 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Perception to Reasoning: Deep Thinking Empowers Multimodal Large Language Models
Nov 18, 2025With the remarkable success of Multimodal Large Language Models (MLLMs) in perception tasks, enhancing their complex reasoning capabilities has emerged as a critical research focus. Existing models still suffer from challenges such as opaque reasoning paths and insufficient generalization ability. Chain-of-Thought (CoT) reasoning, which has demonstrated significant efficacy in language models by enhancing reasoning transparency and output interpretability, holds promise for improving model reasoning capabilities when extended to the multimodal domain. This paper provides a systematic review centered on "Multimodal Chain-of-Thought" (MCoT). First, it analyzes the background and theoretical motivations for its inception from the perspectives of technical evolution and task demands. Then, it introduces mainstream MCoT methods from three aspects: CoT paradigms, the post-training stage, and the inference stage, while also analyzing their underlying mechanisms. Furthermore, the paper summarizes existing evaluation benchmarks and metrics, and discusses the application scenarios of MCoT. Finally, it analyzes the challenges currently facing MCoT and provides an outlook on its future research directions.
EndoWave: Rational-Wavelet 4D Gaussian Splatting for Endoscopic Reconstruction
Oct 27, 2025In robot-assisted minimally invasive surgery, accurate 3D reconstruction from endoscopic video is vital for downstream tasks and improved outcomes. However, endoscopic scenarios present unique challenges, including photometric inconsistencies, non-rigid tissue motion, and view-dependent highlights. Most 3DGS-based methods that rely solely on appearance constraints for optimizing 3DGS are often insufficient in this context, as these dynamic visual artifacts can mislead the optimization process and lead to inaccurate reconstructions. To address these limitations, we present EndoWave, a unified spatio-temporal Gaussian Splatting framework by incorporating an optical flow-based geometric constraint and a multi-resolution rational wavelet supervision. First, we adopt a unified spatio-temporal Gaussian representation that directly optimizes primitives in a 4D domain. Second, we propose a geometric constraint derived from optical flow to enhance temporal coherence and effectively constrain the 3D structure of the scene. Third, we propose a multi-resolution rational orthogonal wavelet as a constraint, which can effectively separate the details of the endoscope and enhance the rendering performance. Extensive evaluations on two real surgical datasets, EndoNeRF and StereoMIS, demonstrate that our method EndoWave achieves state-of-the-art reconstruction quality and visual accuracy compared to the baseline method.
SimpleGVR: A Simple Baseline for Latent-Cascaded Video Super-Resolution
Jun 24, 2025Latent diffusion models have emerged as a leading paradigm for efficient video generation. However, as user expectations shift toward higher-resolution outputs, relying solely on latent computation becomes inadequate. A promising approach involves decoupling the process into two stages: semantic content generation and detail synthesis. The former employs a computationally intensive base model at lower resolutions, while the latter leverages a lightweight cascaded video super-resolution (VSR) model to achieve high-resolution output. In this work, we focus on studying key design principles for latter cascaded VSR models, which are underexplored currently. First, we propose two degradation strategies to generate training pairs that better mimic the output characteristics of the base model, ensuring alignment between the VSR model and its upstream generator. Second, we provide critical insights into VSR model behavior through systematic analysis of (1) timestep sampling strategies, (2) noise augmentation effects on low-resolution (LR) inputs. These findings directly inform our architectural and training innovations. Finally, we introduce interleaving temporal unit and sparse local attention to achieve efficient training and inference, drastically reducing computational overhead. Extensive experiments demonstrate the superiority of our framework over existing methods, with ablation studies confirming the efficacy of each design choice. Our work establishes a simple yet effective baseline for cascaded video super-resolution generation, offering practical insights to guide future advancements in efficient cascaded synthesis systems.
