 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearth Transformer: A Transformer Architecture Incorporating Earth's Geospheric Physical Priors for Global Mid-Range Weather Forecasting
Jan 14, 2026Accurate global medium-range weather forecasting is fundamental to Earth system science. Most existing Transformer-based forecasting models adopt vision-centric architectures that neglect the Earth's spherical geometry and zonal periodicity. In addition, conventional autoregressive training is computationally expensive and limits forecast horizons due to error accumulation. To address these challenges, we propose the Shifted Earth Transformer (Searth Transformer), a physics-informed architecture that incorporates zonal periodicity and meridional boundaries into window-based self-attention for physically consistent global information exchange. We further introduce a Relay Autoregressive (RAR) fine-tuning strategy that enables learning long-range atmospheric evolution under constrained memory and computational budgets. Based on these methods, we develop YanTian, a global medium-range weather forecasting model. YanTian achieves higher accuracy than the high-resolution forecast of the European Centre for Medium-Range Weather Forecasts and performs competitively with state-of-the-art AI models at one-degree resolution, while requiring roughly 200 times lower computational cost than standard autoregressive fine-tuning. Furthermore, YanTian attains a longer skillful forecast lead time for Z500 (10.3 days) than HRES (9 days). Beyond weather forecasting, this work establishes a robust algorithmic foundation for predictive modeling of complex global-scale geophysical circulation systems, offering new pathways for Earth system science.
Commonality in Few: Few-Shot Multimodal Anomaly Detection via Hypergraph-Enhanced Memory
Nov 16, 2025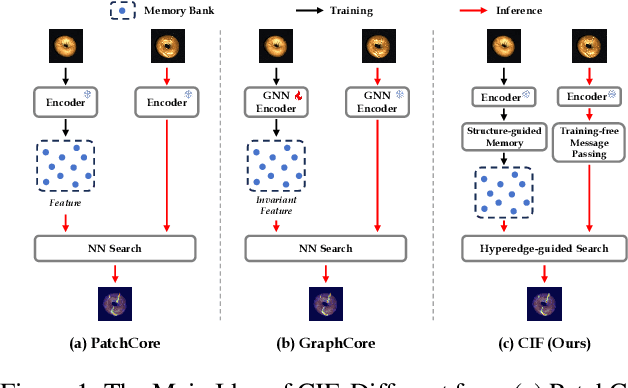
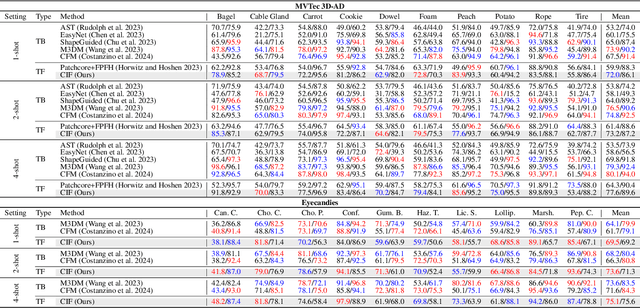
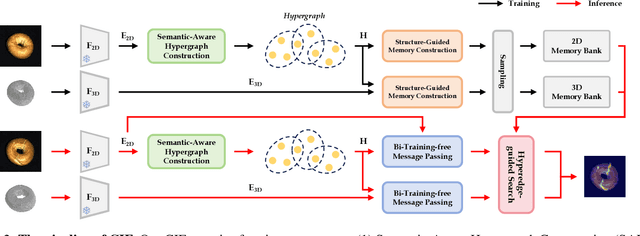

Few-shot multimodal industrial anomaly detection is a critical yet underexplored task, offering the ability to quickly adapt to complex industrial scenarios. In few-shot settings, insufficient training samples often fail to cover the diverse patterns present in test samples. This challenge can be mitigated by extracting structural commonality from a small number of training samples. In this paper, we propose a novel few-shot unsupervised multimodal industrial anomaly detection method based on structural commonality, CIF (Commonality In Few). To extract intra-class structural information, we employ hypergraphs, which are capable of modeling higher-order correlations, to capture the structural commonality within training samples, and use a memory bank to store this intra-class structural prior. Firstly, we design a semantic-aware hypergraph construction module tailored for single-semantic industrial images, from which we extract common structures to guide the construction of the memory bank. Secondly, we use a training-free hypergraph message passing module to update the visual features of test samples, reducing the distribution gap between test features and features in the memory bank. We further propose a hyperedge-guided memory search module, which utilizes structural information to assist the memory search process and reduce the false positive rate. Experimental results on the MVTec 3D-AD dataset and the Eyecandies dataset show that our method outperforms the state-of-the-art (SOTA) methods in few-shot settings. Code is available at https://github.com/Sunny5250/CIF.
