 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Generalizable Deblurring: Leveraging Massive Blur Priors with Linear Attention for Real-World Scenarios
Jan 10, 2026Image deblurring has advanced rapidly with deep learning, yet most methods exhibit poor generalization beyond their training datasets, with performance dropping significantly in real-world scenarios. Our analysis shows this limitation stems from two factors: datasets face an inherent trade-off between realism and coverage of diverse blur patterns, and algorithmic designs remain restrictive, as pixel-wise losses drive models toward local detail recovery while overlooking structural and semantic consistency, whereas diffusion-based approaches, though perceptually strong, still fail to generalize when trained on narrow datasets with simplistic strategies. Through systematic investigation, we identify blur pattern diversity as the decisive factor for robust generalization and propose Blur Pattern Pretraining (BPP), which acquires blur priors from simulation datasets and transfers them through joint fine-tuning on real data. We further introduce Motion and Semantic Guidance (MoSeG) to strengthen blur priors under severe degradation, and integrate it into GLOWDeblur, a Generalizable reaL-wOrld lightWeight Deblur model that combines convolution-based pre-reconstruction & domain alignment module with a lightweight diffusion backbone. Extensive experiments on six widely-used benchmarks and two real-world datasets validate our approach, confirming the importance of blur priors for robust generalization and demonstrating that the lightweight design of GLOWDeblur ensures practicality in real-world applications. The project page is available at https://vegdog007.github.io/GLOWDeblur_Website/.
UniPercept: Towards Unified Perceptual-Level Image Understanding across Aesthetics, Quality, Structure, and Texture
Dec 25, 2025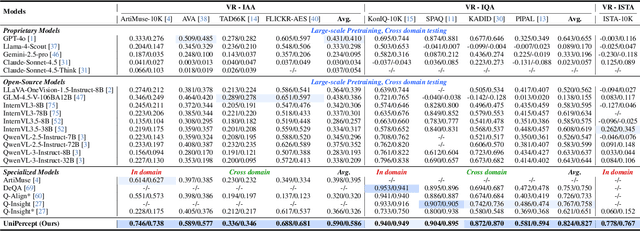

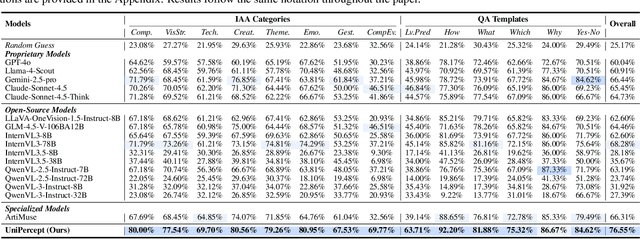
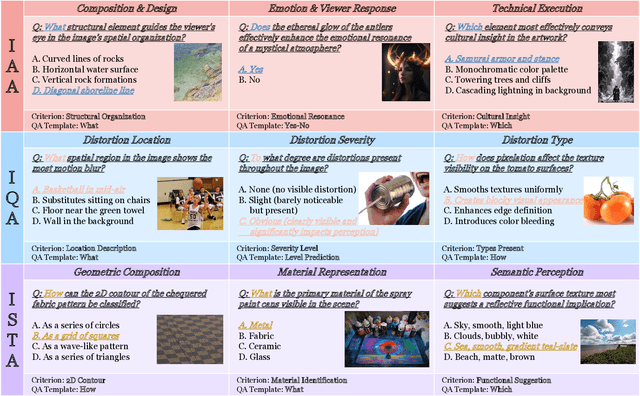
Multimodal large language models (MLLMs) have achieved remarkable progress in visual understanding tasks such as visual grounding, segmentation, and captioning. However, their ability to perceive perceptual-level image features remains limited. In this work, we present UniPercept-Bench, a unified framework for perceptual-level image understanding across three key domains: Aesthetics, Quality, Structure and Texture. We establish a hierarchical definition system and construct large-scale datasets to evaluate perceptual-level image understanding. Based on this foundation, we develop a strong baseline UniPercept trained via Domain-Adaptive Pre-Training and Task-Aligned RL, enabling robust generalization across both Visual Rating (VR) and Visual Question Answering (VQA) tasks. UniPercept outperforms existing MLLMs on perceptual-level image understanding and can serve as a plug-and-play reward model for text-to-image generation. This work defines Perceptual-Level Image Understanding in the era of MLLMs and, through the introduction of a comprehensive benchmark together with a strong baseline, provides a solid foundation for advancing perceptual-level multimodal image understanding.
