 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat matters for Representation Alignment: Global Information or Spatial Structure?
Dec 11, 2025Representation alignment (REPA) guides generative training by distilling representations from a strong, pretrained vision encoder to intermediate diffusion features. We investigate a fundamental question: what aspect of the target representation matters for generation, its \textit{global} \revision{semantic} information (e.g., measured by ImageNet-1K accuracy) or its spatial structure (i.e. pairwise cosine similarity between patch tokens)? Prevalent wisdom holds that stronger global semantic performance leads to better generation as a target representation. To study this, we first perform a large-scale empirical analysis across 27 different vision encoders and different model scales. The results are surprising; spatial structure, rather than global performance, drives the generation performance of a target representation. To further study this, we introduce two straightforward modifications, which specifically accentuate the transfer of \emph{spatial} information. We replace the standard MLP projection layer in REPA with a simple convolution layer and introduce a spatial normalization layer for the external representation. Surprisingly, our simple method (implemented in $<$4 lines of code), termed iREPA, consistently improves convergence speed of REPA, across a diverse set of vision encoders, model sizes, and training variants (such as REPA, REPA-E, Meanflow, JiT etc). %, etc. Our work motivates revisiting the fundamental working mechanism of representational alignment and how it can be leveraged for improved training of generative models. The code and project page are available at https://end2end-diffusion.github.io/irepa
TurboFill: Adapting Few-step Text-to-image Model for Fast Image Inpainting
Apr 01, 2025This paper introduces TurboFill, a fast image inpainting model that enhances a few-step text-to-image diffusion model with an inpainting adapter for high-quality and efficient inpainting. While standard diffusion models generate high-quality results, they incur high computational costs. We overcome this by training an inpainting adapter on a few-step distilled text-to-image model, DMD2, using a novel 3-step adversarial training scheme to ensure realistic, structurally consistent, and visually harmonious inpainted regions. To evaluate TurboFill, we propose two benchmarks: DilationBench, which tests performance across mask sizes, and HumanBench, based on human feedback for complex prompts. Experiments show that TurboFill outperforms both multi-step BrushNet and few-step inpainting methods, setting a new benchmark for high-performance inpainting tasks. Our project page: https://liangbinxie.github.io/projects/TurboFill/
Near-infrared Image Deblurring and Event Denoising with Synergistic Neuromorphic Imaging
Mar 05, 2025



The fields of imaging in the nighttime dynamic and other extremely dark conditions have seen impressive and transformative advancements in recent years, partly driven by the rise of novel sensing approaches, e.g., near-infrared (NIR) cameras with high sensitivity and event cameras with minimal blur. However, inappropriate exposure ratios of near-infrared cameras make them susceptible to distortion and blur. Event cameras are also highly sensitive to weak signals at night yet prone to interference, often generating substantial noise and significantly degrading observations and analysis. Herein, we develop a new framework for low-light imaging combined with NIR imaging and event-based techniques, named synergistic neuromorphic imaging, which can jointly achieve NIR image deblurring and event denoising. Harnessing cross-modal features of NIR images and visible events via spectral consistency and higher-order interaction, the NIR images and events are simultaneously fused, enhanced, and bootstrapped. Experiments on real and realistically simulated sequences demonstrate the effectiveness of our method and indicate better accuracy and robustness than other methods in practical scenarios. This study gives impetus to enhance both NIR images and events, which paves the way for high-fidelity low-light imaging and neuromorphic reasoning.
Hypergraph Foundation Model
Mar 03, 2025



Hypergraph neural networks (HGNNs) effectively model complex high-order relationships in domains like protein interactions and social networks by connecting multiple vertices through hyperedges, enhancing modeling capabilities, and reducing information loss. Developing foundation models for hypergraphs is challenging due to their distinct data, which includes both vertex features and intricate structural information. We present Hyper-FM, a Hypergraph Foundation Model for multi-domain knowledge extraction, featuring Hierarchical High-Order Neighbor Guided Vertex Knowledge Embedding for vertex feature representation and Hierarchical Multi-Hypergraph Guided Structural Knowledge Extraction for structural information. Additionally, we curate 10 text-attributed hypergraph datasets to advance research between HGNNs and LLMs. Experiments on these datasets show that Hyper-FM outperforms baseline methods by approximately 13.3\%, validating our approach. Furthermore, we propose the first scaling law for hypergraph foundation models, demonstrating that increasing domain diversity significantly enhances performance, unlike merely augmenting vertex and hyperedge counts. This underscores the critical role of domain diversity in scaling hypergraph models.
