 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciEvalKit: An Open-source Evaluation Toolkit for Scientific General Intelligence
Dec 30, 2025We introduce SciEvalKit, a unified benchmarking toolkit designed to evaluate AI models for science across a broad range of scientific disciplines and task capabilities. Unlike general-purpose evaluation platforms, SciEvalKit focuses on the core competencies of scientific intelligence, including Scientific Multimodal Perception, Scientific Multimodal Reasoning, Scientific Multimodal Understanding, Scientific Symbolic Reasoning, Scientific Code Generation, Science Hypothesis Generation and Scientific Knowledge Understanding. It supports six major scientific domains, spanning from physics and chemistry to astronomy and materials science. SciEvalKit builds a foundation of expert-grade scientific benchmarks, curated from real-world, domain-specific datasets, ensuring that tasks reflect authentic scientific challenges. The toolkit features a flexible, extensible evaluation pipeline that enables batch evaluation across models and datasets, supports custom model and dataset integration, and provides transparent, reproducible, and comparable results. By bridging capability-based evaluation and disciplinary diversity, SciEvalKit offers a standardized yet customizable infrastructure to benchmark the next generation of scientific foundation models and intelligent agents. The toolkit is open-sourced and actively maintained to foster community-driven development and progress in AI4Science.
FinPercep-RM: A Fine-grained Reward Model and Co-evolutionary Curriculum for RL-based Real-world Super-Resolution
Dec 27, 2025Reinforcement Learning with Human Feedback (RLHF) has proven effective in image generation field guided by reward models to align human preferences. Motivated by this, adapting RLHF for Image Super-Resolution (ISR) tasks has shown promise in optimizing perceptual quality with Image Quality Assessment (IQA) model as reward models. However, the traditional IQA model usually output a single global score, which are exceptionally insensitive to local and fine-grained distortions. This insensitivity allows ISR models to produce perceptually undesirable artifacts that yield spurious high scores, misaligning optimization objectives with perceptual quality and results in reward hacking. To address this, we propose a Fine-grained Perceptual Reward Model (FinPercep-RM) based on an Encoder-Decoder architecture. While providing a global quality score, it also generates a Perceptual Degradation Map that spatially localizes and quantifies local defects. We specifically introduce the FGR-30k dataset to train this model, consisting of diverse and subtle distortions from real-world super-resolution models. Despite the success of the FinPercep-RM model, its complexity introduces significant challenges in generator policy learning, leading to training instability. To address this, we propose a Co-evolutionary Curriculum Learning (CCL) mechanism, where both the reward model and the ISR model undergo synchronized curricula. The reward model progressively increases in complexity, while the ISR model starts with a simpler global reward for rapid convergence, gradually transitioning to the more complex model outputs. This easy-to-hard strategy enables stable training while suppressing reward hacking. Experiments validates the effectiveness of our method across ISR models in both global quality and local realism on RLHF methods.
