 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeriving Verb Predicates By Clustering Verbs with Arguments
Aug 01, 2017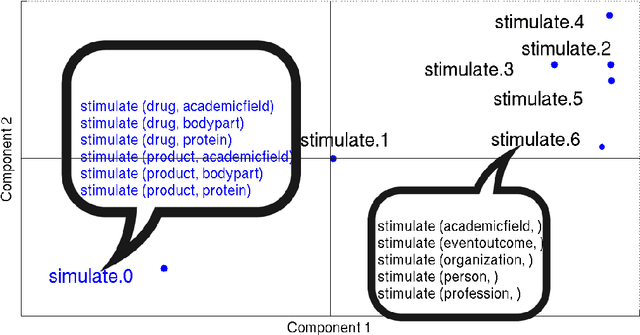
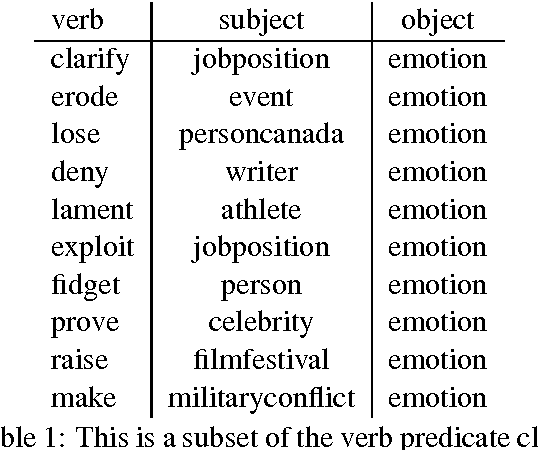
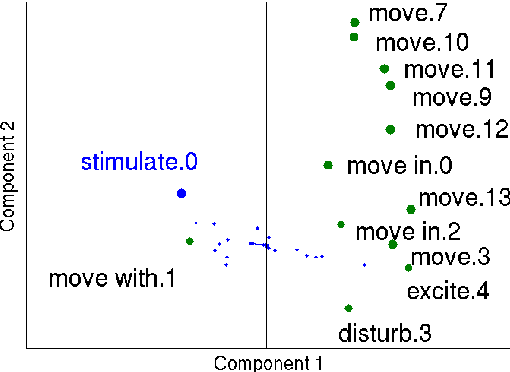
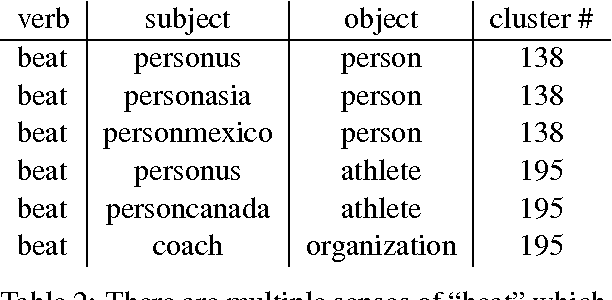
Hand-built verb clusters such as the widely used Levin classes (Levin, 1993) have proved useful, but have limited coverage. Verb classes automatically induced from corpus data such as those from VerbKB (Wijaya, 2016), on the other hand, can give clusters with much larger coverage, and can be adapted to specific corpora such as Twitter. We present a method for clustering the outputs of VerbKB: verbs with their multiple argument types, e.g. "marry(person, person)", "feel(person, emotion)." We make use of a novel low-dimensional embedding of verbs and their arguments to produce high quality clusters in which the same verb can be in different clusters depending on its argument type. The resulting verb clusters do a better job than hand-built clusters of predicting sarcasm, sentiment, and locus of control in tweets.