 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRSAgent: Learning to Reason and Act for Text-Guided Segmentation via Multi-Turn Tool Invocations
Dec 30, 2025Text-guided object segmentation requires both cross-modal reasoning and pixel grounding abilities. Most recent methods treat text-guided segmentation as one-shot grounding, where the model predicts pixel prompts in a single forward pass to drive an external segmentor, which limits verification, refocusing and refinement when initial localization is wrong. To address this limitation, we propose RSAgent, an agentic Multimodal Large Language Model (MLLM) which interleaves reasoning and action for segmentation via multi-turn tool invocations. RSAgent queries a segmentation toolbox, observes visual feedback, and revises its spatial hypothesis using historical observations to re-localize targets and iteratively refine masks. We further build a data pipeline to synthesize multi-turn reasoning segmentation trajectories, and train RSAgent with a two-stage framework: cold-start supervised fine-tuning followed by agentic reinforcement learning with fine-grained, task-specific rewards. Extensive experiments show that RSAgent achieves a zero-shot performance of 66.5% gIoU on ReasonSeg test, improving over Seg-Zero-7B by 9%, and reaches 81.5% cIoU on RefCOCOg, demonstrating state-of-the-art performance on both in-domain and out-of-domain benchmarks.
Collaborative Reconstruction and Repair for Multi-class Industrial Anomaly Detection
Dec 12, 2025Industrial anomaly detection is a challenging open-set task that aims to identify unknown anomalous patterns deviating from normal data distribution. To avoid the significant memory consumption and limited generalizability brought by building separate models per class, we focus on developing a unified framework for multi-class anomaly detection. However, under this challenging setting, conventional reconstruction-based networks often suffer from an identity mapping problem, where they directly replicate input features regardless of whether they are normal or anomalous, resulting in detection failures. To address this issue, this study proposes a novel framework termed Collaborative Reconstruction and Repair (CRR), which transforms the reconstruction to repairation. First, we optimize the decoder to reconstruct normal samples while repairing synthesized anomalies. Consequently, it generates distinct representations for anomalous regions and similar representations for normal areas compared to the encoder's output. Second, we implement feature-level random masking to ensure that the representations from decoder contain sufficient local information. Finally, to minimize detection errors arising from the discrepancies between feature representations from the encoder and decoder, we train a segmentation network supervised by synthetic anomaly masks, thereby enhancing localization performance. Extensive experiments on industrial datasets that CRR effectively mitigates the identity mapping issue and achieves state-of-the-art performance in multi-class industrial anomaly detection.
Referring Camouflaged Object Detection With Multi-Context Overlapped Windows Cross-Attention
Nov 17, 2025Referring camouflaged object detection (Ref-COD) aims to identify hidden objects by incorporating reference information such as images and text descriptions. Previous research has transformed reference images with salient objects into one-dimensional prompts, yielding significant results. We explore ways to enhance performance through multi-context fusion of rich salient image features and camouflaged object features. Therefore, we propose RFMNet, which utilizes features from multiple encoding stages of the reference salient images and performs interactive fusion with the camouflage features at the corresponding encoding stages. Given that the features in salient object images contain abundant object-related detail information, performing feature fusion within local areas is more beneficial for detecting camouflaged objects. Therefore, we propose an Overlapped Windows Cross-attention mechanism to enable the model to focus more attention on the local information matching based on reference features. Besides, we propose the Referring Feature Aggregation (RFA) module to decode and segment the camouflaged objects progressively. Extensive experiments on the Ref-COD benchmark demonstrate that our method achieves state-of-the-art performance.
Commonality in Few: Few-Shot Multimodal Anomaly Detection via Hypergraph-Enhanced Memory
Nov 16, 2025
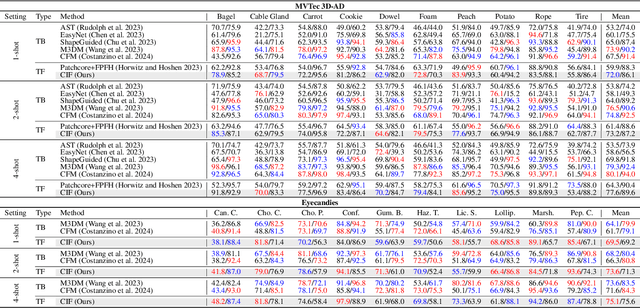
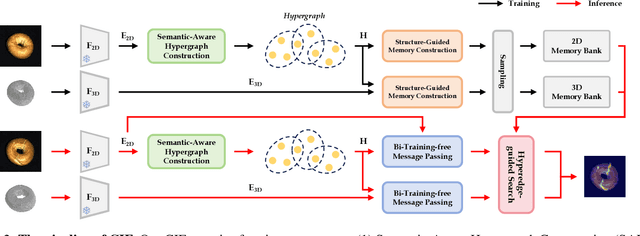

