 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMechanisms are Transferable: Data-Efficient Low-Resource Adaptation via Circuit-Targeted Supervised Fine-Tuning
Jan 13, 2026Adapting LLMs to low-resource languages is difficult: labeled data is scarce, full-model fine-tuning is unstable, and continued cross-lingual tuning can cause catastrophic forgetting. We propose Circuit-Targeted Supervised Fine-Tuning (CT-SFT): a counterfactual-free adaptation of CD-T (Contextual Decomposition Transformer) that uses a label-balanced mean baseline and task-directional relevance scoring to identify a sparse set of task-relevant attention heads in a proxy-language checkpoint, then transfer learns to a target language by updating only those heads (plus LayerNorm) via head-level gradient masking. Across NusaX-Senti and XNLI, CT-SFT improves cross-lingual accuracy over continued full fine-tuning while updating only a small subset of model parameters. We find an editing-preserving trade-off: harder transfers favor editing circuit heads, while easier transfers often favor near-zero (i.e., low-relevance heads) updates, preserving the source mechanism. CT-SFT also substantially reduces catastrophic forgetting, preserving proxy/source-language competence during transfer.
Predicting LLM Correctness in Prosthodontics Using Metadata and Hallucination Signals
Dec 27, 2025Large language models (LLMs) are increasingly adopted in high-stakes domains such as healthcare and medical education, where the risk of generating factually incorrect (i.e., hallucinated) information is a major concern. While significant efforts have been made to detect and mitigate such hallucinations, predicting whether an LLM's response is correct remains a critical yet underexplored problem. This study investigates the feasibility of predicting correctness by analyzing a general-purpose model (GPT-4o) and a reasoning-centric model (OSS-120B) on a multiple-choice prosthodontics exam. We utilize metadata and hallucination signals across three distinct prompting strategies to build a correctness predictor for each (model, prompting) pair. Our findings demonstrate that this metadata-based approach can improve accuracy by up to +7.14% and achieve a precision of 83.12% over a baseline that assumes all answers are correct. We further show that while actual hallucination is a strong indicator of incorrectness, metadata signals alone are not reliable predictors of hallucination. Finally, we reveal that prompting strategies, despite not affecting overall accuracy, significantly alter the models' internal behaviors and the predictive utility of their metadata. These results present a promising direction for developing reliability signals in LLMs but also highlight that the methods explored in this paper are not yet robust enough for critical, high-stakes deployment.
What Do Indonesians Really Need from Language Technology? A Nationwide Survey
Jun 09, 2025



There is an emerging effort to develop NLP for Indonesias 700+ local languages, but progress remains costly due to the need for direct engagement with native speakers. However, it is unclear what these language communities truly need from language technology. To address this, we conduct a nationwide survey to assess the actual needs of native speakers in Indonesia. Our findings indicate that addressing language barriers, particularly through machine translation and information retrieval, is the most critical priority. Although there is strong enthusiasm for advancements in language technology, concerns around privacy, bias, and the use of public data for AI training highlight the need for greater transparency and clear communication to support broader AI adoption.
R3: Robust Rubric-Agnostic Reward Models
May 19, 2025Reward models are essential for aligning language model outputs with human preferences, yet existing approaches often lack both controllability and interpretability. These models are typically optimized for narrow objectives, limiting their generalizability to broader downstream tasks. Moreover, their scalar outputs are difficult to interpret without contextual reasoning. To address these limitations, we introduce R3, a novel reward modeling framework that is rubric-agnostic, generalizable across evaluation dimensions, and provides interpretable, reasoned score assignments. R3 enables more transparent and flexible evaluation of language models, supporting robust alignment with diverse human values and use cases. Our models, data, and code are available as open source at https://github.com/rubricreward/r3
WikiPersonas: What Can We Learn From Personalized Alignment to Famous People?
May 19, 2025Preference alignment has become a standard pipeline in finetuning models to follow \emph{generic} human preferences. Majority of work seeks to optimize model to produce responses that would be preferable \emph{on average}, simplifying the diverse and often \emph{contradicting} space of human preferences. While research has increasingly focused on personalized alignment: adapting models to individual user preferences, there is a lack of personalized preference dataset which focus on nuanced individual-level preferences. To address this, we introduce WikiPersona: the first fine-grained personalization using well-documented, famous individuals. Our dataset challenges models to align with these personas through an interpretable process: generating verifiable textual descriptions of a persona's background and preferences in addition to alignment. We systematically evaluate different personalization approaches and find that as few-shot prompting with preferences and fine-tuning fail to simultaneously ensure effectiveness and efficiency, using \textit{inferred personal preferences} as prefixes enables effective personalization, especially in topics where preferences clash while leading to more equitable generalization across unseen personas.
NusaAksara: A Multimodal and Multilingual Benchmark for Preserving Indonesian Indigenous Scripts
Feb 25, 2025