SafeWork-R1: Coevolving Safety and Intelligence under the AI-45$^{\circ}$ Law
Jul 24, 2025



We introduce SafeWork-R1, a cutting-edge multimodal reasoning model that demonstrates the coevolution of capabilities and safety. It is developed by our proposed SafeLadder framework, which incorporates large-scale, progressive, safety-oriented reinforcement learning post-training, supported by a suite of multi-principled verifiers. Unlike previous alignment methods such as RLHF that simply learn human preferences, SafeLadder enables SafeWork-R1 to develop intrinsic safety reasoning and self-reflection abilities, giving rise to safety `aha' moments. Notably, SafeWork-R1 achieves an average improvement of $46.54\%$ over its base model Qwen2.5-VL-72B on safety-related benchmarks without compromising general capabilities, and delivers state-of-the-art safety performance compared to leading proprietary models such as GPT-4.1 and Claude Opus 4. To further bolster its reliability, we implement two distinct inference-time intervention methods and a deliberative search mechanism, enforcing step-level verification. Finally, we further develop SafeWork-R1-InternVL3-78B, SafeWork-R1-DeepSeek-70B, and SafeWork-R1-Qwen2.5VL-7B. All resulting models demonstrate that safety and capability can co-evolve synergistically, highlighting the generalizability of our framework in building robust, reliable, and trustworthy general-purpose AI.
HSS-IAD: A Heterogeneous Same-Sort Industrial Anomaly Detection Dataset
Apr 17, 2025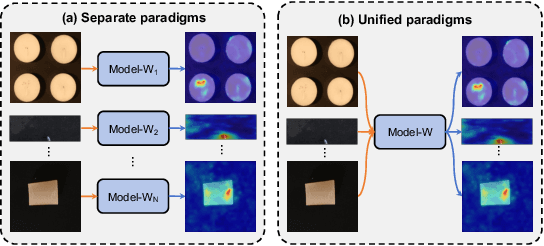


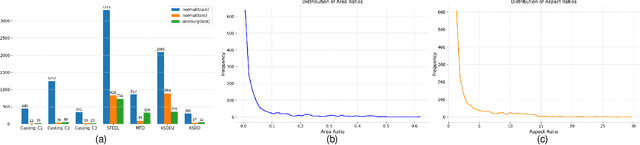
Multi-class Unsupervised Anomaly Detection algorithms (MUAD) are receiving increasing attention due to their relatively low deployment costs and improved training efficiency. However, the real-world effectiveness of MUAD methods is questioned due to limitations in current Industrial Anomaly Detection (IAD) datasets. These datasets contain numerous classes that are unlikely to be produced by the same factory and fail to cover multiple structures or appearances. Additionally, the defects do not reflect real-world characteristics. Therefore, we introduce the Heterogeneous Same-Sort Industrial Anomaly Detection (HSS-IAD) dataset, which contains 8,580 images of metallic-like industrial parts and precise anomaly annotations. These parts exhibit variations in structure and appearance, with subtle defects that closely resemble the base materials. We also provide foreground images for synthetic anomaly generation. Finally, we evaluate popular IAD methods on this dataset under multi-class and class-separated settings, demonstrating its potential to bridge the gap between existing datasets and real factory conditions. The dataset is available at https://github.com/Qiqigeww/HSS-IAD-Dataset.