Few-shot multimodal industrial anomaly detection is a critical yet underexplored task, offering the ability to quickly adapt to complex industrial scenarios. In few-shot settings, insufficient training samples often fail to cover the diverse patterns present in test samples. This challenge can be mitigated by extracting structural commonality from a small number of training samples. In this paper, we propose a novel few-shot unsupervised multimodal industrial anomaly detection method based on structural commonality, CIF (Commonality In Few). To extract intra-class structural information, we employ hypergraphs, which are capable of modeling higher-order correlations, to capture the structural commonality within training samples, and use a memory bank to store this intra-class structural prior. Firstly, we design a semantic-aware hypergraph construction module tailored for single-semantic industrial images, from which we extract common structures to guide the construction of the memory bank. Secondly, we use a training-free hypergraph message passing module to update the visual features of test samples, reducing the distribution gap between test features and features in the memory bank. We further propose a hyperedge-guided memory search module, which utilizes structural information to assist the memory search process and reduce the false positive rate. Experimental results on the MVTec 3D-AD dataset and the Eyecandies dataset show that our method outperforms the state-of-the-art (SOTA) methods in few-shot settings. Code is available at https://github.com/Sunny5250/CIF.
HSS-IAD: A Heterogeneous Same-Sort Industrial Anomaly Detection Dataset
Apr 17, 2025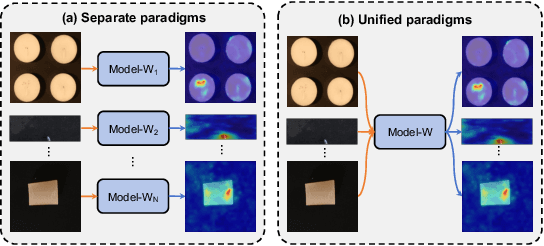


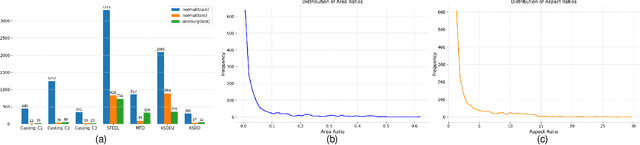
Multi-class Unsupervised Anomaly Detection algorithms (MUAD) are receiving increasing attention due to their relatively low deployment costs and improved training efficiency. However, the real-world effectiveness of MUAD methods is questioned due to limitations in current Industrial Anomaly Detection (IAD) datasets. These datasets contain numerous classes that are unlikely to be produced by the same factory and fail to cover multiple structures or appearances. Additionally, the defects do not reflect real-world characteristics. Therefore, we introduce the Heterogeneous Same-Sort Industrial Anomaly Detection (HSS-IAD) dataset, which contains 8,580 images of metallic-like industrial parts and precise anomaly annotations. These parts exhibit variations in structure and appearance, with subtle defects that closely resemble the base materials. We also provide foreground images for synthetic anomaly generation. Finally, we evaluate popular IAD methods on this dataset under multi-class and class-separated settings, demonstrating its potential to bridge the gap between existing datasets and real factory conditions. The dataset is available at https://github.com/Qiqigeww/HSS-IAD-Dataset.
Search is All You Need for Few-shot Anomaly Detection
Apr 16, 2025