TurboFill: Adapting Few-step Text-to-image Model for Fast Image Inpainting
Apr 01, 2025This paper introduces TurboFill, a fast image inpainting model that enhances a few-step text-to-image diffusion model with an inpainting adapter for high-quality and efficient inpainting. While standard diffusion models generate high-quality results, they incur high computational costs. We overcome this by training an inpainting adapter on a few-step distilled text-to-image model, DMD2, using a novel 3-step adversarial training scheme to ensure realistic, structurally consistent, and visually harmonious inpainted regions. To evaluate TurboFill, we propose two benchmarks: DilationBench, which tests performance across mask sizes, and HumanBench, based on human feedback for complex prompts. Experiments show that TurboFill outperforms both multi-step BrushNet and few-step inpainting methods, setting a new benchmark for high-performance inpainting tasks. Our project page: https://liangbinxie.github.io/projects/TurboFill/
Hyperspectral image reconstruction by deep learning with super-Rayleigh speckles
Feb 26, 2025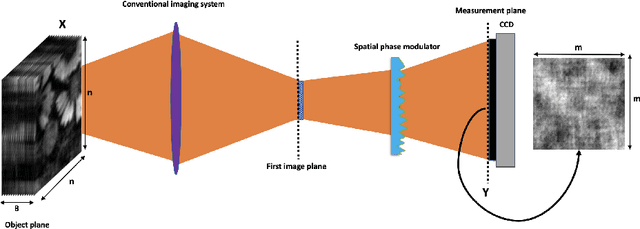
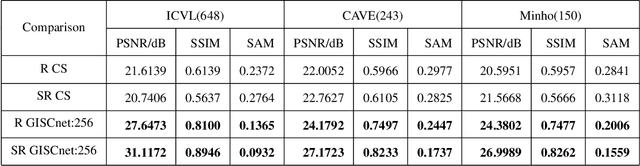
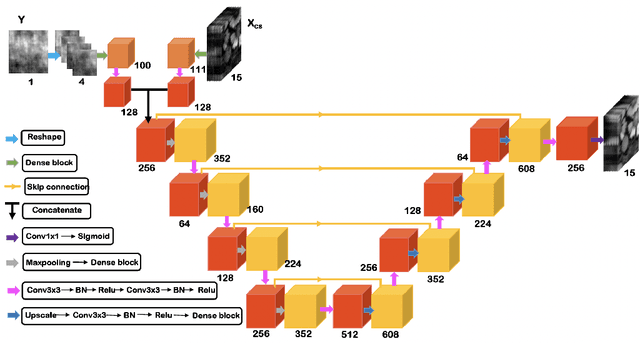
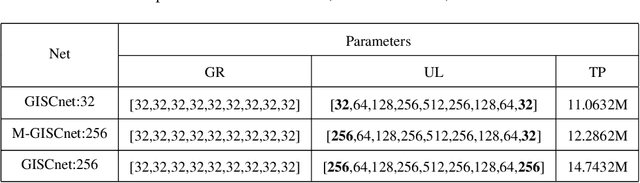
Ghost imaging via sparsity constraints (GISC) spectral camera modulates the three-dimensional (3D) hyperspectral image into a two-dimensional (2D) compressive image with speckles in a single shot. It obtains a 3D hyperspectral image (HSI) by reconstruction algorithms. The rapid development of deep learning has provided a new method for 3D HSI reconstruction. Moreover, the imaging performance of the GISC spectral camera can be improved by optimizing the speckle modulation. In this paper, we propose an end-to-end GISCnet with super-Rayleigh speckle modulation to improve the imaging quality of the GISC spectral camera. The structure of GISCnet is very simple but effective, and we can easily adjust the network structure parameters to improve the image reconstruction quality. Relative to Rayleigh speckles, our super-Rayleigh speckles modulation exhibits a wealth of detail in reconstructing 3D HSIs. After evaluating 648 3D HSIs, it was found that the average peak signal-to-noise ratio increased from 27 dB to 31 dB. Overall, the proposed GISCnet with super-Rayleigh speckle modulation can effectively improve the imaging quality of the GISC spectral camera by taking advantage of both optimized super-Rayleigh modulation and deep-learning image reconstruction, inspiring joint optimization of light-field modulation and image reconstruction to improve ghost imaging performance.