A Mousetrap: Fooling Large Reasoning Models for Jailbreak with Chain of Iterative Chaos
Feb 19, 2025Large Reasoning Models (LRMs) have significantly advanced beyond traditional Large Language Models (LLMs) with their exceptional logical reasoning capabilities, yet these improvements introduce heightened safety risks. When subjected to jailbreak attacks, their ability to generate more targeted and organized content can lead to greater harm. Although some studies claim that reasoning enables safer LRMs against existing LLM attacks, they overlook the inherent flaws within the reasoning process itself. To address this gap, we propose the first jailbreak attack targeting LRMs, exploiting their unique vulnerabilities stemming from the advanced reasoning capabilities. Specifically, we introduce a Chaos Machine, a novel component to transform attack prompts with diverse one-to-one mappings. The chaos mappings iteratively generated by the machine are embedded into the reasoning chain, which strengthens the variability and complexity and also promotes a more robust attack. Based on this, we construct the Mousetrap framework, which makes attacks projected into nonlinear-like low sample spaces with mismatched generalization enhanced. Also, due to the more competing objectives, LRMs gradually maintain the inertia of unpredictable iterative reasoning and fall into our trap. Success rates of the Mousetrap attacking o1-mini, claude-sonnet and gemini-thinking are as high as 96%, 86% and 98% respectively on our toxic dataset Trotter. On benchmarks such as AdvBench, StrongREJECT, and HarmBench, attacking claude-sonnet, well-known for its safety, Mousetrap can astonishingly achieve success rates of 87.5%, 86.58% and 93.13% respectively. Attention: This paper contains inappropriate, offensive and harmful content.
Component-aware Unsupervised Logical Anomaly Generation for Industrial Anomaly Detection
Feb 17, 2025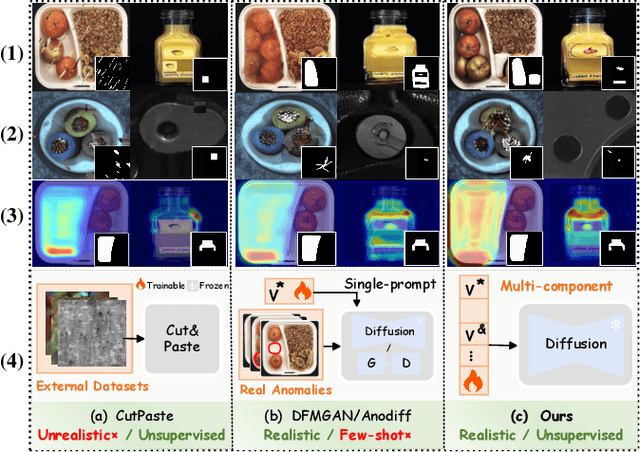
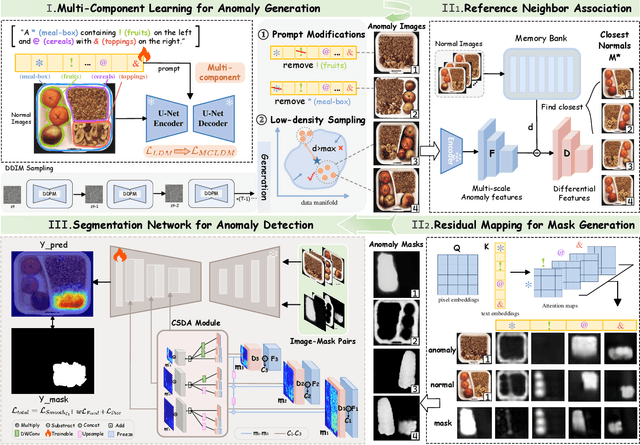
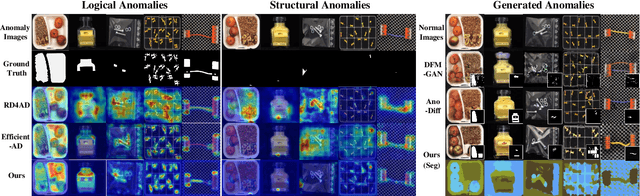

Anomaly detection is critical in industrial manufacturing for ensuring product quality and improving efficiency in automated processes. The scarcity of anomalous samples limits traditional detection methods, making anomaly generation essential for expanding the data repository. However, recent generative models often produce unrealistic anomalies increasing false positives, or require real-world anomaly samples for training. In this work, we treat anomaly