Indonesia is rich in languages and scripts. However, most NLP progress has been made using romanized text. In this paper, we present NusaAksara, a novel public benchmark for Indonesian languages that includes their original scripts. Our benchmark covers both text and image modalities and encompasses diverse tasks such as image segmentation, OCR, transliteration, translation, and language identification. Our data is constructed by human experts through rigorous steps. NusaAksara covers 8 scripts across 7 languages, including low-resource languages not commonly seen in NLP benchmarks. Although unsupported by Unicode, the Lampung script is included in this dataset. We benchmark our data across several models, from LLMs and VLMs such as GPT-4o, Llama 3.2, and Aya 23 to task-specific systems such as PP-OCR and LangID, and show that most NLP technologies cannot handle Indonesia's local scripts, with many achieving near-zero performance.
DebiasPI: Inference-time Debiasing by Prompt Iteration of a Text-to-Image Generative Model
Jan 28, 2025



Ethical intervention prompting has emerged as a tool to counter demographic biases of text-to-image generative AI models. Existing solutions either require to retrain the model or struggle to generate images that reflect desired distributions on gender and race. We propose an inference-time process called DebiasPI for Debiasing-by-Prompt-Iteration that provides prompt intervention by enabling the user to control the distributions of individuals' demographic attributes in image generation. DebiasPI keeps track of which attributes have been generated either by probing the internal state of the model or by using external attribute classifiers. Its control loop guides the text-to-image model to select not yet sufficiently represented attributes, With DebiasPI, we were able to create images with equal representations of race and gender that visualize challenging concepts of news headlines. We also experimented with the attributes age, body type, profession, and skin tone, and measured how attributes change when our intervention prompt targets the distribution of an unrelated attribute type. We found, for example, if the text-to-image model is asked to balance racial representation, gender representation improves but the skin tone becomes less diverse. Attempts to cover a wide range of skin colors with various intervention prompts showed that the model struggles to generate the palest skin tones. We conducted various ablation studies, in which we removed DebiasPI's attribute control, that reveal the model's propensity to generate young, male characters. It sometimes visualized career success by generating two-panel images with a pre-success dark-skinned person becoming light-skinned with success, or switching gender from pre-success female to post-success male, thus further motivating ethical intervention prompting with DebiasPI.
IndoToxic2024: A Demographically-Enriched Dataset of Hate Speech and Toxicity Types for Indonesian Language
Jun 27, 2024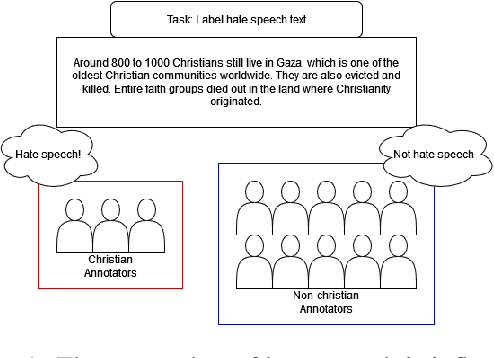