UniPercept: Towards Unified Perceptual-Level Image Understanding across Aesthetics, Quality, Structure, and Texture
Dec 25, 2025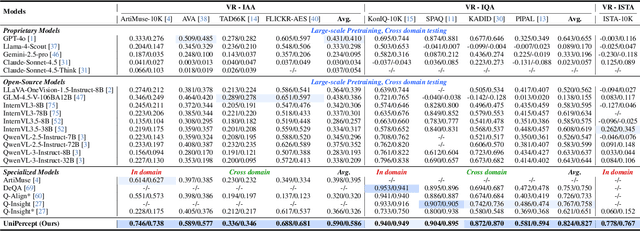

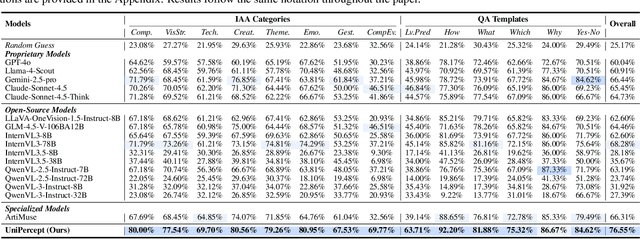
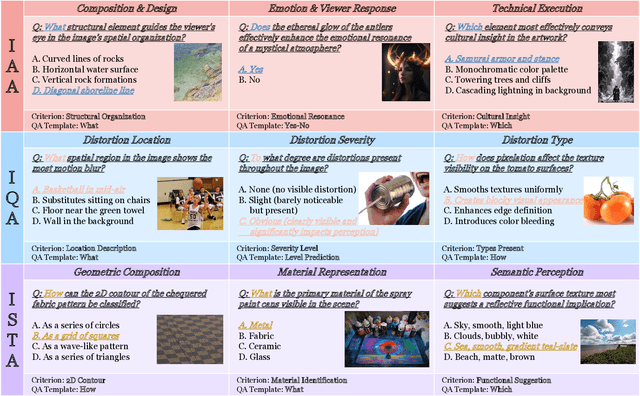
Multimodal large language models (MLLMs) have achieved remarkable progress in visual understanding tasks such as visual grounding, segmentation, and captioning. However, their ability to perceive perceptual-level image features remains limited. In this work, we present UniPercept-Bench, a unified framework for perceptual-level image understanding across three key domains: Aesthetics, Quality, Structure and Texture. We establish a hierarchical definition system and construct large-scale datasets to evaluate perceptual-level image understanding. Based on this foundation, we develop a strong baseline UniPercept trained via Domain-Adaptive Pre-Training and Task-Aligned RL, enabling robust generalization across both Visual Rating (VR) and Visual Question Answering (VQA) tasks. UniPercept outperforms existing MLLMs on perceptual-level image understanding and can serve as a plug-and-play reward model for text-to-image generation. This work defines Perceptual-Level Image Understanding in the era of MLLMs and, through the introduction of a comprehensive benchmark together with a strong baseline, provides a solid foundation for advancing perceptual-level multimodal image understanding.
Omni-Weather: Unified Multimodal Foundation Model for Weather Generation and Understanding
Dec 25, 2025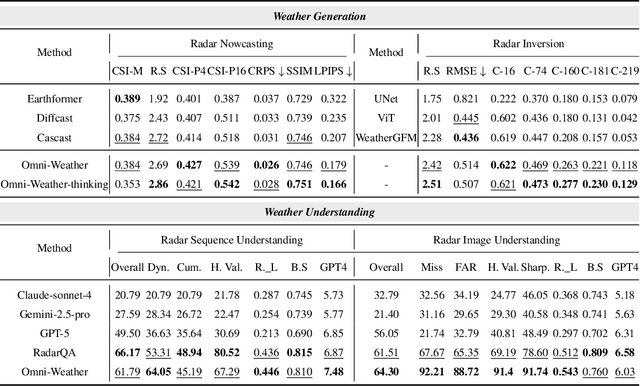
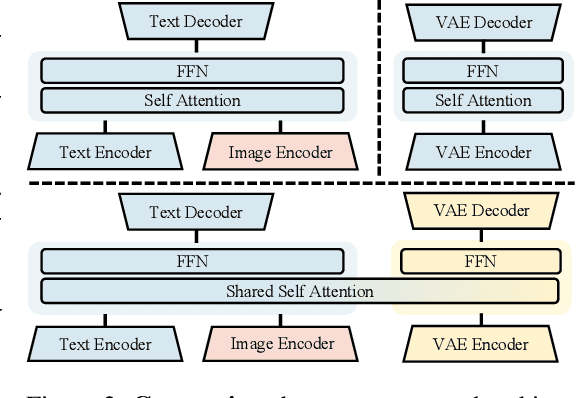
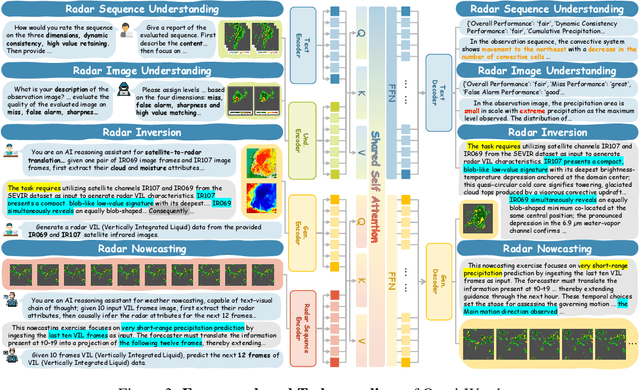

Weather modeling requires both accurate prediction and mechanistic interpretation, yet existing methods treat these goals in isolation, separating generation from understanding. To address this gap, we present Omni-Weather, the first multimodal foundation model that unifies weather generation and understanding within a single architecture. Omni-Weather integrates a radar encoder for weather generation tasks, followed by unified processing using a shared self-attention mechanism. Moreover, we construct a Chain-of-Thought dataset for causal reasoning in weather generation, enabling interpretable outputs and improved perceptual quality. Extensive experiments show Omni-Weather achieves state-of-the-art performance in both weather generation and understanding. Our findings further indicate that generative and understanding tasks in the weather domain can mutually enhance each other. Omni-Weather also demonstrates the feasibility and value of unifying weather generation and understanding.