Multimodal Task Representation Memory Bank vs. Catastrophic Forgetting in Anomaly Detection
Feb 10, 2025



Unsupervised Continuous Anomaly Detection (UCAD) faces significant challenges in multi-task representation learning, with existing methods suffering from incomplete representation and catastrophic forgetting. Unlike supervised models, unsupervised scenarios lack prior information, making it difficult to effectively distinguish redundant and complementary multimodal features. To address this, we propose the Multimodal Task Representation Memory Bank (MTRMB) method through two key technical innovations: A Key-Prompt-Multimodal Knowledge (KPMK) mechanism that uses concise key prompts to guide cross-modal feature interaction between BERT and ViT. Refined Structure-based Contrastive Learning (RSCL) leveraging Grounding DINO and SAM to generate precise segmentation masks, pulling features of the same structural region closer while pushing different structural regions apart. Experiments on MVtec AD and VisA datasets demonstrate MTRMB's superiority, achieving an average detection accuracy of 0.921 at the lowest forgetting rate, significantly outperforming state-of-the-art methods. We plan to open source on GitHub.
SliderSpace: Decomposing the Visual Capabilities of Diffusion Models
Feb 03, 2025We present SliderSpace, a framework for automatically decomposing the visual capabilities of diffusion models into controllable and human-understandable directions. Unlike existing control methods that require a user to specify attributes for each edit direction individually, SliderSpace discovers multiple interpretable and diverse directions simultaneously from a single text prompt. Each direction is trained as a low-rank adaptor, enabling compositional control and the discovery of surprising possibilities in the model's latent space. Through extensive experiments on state-of-the-art diffusion models, we demonstrate SliderSpace's effectiveness across three applications: concept decomposition, artistic style exploration, and diversity enhancement. Our quantitative evaluation shows that SliderSpace-discovered directions decompose the visual structure of model's knowledge effectively, offering insights into the latent capabilities encoded within diffusion models. User studies further validate that our method produces more diverse and useful variations compared to baselines. Our code, data and trained weights are available at https://sliderspace.baulab.info
CLIP-FSAC++: Few-Shot Anomaly Classification with Anomaly Descriptor Based on CLIP
Dec 05, 2024



Industrial anomaly classification (AC) is an indispensable task in industrial manufacturing, which guarantees quality and safety of various product. To address the scarcity of data in industrial scenarios, lots of few-shot anomaly detection methods emerge recently. In this paper, we propose an effective few-shot anomaly classification (FSAC) framework with one-stage training, dubbed CLIP-FSAC++. Specifically, we introduce a cross-modality interaction module named Anomaly Descriptor following image and text encoders, which enhances the correlation of visual and text embeddings and adapts the representations of CLIP from pre-trained data to target data. In anomaly descriptor, image-to-text cross-attention module is used to obtain image-specific text embeddings and text-to-image cross-attention module is used to obtain text-specific visual embeddings. Then these modality-specific embeddings are used to enhance original representations of CLIP for better matching ability. Comprehensive experiment results are provided for evaluating our method in few-normal shot anomaly classification on VisA and MVTEC-AD for 1, 2, 4 and 8-shot settings. The source codes are at https://github.com/Jay-zzcoder/clip-fsac-pp
HyperDefect-YOLO: Enhance YOLO with HyperGraph Computation for Industrial Defect Detection
Dec 05, 2024In the manufacturing industry, defect detection is an essential but challenging task aiming to detect defects generated in the process of production. Though traditional YOLO models presents a good performance in defect detection, they still have limitations in capturing high-order feature interrelationships, which hurdles defect detection in the complex scenarios and across the scales. To this end, we introduce hypergraph computation into YOLO framework, dubbed HyperDefect-YOLO (HD-YOLO), to improve representative ability and semantic exploitation. HD-YOLO consists of Defect Aware Module (DAM) and Mixed Graph Network (MGNet) in the backbone, which specialize for perception and extraction of defect features. To effectively aggregate multi-scale features, we propose HyperGraph Aggregation Network (HGANet) which combines hypergraph and attention mechanism to aggregate multi-scale features. Cross-Scale Fusion (CSF) is proposed to adaptively fuse and handle features instead of simple concatenation and convolution. Finally, we propose Semantic Aware Module (SAM) in the neck to enhance semantic exploitation for accurately localizing defects with different sizes in the disturbed background. HD-YOLO undergoes rigorous evaluation on public HRIPCB and NEU-DET datasets with significant improvements compared to state-of-the-art methods. We also evaluate HD-YOLO on self-built MINILED dataset collected in real industrial scenarios to demonstrate the effectiveness of the proposed method. The source codes are at https://github.com/Jay-zzcoder/HD-YOLO.