Few-shot anomaly detection (FSAD) has emerged as a crucial yet challenging task in industrial inspection, where normal distribution modeling must be accomplished with only a few normal images. While existing approaches typically employ multi-modal foundation models combining language and vision modalities for prompt-guided anomaly detection, these methods often demand sophisticated prompt engineering and extensive manual tuning. In this paper, we demonstrate that a straightforward nearest-neighbor search framework can surpass state-of-the-art performance in both single-class and multi-class FSAD scenarios. Our proposed method, VisionAD, consists of four simple yet essential components: (1) scalable vision foundation models that extract universal and discriminative features; (2) dual augmentation strategies - support augmentation to enhance feature matching adaptability and query augmentation to address the oversights of single-view prediction; (3) multi-layer feature integration that captures both low-frequency global context and high-frequency local details with minimal computational overhead; and (4) a class-aware visual memory bank enabling efficient one-for-all multi-class detection. Extensive evaluations across MVTec-AD, VisA, and Real-IAD benchmarks demonstrate VisionAD's exceptional performance. Using only 1 normal images as support, our method achieves remarkable image-level AUROC scores of 97.4%, 94.8%, and 70.8% respectively, outperforming current state-of-the-art approaches by significant margins (+1.6%, +3.2%, and +1.4%). The training-free nature and superior few-shot capabilities of VisionAD make it particularly appealing for real-world applications where samples are scarce or expensive to obtain. Code is available at https://github.com/Qiqigeww/VisionAD.
MSVCOD:A Large-Scale Multi-Scene Dataset for Video Camouflage Object Detection
Feb 19, 2025

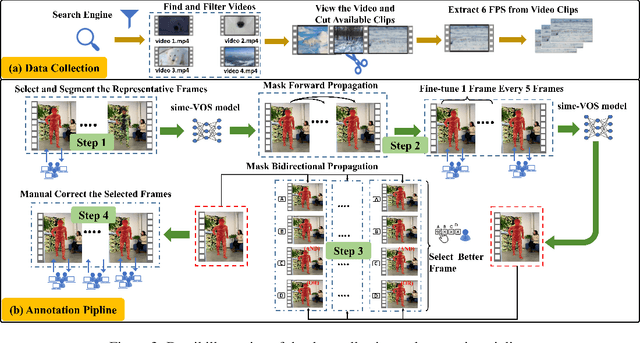
Video Camouflaged Object Detection (VCOD) is a challenging task which aims to identify objects that seamlessly concealed within the background in videos. The dynamic properties of video enable detection of camouflaged objects through motion cues or varied perspectives. Previous VCOD datasets primarily contain animal objects, limiting the scope of research to wildlife scenarios. However, the applications of VCOD extend beyond wildlife and have significant implications in security, art, and medical fields. Addressing this problem, we construct a new large-scale multi-domain VCOD dataset MSVCOD. To achieve high-quality annotations, we design a semi-automatic iterative annotation pipeline that reduces costs while maintaining annotation accuracy. Our MSVCOD is the largest VCOD dataset to date, introducing multiple object categories including human, animal, medical, and vehicle objects for the first time, while also expanding background diversity across various environments. This expanded scope increases the practical applicability of the VCOD task in camouflaged object detection. Alongside this dataset, we introduce a one-steam video camouflage object detection model that performs both feature extraction and information fusion without additional motion feature fusion modules. Our framework achieves state-of-the-art results on the existing VCOD animal dataset and the proposed MSVCOD. The dataset and code will be made publicly available.
A Holistically Point-guided Text Framework for Weakly-Supervised Camouflaged Object Detection
Jan 10, 2025