Probing Scientific General Intelligence of LLMs with Scientist-Aligned Workflows
Dec 18, 2025Despite advances in scientific AI, a coherent framework for Scientific General Intelligence (SGI)-the ability to autonomously conceive, investigate, and reason across scientific domains-remains lacking. We present an operational SGI definition grounded in the Practical Inquiry Model (PIM: Deliberation, Conception, Action, Perception) and operationalize it via four scientist-aligned tasks: deep research, idea generation, dry/wet experiments, and experimental reasoning. SGI-Bench comprises over 1,000 expert-curated, cross-disciplinary samples inspired by Science's 125 Big Questions, enabling systematic evaluation of state-of-the-art LLMs. Results reveal gaps: low exact match (10--20%) in deep research despite step-level alignment; ideas lacking feasibility and detail; high code executability but low execution result accuracy in dry experiments; low sequence fidelity in wet protocols; and persistent multimodal comparative-reasoning challenges. We further introduce Test-Time Reinforcement Learning (TTRL), which optimizes retrieval-augmented novelty rewards at inference, enhancing hypothesis novelty without reference answer. Together, our PIM-grounded definition, workflow-centric benchmark, and empirical insights establish a foundation for AI systems that genuinely participate in scientific discovery.
ATLAS: A High-Difficulty, Multidisciplinary Benchmark for Frontier Scientific Reasoning
Nov 18, 2025The rapid advancement of Large Language Models (LLMs) has led to performance saturation on many established benchmarks, questioning their ability to distinguish frontier models. Concurrently, existing high-difficulty benchmarks often suffer from narrow disciplinary focus, oversimplified answer formats, and vulnerability to data contamination, creating a fidelity gap with real-world scientific inquiry. To address these challenges, we introduce ATLAS (AGI-Oriented Testbed for Logical Application in Science), a large-scale, high-difficulty, and cross-disciplinary evaluation suite composed of approximately 800 original problems. Developed by domain experts (PhD-level and above), ATLAS spans seven core scientific fields: mathematics, physics, chemistry, biology, computer science, earth science, and materials science. Its key features include: (1) High Originality and Contamination Resistance, with all questions newly created or substantially adapted to prevent test data leakage; (2) Cross-Disciplinary Focus, designed to assess models' ability to integrate knowledge and reason across scientific domains; (3) High-Fidelity Answers, prioritizing complex, open-ended answers involving multi-step reasoning and LaTeX-formatted expressions over simple multiple-choice questions; and (4) Rigorous Quality Control, employing a multi-stage process of expert peer review and adversarial testing to ensure question difficulty, scientific value, and correctness. We also propose a robust evaluation paradigm using a panel of LLM judges for automated, nuanced assessment of complex answers. Preliminary results on leading models demonstrate ATLAS's effectiveness in differentiating their advanced scientific reasoning capabilities. We plan to develop ATLAS into a long-term, open, community-driven platform to provide a reliable "ruler" for progress toward Artificial General Intelligence.
SynWeather: Weather Observation Data Synthesis across Multiple Regions and Variables via a General Diffusion Transformer
Nov 15, 2025With the advancement of meteorological instruments, abundant data has become available. Current approaches are typically focus on single-variable, single-region tasks and primarily rely on deterministic modeling. This limits unified synthesis across variables and regions, overlooks cross-variable complementarity and often leads to over-smoothed results. To address above challenges, we introduce SynWeather, the first dataset designed for Unified Multi-region and Multi-variable Weather Observation Data Synthesis. SynWeather covers four representative regions: the Continental United States, Europe, East Asia, and Tropical Cyclone regions, as well as provides high-resolution observations of key weather variables, including Composite Radar Reflectivity, Hourly Precipitation, Visible Light, and Microwave Brightness Temperature. In addition, we introduce SynWeatherDiff, a general and probabilistic weather synthesis model built upon the Diffusion Transformer framework to address the over-smoothed problem. Experiments on the SynWeather dataset demonstrate the effectiveness of our network compared with both task-specific and general models.