dMLLM-TTS: Self-Verified and Efficient Test-Time Scaling for Diffusion Multi-Modal Large Language Models
Dec 22, 2025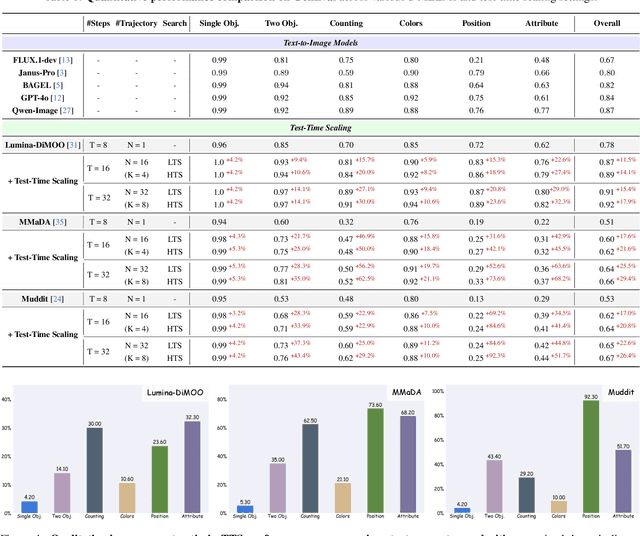

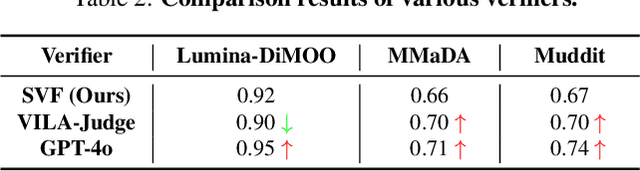
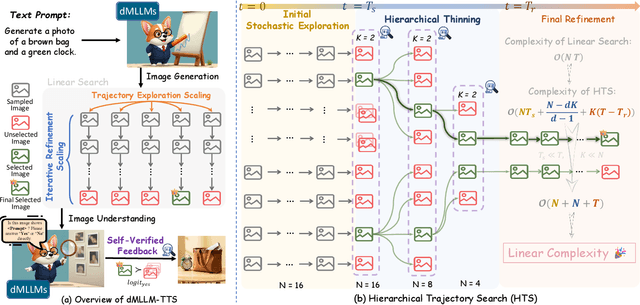
Diffusion Multi-modal Large Language Models (dMLLMs) have recently emerged as a novel architecture unifying image generation and understanding. However, developing effective and efficient Test-Time Scaling (TTS) methods to unlock their full generative potential remains an underexplored challenge. To address this, we propose dMLLM-TTS, a novel framework operating on two complementary scaling axes: (1) trajectory exploration scaling to enhance the diversity of generated hypotheses, and (2) iterative refinement scaling for stable generation. Conventional TTS approaches typically perform linear search across these two dimensions, incurring substantial computational costs of O(NT) and requiring an external verifier for best-of-N selection. To overcome these limitations, we propose two innovations. First, we design an efficient hierarchical search algorithm with O(N+T) complexity that adaptively expands and prunes sampling trajectories. Second, we introduce a self-verified feedback mechanism that leverages the dMLLMs' intrinsic image understanding capabilities to assess text-image alignment, eliminating the need for external verifier. Extensive experiments on the GenEval benchmark across three representative dMLLMs (e.g., Lumina-DiMOO, MMaDA, Muddit) show that our framework substantially improves generation quality while achieving up to 6x greater efficiency than linear search. Project page: https://github.com/Alpha-VLLM/Lumina-DiMOO.
