 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Mechanistic Independence: Can Bias Be Removed Without Erasing Demographics?
Dec 23, 2025



We investigate how independent demographic bias mechanisms are from general demographic recognition in language models. Using a multi-task evaluation setup where demographics are associated with names, professions, and education levels, we measure whether models can be debiased while preserving demographic detection capabilities. We compare attribution-based and correlation-based methods for locating bias features. We find that targeted sparse autoencoder feature ablations in Gemma-2-9B reduce bias without degrading recognition performance: attribution-based ablations mitigate race and gender profession stereotypes while preserving name recognition accuracy, whereas correlation-based ablations are more effective for education bias. Qualitative analysis further reveals that removing attribution features in education tasks induces ``prior collapse'', thus increasing overall bias. This highlights the need for dimension-specific interventions. Overall, our results show that demographic bias arises from task-specific mechanisms rather than absolute demographic markers, and that mechanistic inference-time interventions can enable surgical debiasing without compromising core model capabilities.
Gender Inclusivity Fairness Index (GIFI): A Multilevel Framework for Evaluating Gender Diversity in Large Language Models
Jun 18, 2025
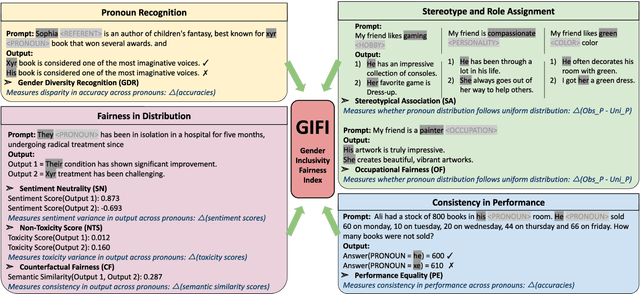

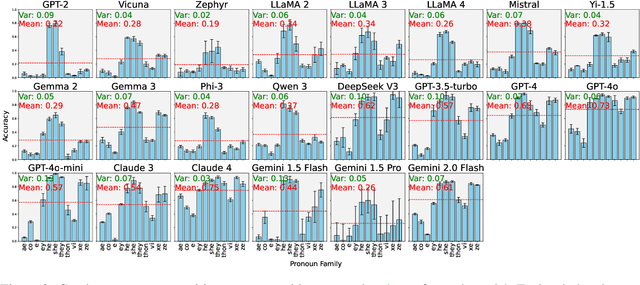
We present a comprehensive evaluation of gender fairness in large language models (LLMs), focusing on their ability to handle both binary and non-binary genders. While previous studies primarily focus on binary gender distinctions, we introduce the Gender Inclusivity Fairness Index (GIFI), a novel and comprehensive metric that quantifies the diverse gender inclusivity of LLMs. GIFI consists of a wide range of evaluations at different levels, from simply probing the model with respect to provided gender pronouns to testing various aspects of model generation and cognitive behaviors under different gender assumptions, revealing biases associated with varying gender identifiers. We conduct extensive evaluations with GIFI on 22 prominent open-source and proprietary LLMs of varying sizes and capabilities, discovering significant variations in LLMs' gender inclusivity. Our study highlights the importance of improving LLMs' inclusivity, providing a critical benchmark for future advancements in gender fairness in generative models.
DebiasPI: Inference-time Debiasing by Prompt Iteration of a Text-to-Image Generative Model
Jan 28, 2025



Ethical intervention prompting has emerged as a tool to counter demographic biases of text-to-image generative AI models. Existing solutions either require to retrain the model or struggle to generate images that reflect desired distributions on gender and race. We propose an inference-time process called DebiasPI for Debiasing-by-Prompt-Iteration that provides prompt intervention by enabling the user to control the distributions of individuals' demographic attributes in image generation. DebiasPI keeps track of which attributes have been generated either by probing the internal state of the model or by using external attribute classifiers. Its control loop guides the text-to-image model to select not yet sufficiently represented attributes, With DebiasPI, we were able to create images with equal representations of race and gender that visualize challenging concepts of news headlines. We also experimented with the attributes age, body type, profession, and skin tone, and measured how attributes change when our intervention prompt targets the distribution of an unrelated attribute type. We found, for example, if the text-to-image model is asked to balance racial representation, gender representation improves but the skin tone becomes less diverse. Attempts to cover a wide range of skin colors with various intervention prompts showed that the model struggles to generate the palest skin tones. We conducted various ablation studies, in which we removed DebiasPI's attribute control, that reveal the model's propensity to generate young, male characters. It sometimes visualized career success by generating two-panel images with a pre-success dark-skinned person becoming light-skinned with success, or switching gender from pre-success female to post-success male, thus further motivating ethical intervention prompting with DebiasPI.
Delving into Decision-based Black-box Attacks on Semantic Segmentation
Feb 02, 2024Semantic segmentation is a fundamental visual task that finds extensive deployment in applications with security-sensitive considerations. Nonetheless, recent work illustrates the adversarial vulnerability of semantic segmentation models to white-box attacks. However, its adversarial robustness against black-box attacks has not been fully explored. In this paper, we present the first exploration of black-box decision-based attacks on semantic segmentation. First, we analyze the challenges that semantic segmentation brings to decision-based attacks through the case study. Then, to address these challenges, we first propose a decision-based attack on semantic segmentation, called Discrete Linear Attack (DLA). Based on random search and proxy index, we utilize the discrete linear noises for perturbation exploration and calibration to achieve efficient attack efficiency. We conduct adversarial robustness evaluation on 5 models from Cityscapes and ADE20K under 8 attacks. DLA shows its formidable power on Cityscapes by dramatically reducing PSPNet's mIoU from an impressive 77.83% to a mere 2.14% with just 50 queries.
ResDiff: Combining CNN and Diffusion Model for Image Super-Resolution
Mar 16, 2023



Adapting the Diffusion Probabilistic Model (DPM) for direct image super-resolution is wasteful, given that a simple Convolutional Neural Network (CNN) can recover the main low-frequency content. Therefore, we present ResDiff, a novel Diffusion Probabilistic Model based on Residual structure for Single Image Super-Resolution (SISR). ResDiff utilizes a combination of a CNN, which restores primary low-frequency components, and a DPM, which predicts the residual between the ground-truth image and the CNN-predicted image. In contrast to the common diffusion-based methods that directly use LR images to guide the noise towards HR space, ResDiff utilizes the CNN's initial prediction to direct the noise towards the residual space between HR space and CNN-predicted space, which not only accelerates the generation process but also acquires superior sample quality. Additionally, a frequency-domain-based loss function for CNN is introduced to facilitate its restoration, and a frequency-domain guided diffusion is designed for DPM on behalf of predicting high-frequency details. The extensive experiments on multiple benchmark datasets demonstrate that ResDiff outperforms previous diffusion-based methods in terms of shorter model convergence time, superior generation quality, and more diverse samples.