Latent Harmony: Synergistic Unified UHD Image Restoration via Latent Space Regularization and Controllable Refinement
Oct 09, 2025



Ultra-High Definition (UHD) image restoration faces a trade-off between computational efficiency and high-frequency detail retention. While Variational Autoencoders (VAEs) improve efficiency via latent-space processing, their Gaussian constraint often discards degradation-specific high-frequency information, hurting reconstruction fidelity. To overcome this, we propose Latent Harmony, a two-stage framework that redefines VAEs for UHD restoration by jointly regularizing the latent space and enforcing high-frequency-aware reconstruction.In Stage One, we introduce LH-VAE, which enhances semantic robustness through visual semantic constraints and progressive degradation perturbations, while latent equivariance strengthens high-frequency reconstruction.Stage Two jointly trains this refined VAE with a restoration model using High-Frequency Low-Rank Adaptation (HF-LoRA): an encoder LoRA guided by a fidelity-oriented high-frequency alignment loss to recover authentic details, and a decoder LoRA driven by a perception-oriented loss to synthesize realistic textures. Both LoRA modules are trained via alternating optimization with selective gradient propagation to preserve the pretrained latent structure.At inference, a tunable parameter {\alpha} enables flexible fidelity-perception trade-offs.Experiments show Latent Harmony achieves state-of-the-art performance across UHD and standard-resolution tasks, effectively balancing efficiency, perceptual quality, and reconstruction accuracy.
Understand Before You Generate: Self-Guided Training for Autoregressive Image Generation
Sep 18, 2025



Recent studies have demonstrated the importance of high-quality visual representations in image generation and have highlighted the limitations of generative models in image understanding. As a generative paradigm originally designed for natural language, autoregressive models face similar challenges. In this work, we present the first systematic investigation into the mechanisms of applying the next-token prediction paradigm to the visual domain. We identify three key properties that hinder the learning of high-level visual semantics: local and conditional dependence, inter-step semantic inconsistency, and spatial invariance deficiency. We show that these issues can be effectively addressed by introducing self-supervised objectives during training, leading to a novel training framework, Self-guided Training for AutoRegressive models (ST-AR). Without relying on pre-trained representation models, ST-AR significantly enhances the image understanding ability of autoregressive models and leads to improved generation quality. Specifically, ST-AR brings approximately 42% FID improvement for LlamaGen-L and 49% FID improvement for LlamaGen-XL, while maintaining the same sampling strategy.
A Survey of Scientific Large Language Models: From Data Foundations to Agent Frontiers
Aug 28, 2025



Scientific Large Language Models (Sci-LLMs) are transforming how knowledge is represented, integrated, and applied in scientific research, yet their progress is shaped by the complex nature of scientific data. This survey presents a comprehensive, data-centric synthesis that reframes the development of Sci-LLMs as a co-evolution between models and their underlying data substrate. We formulate a unified taxonomy of scientific data and a hierarchical model of scientific knowledge, emphasizing the multimodal, cross-scale, and domain-specific challenges that differentiate scientific corpora from general natural language processing datasets. We systematically review recent Sci-LLMs, from general-purpose foundations to specialized models across diverse scientific disciplines, alongside an extensive analysis of over 270 pre-/post-training datasets, showing why Sci-LLMs pose distinct demands -- heterogeneous, multi-scale, uncertainty-laden corpora that require representations preserving domain invariance and enabling cross-modal reasoning. On evaluation, we examine over 190 benchmark datasets and trace a shift from static exams toward process- and discovery-oriented assessments with advanced evaluation protocols. These data-centric analyses highlight persistent issues in scientific data development and discuss emerging solutions involving semi-automated annotation pipelines and expert validation. Finally, we outline a paradigm shift toward closed-loop systems where autonomous agents based on Sci-LLMs actively experiment, validate, and contribute to a living, evolving knowledge base. Collectively, this work provides a roadmap for building trustworthy, continually evolving artificial intelligence (AI) systems that function as a true partner in accelerating scientific discovery.