 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelving into Decision-based Black-box Attacks on Semantic Segmentation
Feb 02, 2024Semantic segmentation is a fundamental visual task that finds extensive deployment in applications with security-sensitive considerations. Nonetheless, recent work illustrates the adversarial vulnerability of semantic segmentation models to white-box attacks. However, its adversarial robustness against black-box attacks has not been fully explored. In this paper, we present the first exploration of black-box decision-based attacks on semantic segmentation. First, we analyze the challenges that semantic segmentation brings to decision-based attacks through the case study. Then, to address these challenges, we first propose a decision-based attack on semantic segmentation, called Discrete Linear Attack (DLA). Based on random search and proxy index, we utilize the discrete linear noises for perturbation exploration and calibration to achieve efficient attack efficiency. We conduct adversarial robustness evaluation on 5 models from Cityscapes and ADE20K under 8 attacks. DLA shows its formidable power on Cityscapes by dramatically reducing PSPNet's mIoU from an impressive 77.83% to a mere 2.14% with just 50 queries.
Towards End-to-End Unsupervised Saliency Detection with Self-Supervised Top-Down Context
Oct 14, 2023
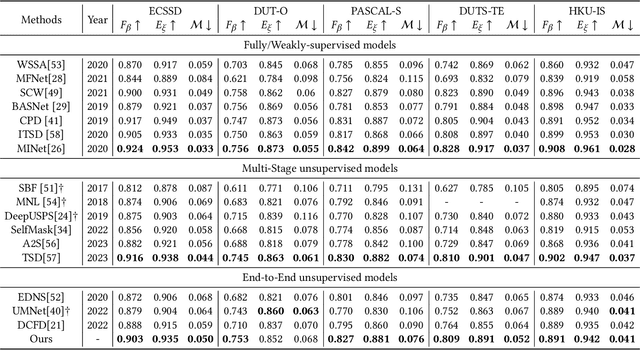

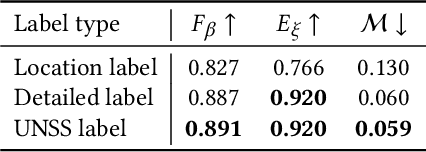
Unsupervised salient object detection aims to detect salient objects without using supervision signals eliminating the tedious task of manually labeling salient objects. To improve training efficiency, end-to-end methods for USOD have been proposed as a promising alternative. However, current solutions rely heavily on noisy handcraft labels and fail to mine rich semantic information from deep features. In this paper, we propose a self-supervised end-to-end salient object detection framework via top-down context. Specifically, motivated by contrastive learning, we exploit the self-localization from the deepest feature to construct the location maps which are then leveraged to learn the most instructive segmentation guidance. Further considering the lack of detailed information in deepest features, we exploit the detail-boosting refiner module to enrich the location labels with details. Moreover, we observe that due to lack of supervision, current unsupervised saliency models tend to detect non-salient objects that are salient in some other samples of corresponding scenarios. To address this widespread issue, we design a novel Unsupervised Non-Salient Suppression (UNSS) method developing the ability to ignore non-salient objects. Extensive experiments on benchmark datasets demonstrate that our method achieves leading performance among the recent end-to-end methods and most of the multi-stage solutions. The code is available.
CiCo: Domain-Aware Sign Language Retrieval via Cross-Lingual Contrastive Learning
Mar 22, 2023



