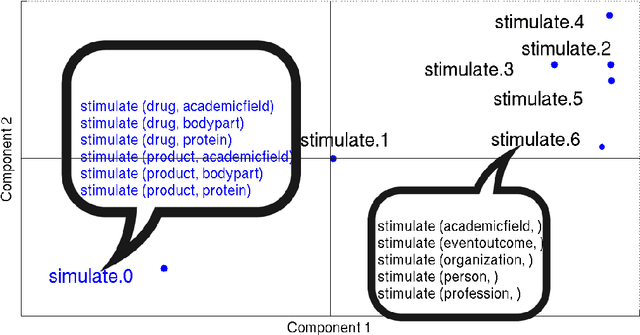
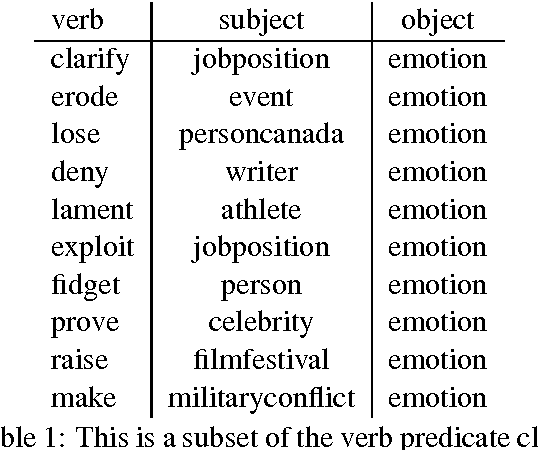
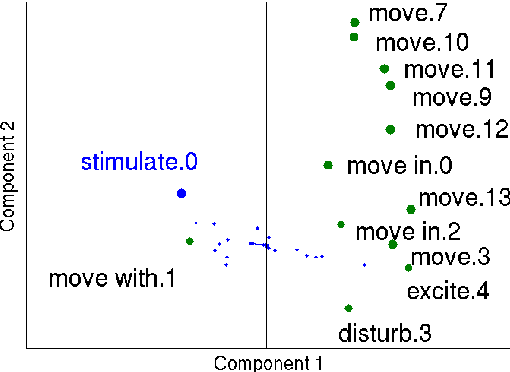
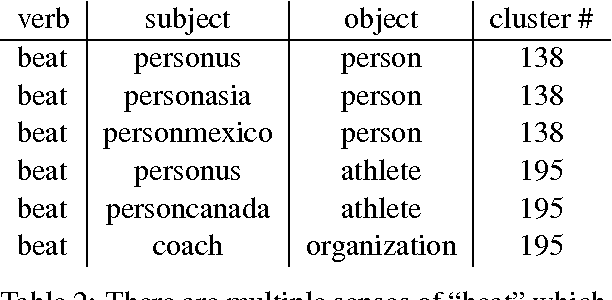
Hand-built verb clusters such as the widely used Levin classes (Levin, 1993) have proved useful, but have limited coverage. Verb classes automatically induced from corpus data such as those from VerbKB (Wijaya, 2016), on the other hand, can give clusters with much larger coverage, and can be adapted to specific corpora such as Twitter. We present a method for clustering the outputs of VerbKB: verbs with their multiple argument types, e.g. "marry(person, person)", "feel(person, emotion)." We make use of a novel low-dimensional embedding of verbs and their arguments to produce high quality clusters in which the same verb can be in different clusters depending on its argument type. The resulting verb clusters do a better job than hand-built clusters of predicting sarcasm, sentiment, and locus of control in tweets.