Hate speech poses a significant threat to social harmony. Over the past two years, Indonesia has seen a ten-fold increase in the online hate speech ratio, underscoring the urgent need for effective detection mechanisms. However, progress is hindered by the limited availability of labeled data for Indonesian texts. The condition is even worse for marginalized minorities, such as Shia, LGBTQ, and other ethnic minorities because hate speech is underreported and less understood by detection tools. Furthermore, the lack of accommodation for subjectivity in current datasets compounds this issue. To address this, we introduce IndoToxic2024, a comprehensive Indonesian hate speech and toxicity classification dataset. Comprising 43,692 entries annotated by 19 diverse individuals, the dataset focuses on texts targeting vulnerable groups in Indonesia, specifically during the hottest political event in the country: the presidential election. We establish baselines for seven binary classification tasks, achieving a macro-F1 score of 0.78 with a BERT model (IndoBERTweet) fine-tuned for hate speech classification. Furthermore, we demonstrate how incorporating demographic information can enhance the zero-shot performance of the large language model, gpt-3.5-turbo. However, we also caution that an overemphasis on demographic information can negatively impact the fine-tuned model performance due to data fragmentation.
Learning Translations via Matrix Completion
Jun 19, 2024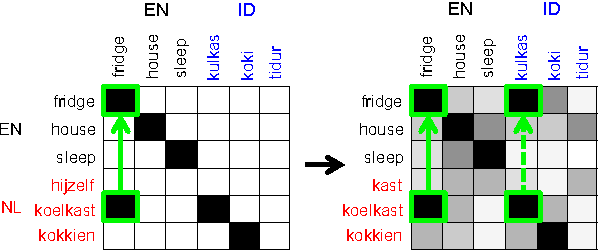
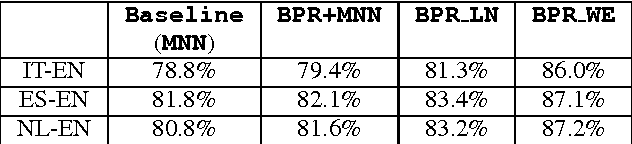
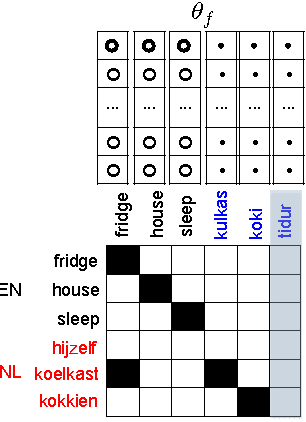

Bilingual Lexicon Induction is the task of learning word translations without bilingual parallel corpora. We model this task as a matrix completion problem, and present an effective and extendable framework for completing the matrix. This method harnesses diverse bilingual and monolingual signals, each of which may be incomplete or noisy. Our model achieves state-of-the-art performance for both high and low resource languages.
* This is a late posting of an old paper as Google Scholar somehow misses indexing the ACL anthology version of the paper
What Linguistic Features and Languages are Important in LLM Translation?
Feb 21, 2024Large Language Models (LLMs) demonstrate strong capability across multiple tasks, including machine translation. Our study focuses on evaluating Llama2's machine translation capabilities and exploring how translation depends on languages in its training data. Our experiments show that the 7B Llama2 model yields above 10 BLEU score for all languages it has seen, but not always for languages it has not seen. Most gains for those unseen languages are observed the most with the model scale compared to using chat versions or adding shot count. Furthermore, our linguistic distance analysis reveals that syntactic similarity is not always the primary linguistic factor in determining translation quality. Interestingly, we discovered that under specific circumstances, some languages, despite having significantly less training data than English, exhibit strong correlations comparable to English. Our discoveries here give new perspectives for the current landscape of LLMs, raising the possibility that LLMs centered around languages other than English may offer a more effective foundation for a multilingual model.