TSUBF-Net: Trans-Spatial UNet-like Network with Bi-direction Fusion for Segmentation of Adenoid Hypertrophy in CT
Dec 01, 2024Adenoid hypertrophy stands as a common cause of obstructive sleep apnea-hypopnea syndrome in children. It is characterized by snoring, nasal congestion, and growth disorders. Computed Tomography (CT) emerges as a pivotal medical imaging modality, utilizing X-rays and advanced computational techniques to generate detailed cross-sectional images. Within the realm of pediatric airway assessments, CT imaging provides an insightful perspective on the shape and volume of enlarged adenoids. Despite the advances of deep learning methods for medical imaging analysis, there remains an emptiness in the segmentation of adenoid hypertrophy in CT scans. To address this research gap, we introduce TSUBF-Nett (Trans-Spatial UNet-like Network based on Bi-direction Fusion), a 3D medical image segmentation framework. TSUBF-Net is engineered to effectively discern intricate 3D spatial interlayer features in CT scans and enhance the extraction of boundary-blurring features. Notably, we propose two innovative modules within the U-shaped network architecture:the Trans-Spatial Perception module (TSP) and the Bi-directional Sampling Collaborated Fusion module (BSCF).These two modules are in charge of operating during the sampling process and strategically fusing down-sampled and up-sampled features, respectively. Furthermore, we introduce the Sobel loss term, which optimizes the smoothness of the segmentation results and enhances model accuracy. Extensive 3D segmentation experiments are conducted on several datasets. TSUBF-Net is superior to the state-of-the-art methods with the lowest HD95: 7.03, IoU:85.63, and DSC: 92.26 on our own AHSD dataset. The results in the other two public datasets also demonstrate that our methods can robustly and effectively address the challenges of 3D segmentation in CT scans.
A Survey on RGB, 3D, and Multimodal Approaches for Unsupervised Industrial Anomaly Detection
Oct 29, 2024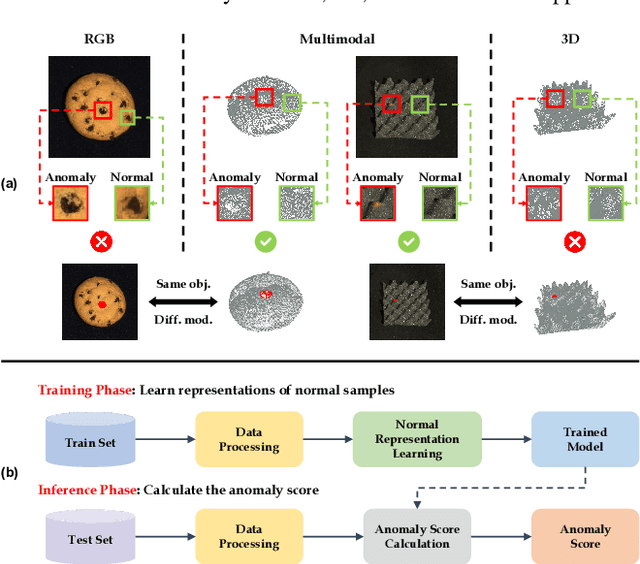
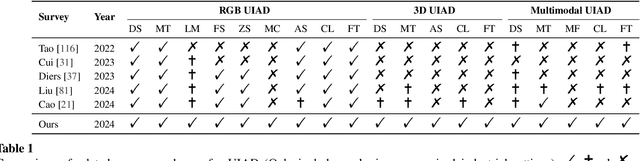
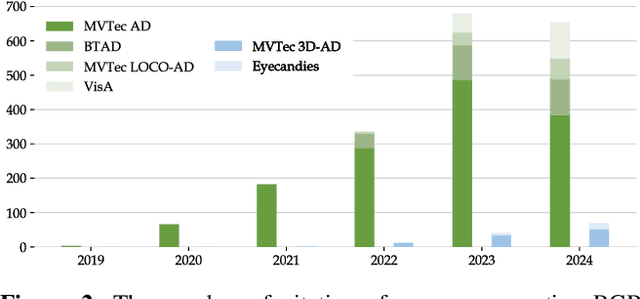
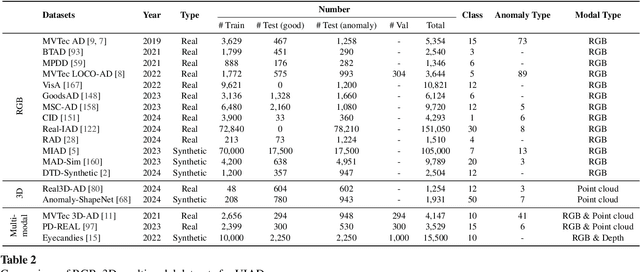
In the advancement of industrial informatization, Unsupervised Industrial Anomaly Detection (UIAD) technology effectively overcomes the scarcity of abnormal samples and significantly enhances the automation and reliability of smart manufacturing. While RGB, 3D, and multimodal anomaly detection have demonstrated comprehensive and robust capabilities within the industrial informatization sector, existing reviews on industrial anomaly detection have not sufficiently classified and discussed methods in 3D and multimodal settings. We focus on 3D UIAD and multimodal UIAD, providing a comprehensive summary of unsupervised industrial anomaly detection in three modal settings. Firstly, we compare our surveys with recent works, introducing commonly used datasets, evaluation metrics, and the definitions of anomaly detection problems. Secondly, we summarize five research paradigms in RGB, 3D and multimodal UIAD and three emerging industrial manufacturing optimization directions in RGB UIAD, and review three multimodal feature fusion strategies in multimodal settings. Finally, we outline the primary challenges currently faced by UIAD in three modal settings, and offer insights into future development directions, aiming to provide researchers with a thorough reference and offer new perspectives for the advancement of industrial informatization. Corresponding resources are available at https://github.com/Sunny5250/Awesome-Multi-Setting-UIAD.