DiffVSR: Enhancing Real-World Video Super-Resolution with Diffusion Models for Advanced Visual Quality and Temporal Consistency
Jan 17, 2025



Diffusion models have demonstrated exceptional capabilities in image generation and restoration, yet their application to video super-resolution faces significant challenges in maintaining both high fidelity and temporal consistency. We present DiffVSR, a diffusion-based framework for real-world video super-resolution that effectively addresses these challenges through key innovations. For intra-sequence coherence, we develop a multi-scale temporal attention module and temporal-enhanced VAE decoder that capture fine-grained motion details. To ensure inter-sequence stability, we introduce a noise rescheduling mechanism with an interweaved latent transition approach, which enhances temporal consistency without additional training overhead. We propose a progressive learning strategy that transitions from simple to complex degradations, enabling robust optimization despite limited high-quality video data. Extensive experiments demonstrate that DiffVSR delivers superior results in both visual quality and temporal consistency, setting a new performance standard in real-world video super-resolution.
Towards Real-world Video Face Restoration: A New Benchmark
Apr 30, 2024



Blind face restoration (BFR) on images has significantly progressed over the last several years, while real-world video face restoration (VFR), which is more challenging for more complex face motions such as moving gaze directions and facial orientations involved, remains unsolved. Typical BFR methods are evaluated on privately synthesized datasets or self-collected real-world low-quality face images, which are limited in their coverage of real-world video frames. In this work, we introduced new real-world datasets named FOS with a taxonomy of "Full, Occluded, and Side" faces from mainly video frames to study the applicability of current methods on videos. Compared with existing test datasets, FOS datasets cover more diverse degradations and involve face samples from more complex scenarios, which helps to revisit current face restoration approaches more comprehensively. Given the established datasets, we benchmarked both the state-of-the-art BFR methods and the video super resolution (VSR) methods to comprehensively study current approaches, identifying their potential and limitations in VFR tasks. In addition, we studied the effectiveness of the commonly used image quality assessment (IQA) metrics and face IQA (FIQA) metrics by leveraging a subjective user study. With extensive experimental results and detailed analysis provided, we gained insights from the successes and failures of both current BFR and VSR methods. These results also pose challenges to current face restoration approaches, which we hope stimulate future advances in VFR research.
Proximal Gradient Descent Unfolding Dense-spatial Spectral-attention Transformer for Compressive Spectral Imaging
Dec 25, 2023The Coded Aperture Snapshot Spectral Compressive Imaging (CASSI) system modulates three-dimensional hyperspectral images into two-dimensional compressed images in a single exposure. Subsequently, three-dimensional hyperspectral images (HSI) can be reconstructed from the two-dimensional compressed measurements using reconstruction algorithms. Among these methods, deep unfolding techniques have demonstrated excellent performance, with RDLUF-MixS^2 achieving the best reconstruction results. However, RDLUF-MixS^2 requires extensive training time, taking approximately 14 days to train RDLUF-MixS^2-9stg on a single RTX 3090 GPU, making it computationally expensive. Furthermore, RDLUF-MixS^2 performs poorly on real data, resulting in significant artifacts in the reconstructed images. In this study, we introduce the Dense-spatial Spectral-attention Transformer (DST) into the Proximal Gradient Descent Unfolding Framework (PGDUF), creating a novel approach called Proximal Gradient Descent Unfolding Dense-spatial Spectral-attention Transformer (PGDUDST). Compared to RDLUF-MixS^2, PGDUDST not only surpasses the network reconstruction performance limit of RDLUF-MixS^2 but also achieves faster convergence. PGDUDST requires only 58% of the training time of RDLUF-MixS^2-9stg to achieve comparable reconstruction results. Additionally, PGDUDST significantly alleviates the artifact issues caused by RDLUF-MixS^2 in real experimental data, demonstrating superior performance and producing clearer reconstructed images.