generation as a compositional problem and propose ComGEN, a component-aware and unsupervised framework that addresses the gap in logical anomaly generation. Our method comprises a multi-component learning strategy to disentangle visual components, followed by subsequent generation editing procedures. Disentangled text-to-component pairs, revealing intrinsic logical constraints, conduct attention-guided residual mapping and model training with iteratively matched references across multiple scales. Experiments on the MVTecLOCO dataset confirm the efficacy of ComGEN, achieving the best AUROC score of 91.2%. Additional experiments on the real-world scenario of Diesel Engine and widely-used MVTecAD dataset demonstrate significant performance improvements when integrating simulated anomalies generated by ComGEN into automated production workflows.
A Survey on RGB, 3D, and Multimodal Approaches for Unsupervised Industrial Anomaly Detection
Oct 29, 2024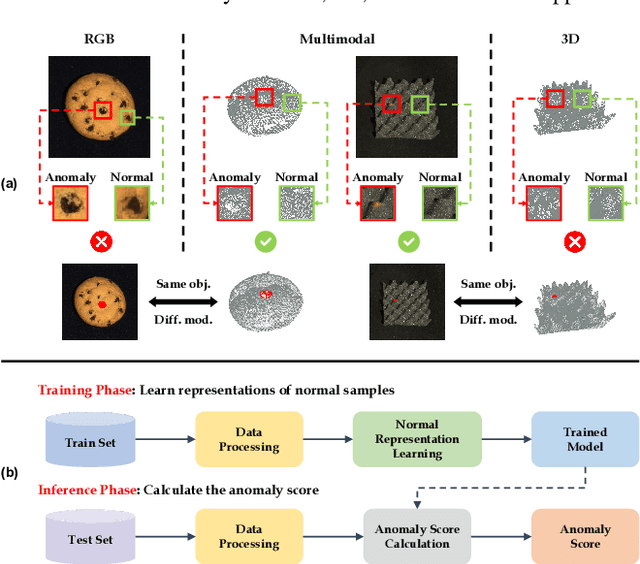
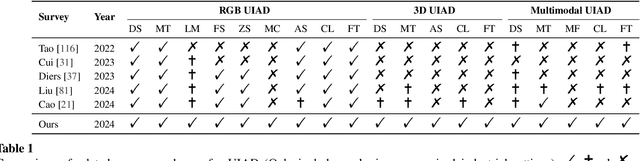
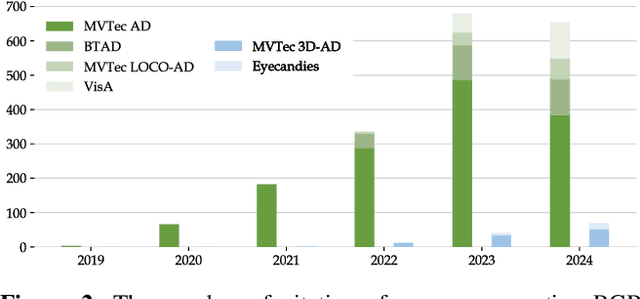
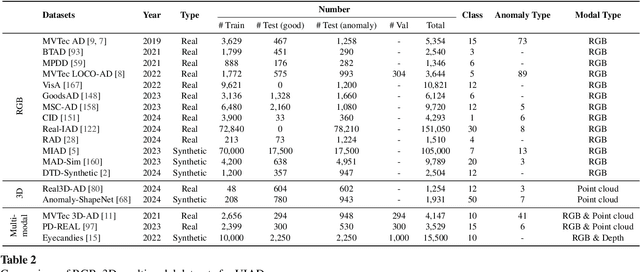
In the advancement of industrial informatization, Unsupervised Industrial Anomaly Detection (UIAD) technology effectively overcomes the scarcity of abnormal samples and significantly enhances the automation and reliability of smart manufacturing. While RGB, 3D, and multimodal anomaly detection have demonstrated comprehensive and robust capabilities within the industrial informatization sector, existing reviews on industrial anomaly detection have not sufficiently classified and discussed methods in 3D and multimodal settings. We focus on 3D UIAD and multimodal UIAD, providing a comprehensive summary of unsupervised industrial anomaly detection in three modal settings. Firstly, we compare our surveys with recent works, introducing commonly used datasets, evaluation metrics, and the definitions of anomaly detection problems. Secondly, we summarize five research paradigms in RGB, 3D and multimodal UIAD and three emerging industrial manufacturing optimization directions in RGB UIAD, and review three multimodal feature fusion strategies in multimodal settings. Finally, we outline the primary challenges currently faced by UIAD in three modal settings, and offer insights into future development directions, aiming to provide researchers with a thorough reference and offer new perspectives for the advancement of industrial informatization. Corresponding resources are available at https://github.com/Sunny5250/Awesome-Multi-Setting-UIAD.
