 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReferring Camouflaged Object Detection With Multi-Context Overlapped Windows Cross-Attention
Nov 17, 2025Referring camouflaged object detection (Ref-COD) aims to identify hidden objects by incorporating reference information such as images and text descriptions. Previous research has transformed reference images with salient objects into one-dimensional prompts, yielding significant results. We explore ways to enhance performance through multi-context fusion of rich salient image features and camouflaged object features. Therefore, we propose RFMNet, which utilizes features from multiple encoding stages of the reference salient images and performs interactive fusion with the camouflage features at the corresponding encoding stages. Given that the features in salient object images contain abundant object-related detail information, performing feature fusion within local areas is more beneficial for detecting camouflaged objects. Therefore, we propose an Overlapped Windows Cross-attention mechanism to enable the model to focus more attention on the local information matching based on reference features. Besides, we propose the Referring Feature Aggregation (RFA) module to decode and segment the camouflaged objects progressively. Extensive experiments on the Ref-COD benchmark demonstrate that our method achieves state-of-the-art performance.
A Holistically Point-guided Text Framework for Weakly-Supervised Camouflaged Object Detection
Jan 10, 2025



Weakly-Supervised Camouflaged Object Detection (WSCOD) has gained popularity for its promise to train models with weak labels to segment objects that visually blend into their surroundings. Recently, some methods using sparsely-annotated supervision shown promising results through scribbling in WSCOD, while point-text supervision remains underexplored. Hence, this paper introduces a novel holistically point-guided text framework for WSCOD by decomposing into three phases: segment, choose, train. Specifically, we propose Point-guided Candidate Generation (PCG), where the point's foreground serves as a correction for the text path to explicitly correct and rejuvenate the loss detection object during the mask generation process (SEGMENT). We also introduce a Qualified Candidate Discriminator (QCD) to choose the optimal mask from a given text prompt using CLIP (CHOOSE), and employ the chosen pseudo mask for training with a self-supervised Vision Transformer (TRAIN). Additionally, we developed a new point-supervised dataset (P2C-COD) and a text-supervised dataset (T-COD). Comprehensive experiments on four benchmark datasets demonstrate our method outperforms state-of-the-art methods by a large margin, and also outperforms some existing fully-supervised camouflaged object detection methods.
Towards End-to-End Unsupervised Saliency Detection with Self-Supervised Top-Down Context
Oct 14, 2023
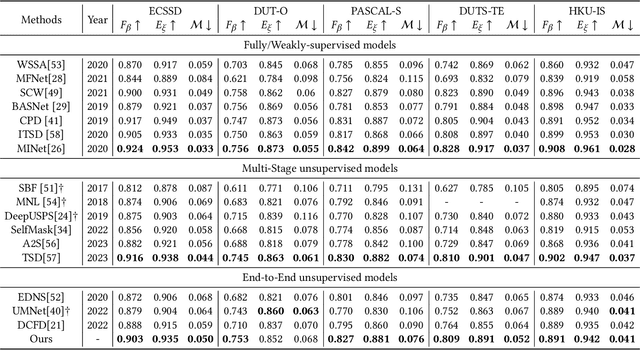

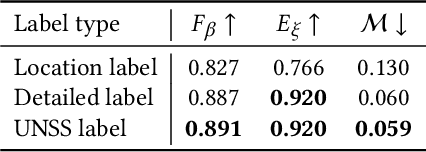
Unsupervised salient object detection aims to detect salient objects without using supervision signals eliminating the tedious task of manually labeling salient objects. To improve training efficiency, end-to-end methods for USOD have been proposed as a promising alternative. However, current solutions rely heavily on noisy handcraft labels and fail to mine rich semantic information from deep features. In this paper, we propose a self-supervised end-to-end salient object detection framework via top-down context. Specifically, motivated by contrastive learning, we exploit the self-localization from the deepest feature to construct the location maps which are then leveraged to learn the most instructive segmentation guidance. Further considering the lack of detailed information in deepest features, we exploit the detail-boosting refiner module to enrich the location labels with details. Moreover, we observe that due to lack of supervision, current unsupervised saliency models tend to detect non-salient objects that are salient in some other samples of corresponding scenarios. To address this widespread issue, we design a novel Unsupervised Non-Salient Suppression (UNSS) method developing the ability to ignore non-salient objects. Extensive experiments on benchmark datasets demonstrate that our method achieves leading performance among the recent end-to-end methods and most of the multi-stage solutions. The code is available.
Weakly Supervised Video Salient Object Detection via Point Supervision
Jul 15, 2022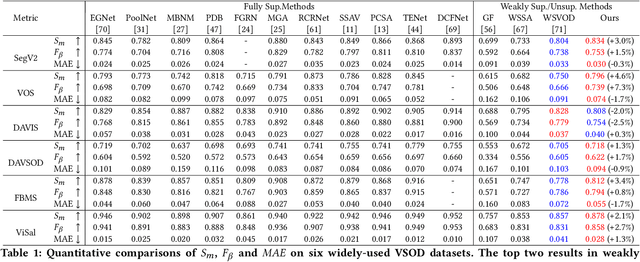
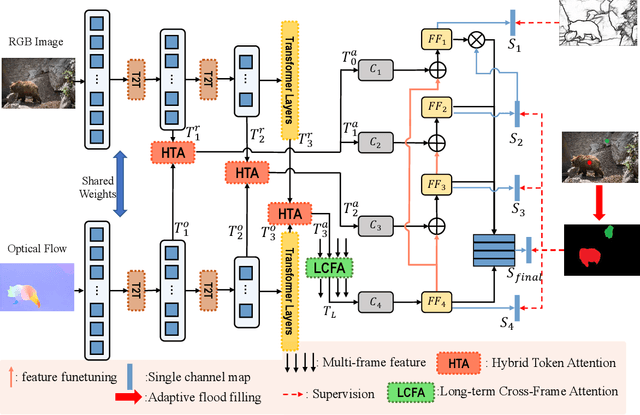
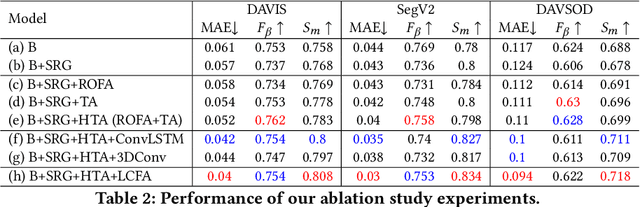

Video salient object detection models trained on pixel-wise dense annotation have achieved excellent performance, yet obtaining pixel-by-pixel annotated datasets is laborious. Several works attempt to use scribble annotations to mitigate this problem, but point supervision as a more labor-saving annotation method (even the most labor-saving method among manual annotation methods for dense prediction), has not been explored. In this paper, we propose a strong baseline model based on point supervision. To infer saliency maps with temporal information, we mine inter-frame complementary information from short-term and long-term perspectives, respectively. Specifically, we propose a hybrid token attention module, which mixes optical flow and image information from orthogonal directions, adaptively highlighting critical optical flow information (channel dimension) and critical token information (spatial dimension). To exploit long-term cues, we develop the Long-term Cross-Frame Attention module (LCFA), which assists the current frame in inferring salient objects based on multi-frame tokens. Furthermore, we label two point-supervised datasets, P-DAVIS and P-DAVSOD, by relabeling the DAVIS and the DAVSOD dataset. Experiments on the six benchmark datasets illustrate our method outperforms the previous state-of-the-art weakly supervised methods and even is comparable with some fully supervised approaches. Source code and datasets are available.