 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimMIL: A Universal Weakly Supervised Pre-Training Framework for Multi-Instance Learning in Whole Slide Pathology Images
May 10, 2025Various multi-instance learning (MIL) based approaches have been developed and successfully applied to whole-slide pathological images (WSI). Existing MIL methods emphasize the importance of feature aggregators, but largely neglect the instance-level representation learning. They assume that the availability of a pre-trained feature extractor can be directly utilized or fine-tuned, which is not always the case. This paper proposes to pre-train feature extractor for MIL via a weakly-supervised scheme, i.e., propagating the weak bag-level labels to the corresponding instances for supervised learning. To learn effective features for MIL, we further delve into several key components, including strong data augmentation, a non-linear prediction head and the robust loss function. We conduct experiments on common large-scale WSI datasets and find it achieves better performance than other pre-training schemes (e.g., ImageNet pre-training and self-supervised learning) in different downstream tasks. We further show the compatibility and scalability of the proposed scheme by deploying it in fine-tuning the pathological-specific models and pre-training on merged multiple datasets. To our knowledge, this is the first work focusing on the representation learning for MIL.
Towards End-to-End Unsupervised Saliency Detection with Self-Supervised Top-Down Context
Oct 14, 2023
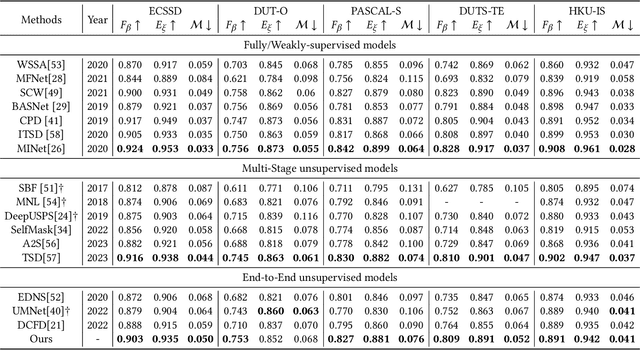

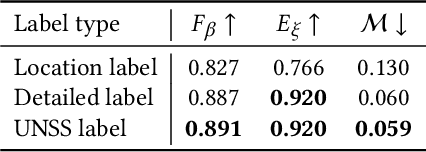
Unsupervised salient object detection aims to detect salient objects without using supervision signals eliminating the tedious task of manually labeling salient objects. To improve training efficiency, end-to-end methods for USOD have been proposed as a promising alternative. However, current solutions rely heavily on noisy handcraft labels and fail to mine rich semantic information from deep features. In this paper, we propose a self-supervised end-to-end salient object detection framework via top-down context. Specifically, motivated by contrastive learning, we exploit the self-localization from the deepest feature to construct the location maps which are then leveraged to learn the most instructive segmentation guidance. Further considering the lack of detailed information in deepest features, we exploit the detail-boosting refiner module to enrich the location labels with details. Moreover, we observe that due to lack of supervision, current unsupervised saliency models tend to detect non-salient objects that are salient in some other samples of corresponding scenarios. To address this widespread issue, we design a novel Unsupervised Non-Salient Suppression (UNSS) method developing the ability to ignore non-salient objects. Extensive experiments on benchmark datasets demonstrate that our method achieves leading performance among the recent end-to-end methods and most of the multi-stage solutions. The code is available.