Hi-EF: Benchmarking Emotion Forecasting in Human-interaction
Jul 23, 2024



Affective Forecasting, a research direction in psychology that predicts individuals future emotions, is often constrained by numerous external factors like social influence and temporal distance. To address this, we transform Affective Forecasting into a Deep Learning problem by designing an Emotion Forecasting paradigm based on two-party interactions. We propose a novel Emotion Forecasting (EF) task grounded in the theory that an individuals emotions are easily influenced by the emotions or other information conveyed during interactions with another person. To tackle this task, we have developed a specialized dataset, Human-interaction-based Emotion Forecasting (Hi-EF), which contains 3069 two-party Multilayered-Contextual Interaction Samples (MCIS) with abundant affective-relevant labels and three modalities. Hi-EF not only demonstrates the feasibility of the EF task but also highlights its potential. Additionally, we propose a methodology that establishes a foundational and referential baseline model for the EF task and extensive experiments are provided. The dataset and code is available at https://github.com/Anonymize-Author/Hi-EF.
All rivers run into the sea: Unified Modality Brain-like Emotional Central Mechanism
Jul 22, 2024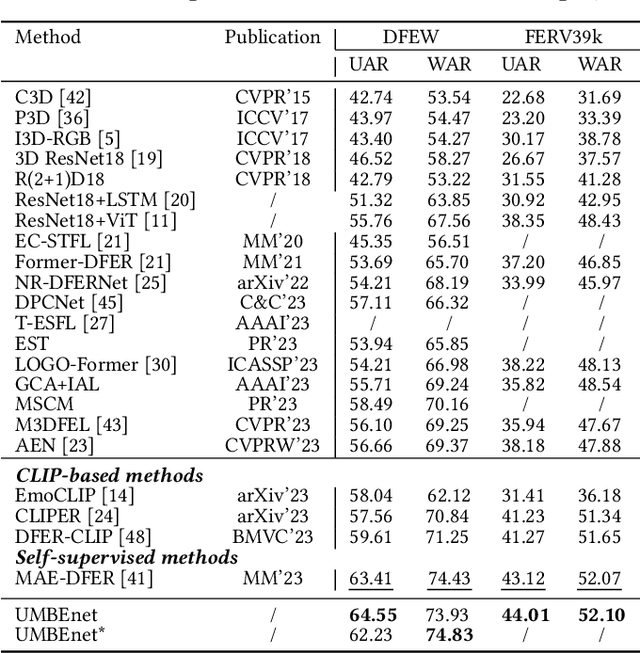


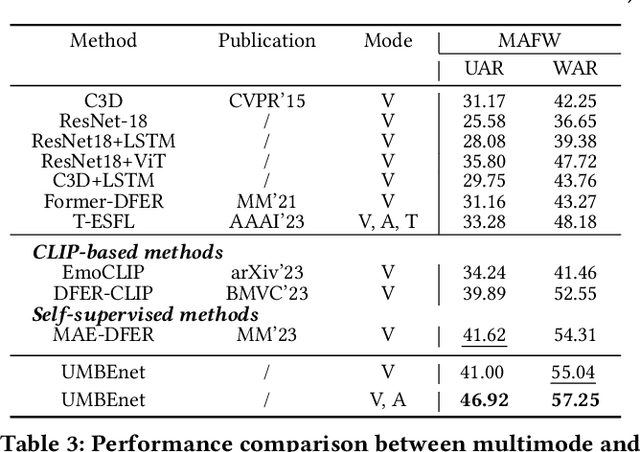
In the field of affective computing, fully leveraging information from a variety of sensory modalities is essential for the comprehensive understanding and processing of human emotions. Inspired by the process through which the human brain handles emotions and the theory of cross-modal plasticity, we propose UMBEnet, a brain-like unified modal affective processing network. The primary design of UMBEnet includes a Dual-Stream (DS) structure that fuses inherent prompts with a Prompt Pool and a Sparse Feature Fusion (SFF) module. The design of the Prompt Pool is aimed at integrating information from different modalities, while inherent prompts are intended to enhance the system's predictive guidance capabilities and effectively manage knowledge related to emotion classification. Moreover, considering the sparsity of effective information across different modalities, the SSF module aims to make full use of all available sensory data through the sparse integration of modality fusion prompts and inherent prompts, maintaining high