DiffBIR: Towards Blind Image Restoration with Generative Diffusion Prior
Aug 29, 2023

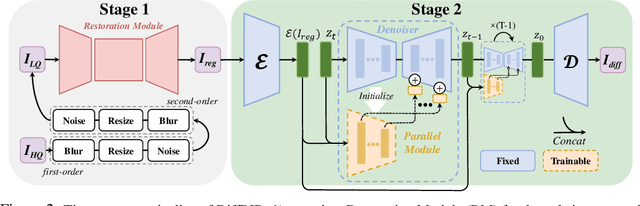
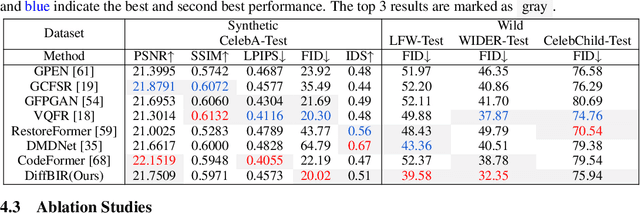
We present DiffBIR, which leverages pretrained text-to-image diffusion models for blind image restoration problem. Our framework adopts a two-stage pipeline. In the first stage, we pretrain a restoration module across diversified degradations to improve generalization capability in real-world scenarios. The second stage leverages the generative ability of latent diffusion models, to achieve realistic image restoration. Specifically, we introduce an injective modulation sub-network -- LAControlNet for finetuning, while the pre-trained Stable Diffusion is to maintain its generative ability. Finally, we introduce a controllable module that allows users to balance quality and fidelity by introducing the latent image guidance in the denoising process during inference. Extensive experiments have demonstrated its superiority over state-of-the-art approaches for both blind image super-resolution and blind face restoration tasks on synthetic and real-world datasets. The code is available at https://github.com/XPixelGroup/DiffBIR.
Phase retrieval based on shaped incoherent sources
Nov 17, 2022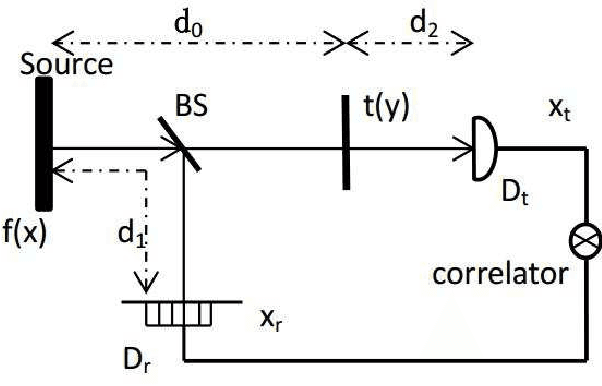
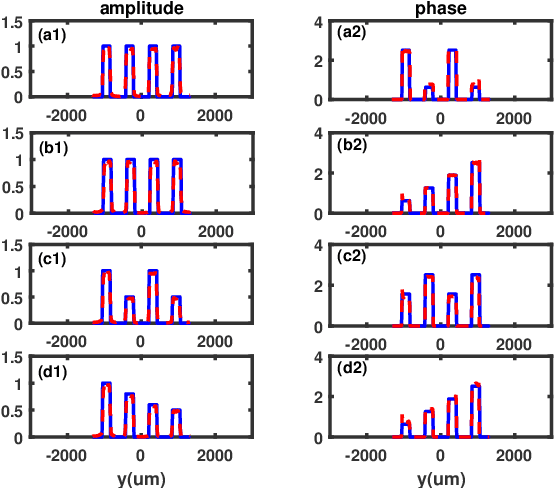
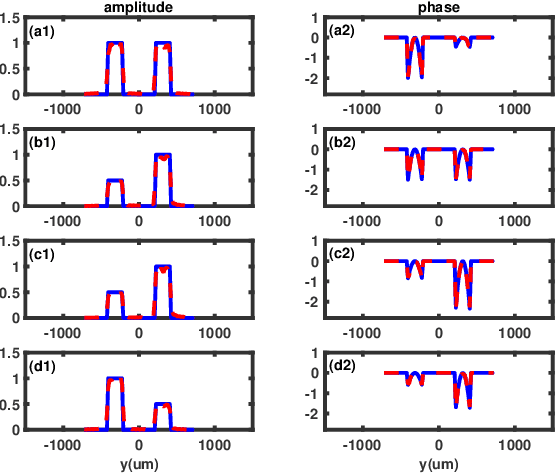
By designing five different incoherent sources in ghost imaging(GI), we have proposed a kind of five-step phase-shifting method to reconstruct the phase distribution of the complicated object without the need of complicated GI system, iterative algorithm and Fourier transform step. The applicability of this theoretical proposal is demonstrated via numerical simulations with two kinds of complicated objects.