This work focuses on sign language retrieval-a recently proposed task for sign language understanding. Sign language retrieval consists of two sub-tasks: text-to-sign-video (T2V) retrieval and sign-video-to-text (V2T) retrieval. Different from traditional video-text retrieval, sign language videos, not only contain visual signals but also carry abundant semantic meanings by themselves due to the fact that sign languages are also natural languages. Considering this character, we formulate sign language retrieval as a cross-lingual retrieval problem as well as a video-text retrieval task. Concretely, we take into account the linguistic properties of both sign languages and natural languages, and simultaneously identify the fine-grained cross-lingual (i.e., sign-to-word) mappings while contrasting the texts and the sign videos in a joint embedding space. This process is termed as cross-lingual contrastive learning. Another challenge is raised by the data scarcity issue-sign language datasets are orders of magnitude smaller in scale than that of speech recognition. We alleviate this issue by adopting a domain-agnostic sign encoder pre-trained on large-scale sign videos into the target domain via pseudo-labeling. Our framework, termed as domain-aware sign language retrieval via Cross-lingual Contrastive learning or CiCo for short, outperforms the pioneering method by large margins on various datasets, e.g., +22.4 T2V and +28.0 V2T R@1 improvements on How2Sign dataset, and +13.7 T2V and +17.1 V2T R@1 improvements on PHOENIX-2014T dataset. Code and models are available at: https://github.com/FangyunWei/SLRT.
Dual Path Learning for Domain Adaptation of Semantic Segmentation
Aug 13, 2021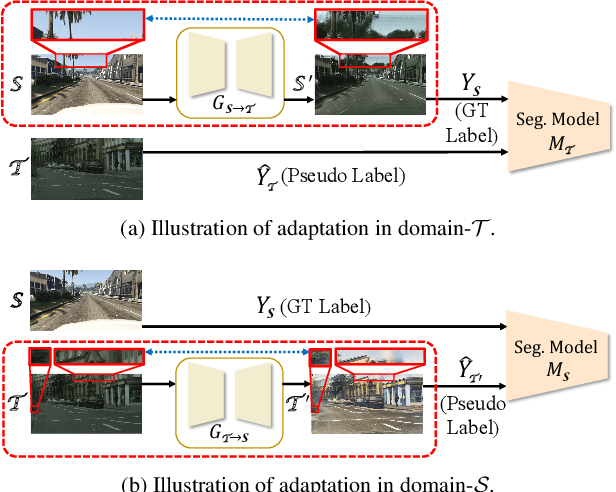
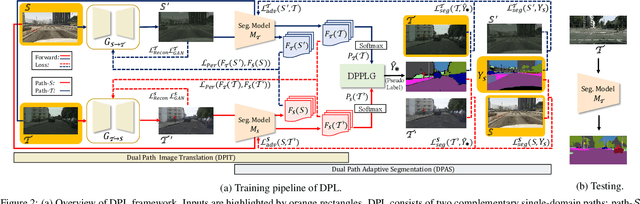
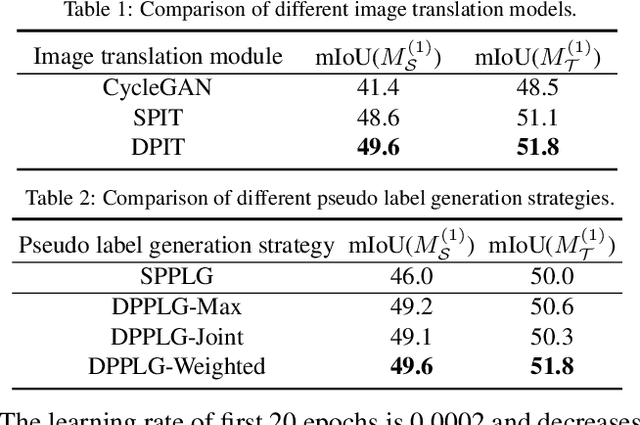

Domain adaptation for semantic segmentation enables to alleviate the need for large-scale pixel-wise annotations. Recently, self-supervised learning (SSL) with a combination of image-to-image translation shows great effectiveness in adaptive segmentation. The most common practice is to perform SSL along with image translation to well align a single domain (the source or target). However, in this single-domain paradigm, unavoidable visual inconsistency raised by image translation may affect subsequent learning. In this paper, based on the observation that domain adaptation frameworks performed in the source and target domain are almost complementary in terms of image translation and SSL, we propose a novel dual path learning (DPL) framework to alleviate visual inconsistency. Concretely, DPL contains two complementary and interactive single-domain adaptation pipelines aligned in source and target domain respectively. The inference of DPL is extremely simple, only one segmentation model in the target domain is employed. Novel technologies such as dual path image translation and dual path adaptive segmentation are proposed to make two paths promote each other in an interactive manner. Experiments on GTA5$\rightarrow$Cityscapes and SYNTHIA$\rightarrow$Cityscapes scenarios demonstrate the superiority of our DPL model over the state-of-the-art methods. The code and models are available at: \url{https://github.com/royee182/DPL}