DualX-VSR: Dual Axial Spatial$\times$Temporal Transformer for Real-World Video Super-Resolution without Motion Compensation
Jun 05, 2025Transformer-based models like ViViT and TimeSformer have advanced video understanding by effectively modeling spatiotemporal dependencies. Recent video generation models, such as Sora and Vidu, further highlight the power of transformers in long-range feature extraction and holistic spatiotemporal modeling. However, directly applying these models to real-world video super-resolution (VSR) is challenging, as VSR demands pixel-level precision, which can be compromised by tokenization and sequential attention mechanisms. While recent transformer-based VSR models attempt to address these issues using smaller patches and local attention, they still face limitations such as restricted receptive fields and dependence on optical flow-based alignment, which can introduce inaccuracies in real-world settings. To overcome these issues, we propose Dual Axial Spatial$\times$Temporal Transformer for Real-World Video Super-Resolution (DualX-VSR), which introduces a novel dual axial spatial$\times$temporal attention mechanism that integrates spatial and temporal information along orthogonal directions. DualX-VSR eliminates the need for motion compensation, offering a simplified structure that provides a cohesive representation of spatiotemporal information. As a result, DualX-VSR achieves high fidelity and superior performance in real-world VSR task.
Learning and Interpreting Gravitational-Wave Features from CNNs with a Random Forest Approach
May 26, 2025Convolutional neural networks (CNNs) have become widely adopted in gravitational wave (GW) detection pipelines due to their ability to automatically learn hierarchical features from raw strain data. However, the physical meaning of these learned features remains underexplored, limiting the interpretability of such models. In this work, we propose a hybrid architecture that combines a CNN-based feature extractor with a random forest (RF) classifier to improve both detection performance and interpretability. Unlike prior approaches that directly connect classifiers to CNN outputs, our method introduces four physically interpretable metrics - variance, signal-to-noise ratio (SNR), waveform overlap, and peak amplitude - computed from the final convolutional layer. These are jointly used with the CNN output in the RF classifier to enable more informed decision boundaries. Tested on long-duration strain datasets, our hybrid model outperforms a baseline CNN model, achieving a relative improvement of 21\% in sensitivity at a fixed false alarm rate of 10 events per month. Notably, it also shows improved detection of low-SNR signals (SNR $\le$ 10), which are especially vulnerable to misclassification in noisy environments. Feature attribution via the RF model reveals that both CNN-extracted and handcrafted features contribute significantly to classification decisions, with learned variance and CNN outputs ranked among the most informative. These findings suggest that physically motivated post-processing of CNN feature maps can serve as a valuable tool for interpretable and efficient GW detection, bridging the gap between deep learning and domain knowledge.
DiffVSR: Enhancing Real-World Video Super-Resolution with Diffusion Models for Advanced Visual Quality and Temporal Consistency
Jan 17, 2025



Diffusion models have demonstrated exceptional capabilities in image generation and restoration, yet their application to video super-resolution faces significant challenges in maintaining both high fidelity and temporal consistency. We present DiffVSR, a diffusion-based framework for real-world video super-resolution that effectively addresses these challenges through key innovations. For intra-sequence coherence, we develop a multi-scale temporal attention module and temporal-enhanced VAE decoder that capture fine-grained motion details. To ensure inter-sequence stability, we introduce a noise rescheduling mechanism with an interweaved latent transition approach, which enhances temporal consistency without additional training overhead. We propose a progressive learning strategy that transitions from simple to complex degradations, enabling robust optimization despite limited high-quality video data. Extensive experiments demonstrate that DiffVSR delivers superior results in both visual quality and temporal consistency, setting a new performance standard in real-world video super-resolution.
GRIDS: Grouped Multiple-Degradation Restoration with Image Degradation Similarity
Jul 17, 2024



Traditional single-task image restoration methods excel in handling specific degradation types but struggle with multiple degradations. To address this limitation, we propose Grouped Restoration with Image Degradation Similarity (GRIDS), a novel approach that harmonizes the competing objectives inherent in multiple-degradation restoration. We first introduce a quantitative method for assessing relationships between image degradations using statistical modeling of deep degradation representations. This analysis facilitates the strategic grouping of similar tasks, enhancing both the efficiency and effectiveness of the restoration process. Based on the degradation similarity, GRIDS divides restoration tasks into one of the optimal groups, where tasks within the same group are highly correlated. For instance, GRIDS effectively groups 11 degradation types into 4 cohesive groups. Trained models within each group show significant improvements, with an average improvement of 0.09dB over single-task upper bound models and 2.24dB over the mix-training baseline model. GRIDS incorporates an adaptive model selection mechanism for inference, automatically selecting the appropriate grouped-training model based on the input degradation. This mechanism is particularly useful for real-world scenarios with unknown degradations as it does not rely on explicit degradation classification modules. Furthermore, our method can predict model generalization ability without the need for network inference, providing valuable insights for practitioners.