adaptability and sensitivity to complex emotional states. Extensive experiments on the largest benchmark datasets in the Dynamic Facial Expression Recognition (DFER) field, including DFEW, FERV39k, and MAFW, have proven that UMBEnet consistently outperforms the current state-of-the-art methods. Notably, in scenarios of Modality Missingness and multimodal contexts, UMBEnet significantly surpasses the leading current methods, demonstrating outstanding performance and adaptability in tasks that involve complex emotional understanding with rich multimodal information.
Suppressing Uncertainties in Degradation Estimation for Blind Super-Resolution
Jun 24, 2024



The problem of blind image super-resolution aims to recover high-resolution (HR) images from low-resolution (LR) images with unknown degradation modes. Most existing methods model the image degradation process using blur kernels. However, this explicit modeling approach struggles to cover the complex and varied degradation processes encountered in the real world, such as high-order combinations of JPEG compression, blur, and noise. Implicit modeling for the degradation process can effectively overcome this issue, but a key challenge of implicit modeling is the lack of accurate ground truth labels for the degradation process to conduct supervised training. To overcome this limitations inherent in implicit modeling, we propose an \textbf{U}ncertainty-based degradation representation for blind \textbf{S}uper-\textbf{R}esolution framework (\textbf{USR}). By suppressing the uncertainty of local degradation representations in images, USR facilitated self-supervised learning of degradation representations. The USR consists of two components: Adaptive Uncertainty-Aware Degradation Extraction (AUDE) and a feature extraction network composed of Variable Depth Dynamic Convolution (VDDC) blocks. To extract Uncertainty-based Degradation Representation from LR images, the AUDE utilizes the Self-supervised Uncertainty Contrast module with Uncertainty Suppression Loss to suppress the inherent model uncertainty of the Degradation Extractor. Furthermore, VDDC block integrates degradation information through dynamic convolution. Rhe VDDC also employs an Adaptive Intensity Scaling operation that adaptively adjusts the degradation representation according to the network hierarchy, thereby facilitating the effective integration of degradation information. Quantitative and qualitative experiments affirm the superiority of our approach.