Weakly-Supervised Camouflaged Object Detection (WSCOD) has gained popularity for its promise to train models with weak labels to segment objects that visually blend into their surroundings. Recently, some methods using sparsely-annotated supervision shown promising results through scribbling in WSCOD, while point-text supervision remains underexplored. Hence, this paper introduces a novel holistically point-guided text framework for WSCOD by decomposing into three phases: segment, choose, train. Specifically, we propose Point-guided Candidate Generation (PCG), where the point's foreground serves as a correction for the text path to explicitly correct and rejuvenate the loss detection object during the mask generation process (SEGMENT). We also introduce a Qualified Candidate Discriminator (QCD) to choose the optimal mask from a given text prompt using CLIP (CHOOSE), and employ the chosen pseudo mask for training with a self-supervised Vision Transformer (TRAIN). Additionally, we developed a new point-supervised dataset (P2C-COD) and a text-supervised dataset (T-COD). Comprehensive experiments on four benchmark datasets demonstrate our method outperforms state-of-the-art methods by a large margin, and also outperforms some existing fully-supervised camouflaged object detection methods.
P3S-Diffusion:A Selective Subject-driven Generation Framework via Point Supervision
Dec 27, 2024
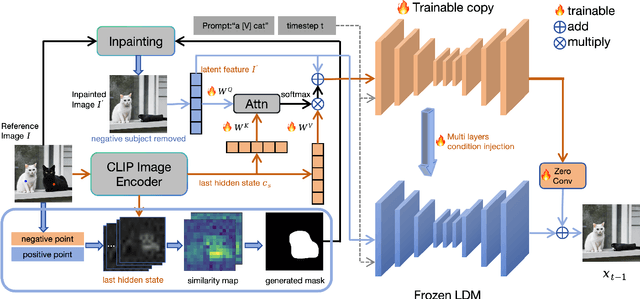
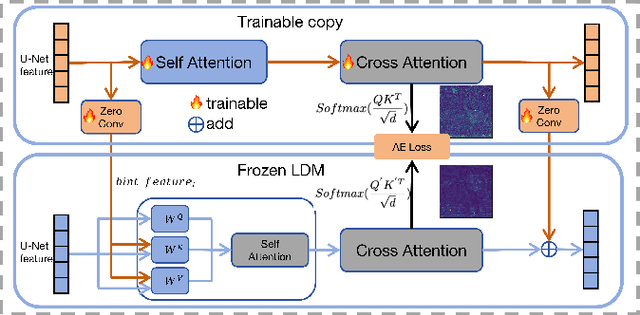

Recent research in subject-driven generation increasingly emphasizes the importance of selective subject features. Nevertheless, accurately selecting the content in a given reference image still poses challenges, especially when selecting the similar subjects in an image (e.g., two different dogs). Some methods attempt to use text prompts or pixel masks to isolate specific elements. However, text prompts often fall short in precisely describing specific content, and pixel masks are often expensive. To address this, we introduce P3S-Diffusion, a novel architecture designed for context-selected subject-driven generation via point supervision. P3S-Diffusion leverages minimal cost label (e.g., points) to generate subject-driven images. During fine-tuning, it can generate an expanded base mask from these points, obviating the need for additional segmentation models. The mask is employed for inpainting and aligning with subject representation. The P3S-Diffusion preserves fine features of the subjects through Multi-layers Condition Injection. Enhanced by the Attention Consistency Loss for improved training, extensive experiments demonstrate its excellent feature preservation and image generation capabilities.
General Compression Framework for Efficient Transformer Object Tracking
Sep 26, 2024



Transformer-based trackers have established a dominant role in the field of visual object tracking. While these trackers exhibit promising performance, their deployment on resource-constrained devices remains challenging due to inefficiencies. To improve the inference efficiency and reduce the computation cost, prior approaches have aimed to either design lightweight trackers or distill knowledge from larger teacher models into more compact student trackers. However, these solutions often sacrifice accuracy for speed. Thus, we propose a general model compression framework for efficient transformer object tracking, named CompressTracker, to reduce the size of a pre-trained tracking model into a lightweight tracker with minimal performance degradation. Our approach features a novel stage division strategy that segments the transformer layers of the teacher model into distinct stages, enabling the student model to emulate each corresponding teacher stage more effectively. Additionally, we also design a unique replacement training technique that involves randomly substituting specific stages in the student model with those from the teacher model, as opposed to training the student model in isolation. Replacement training enhances the student model's ability to replicate the teacher model's behavior. To further forcing student model to emulate teacher model, we incorporate prediction guidance and stage-wise feature mimicking to provide additional supervision during the teacher model's compression process. Our framework CompressTracker is structurally agnostic, making it compatible with any transformer architecture. We conduct a series of experiment to verify the effectiveness and generalizability of CompressTracker. Our CompressTracker-4 with 4 transformer layers, which is compressed from OSTrack, retains about 96% performance on LaSOT (66.1% AUC) while achieves 2.17x speed up.