 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGGT-100K: Generative Ground Truth for Generalizable Real-World Image Restoration
May 29, 2026Real-world image restoration (IR) is bottlenecked by the scarcity of high-quality paired training data. Synthetic datasets are abundant but often fail to model real-world degradations, while real-world paired datasets are expensive and difficult to capture. As a result, IR models trained on these datasets show limited generalization in real-world scenarios. In this work, we propose Generative Ground Truth (GGT) by using generative multimodal foundation models (MFMs) to produce high-quality (HQ) targets from real-world low-quality (LQ) images. We first conduct a systematic evaluation of nine state-of-the-art MFMs, including Nano-Banana-2 and GPT-Image-2, on images of various scenes and degradation types. The results demonstrate that Nano-Banana-2 with VLM-based adaptive prompting shows the highest capability to synthesize perceptually realistic and content-faithful HQ targets, which can serve as the GGT for the LQ input. We then employ Nano-Banana-2 to build a GGT synthesis pipeline, which involves multi-stage quality control to ensure data reliability, and construct GGT-100K, an LQ-HQ paired dataset comprising 103,707 training pairs and covering diverse scenes and complex real-world degradations. A test set of 500 image pairs is also established. Extensive experiments show that GGT-100K consistently improves the real-world generalization of a wide range of IR models, with particularly strong benefits for finetuning generative models for IR tasks. Our results suggest that MFMs can serve as practical tools for restoration-oriented data generation, and GGT-100K is a useful resource to expand the generalization boundaries of real-world IR models.
VOSR: A Vision-Only Generative Model for Image Super-Resolution
Apr 03, 2026Most of the recent generative image super-resolution (SR) methods rely on adapting large text-to-image (T2I) diffusion models pretrained on web-scale text-image data. While effective, this paradigm starts from a generic T2I generator, despite that SR is fundamentally a low-resolution (LR) input-conditioned image restoration task. In this work, we investigate whether an SR model trained purely on visual data can rival T2I-based ones. To this end, we propose VOSR, a Vision-Only generative framework for SR. We first extract semantically rich and spatially grounded features from the LR input using a pretrained vision encoder as visual semantic guidance. We then revisit classifier-free guidance for training generative models and show that the standard unconditional branch is ill-suited to restoration models trained from scratch. We therefore replace it with a restoration-oriented guidance strategy that preserves weak LR anchors. Built upon these designs, we first train a multi-step VOSR model from scratch and then distill it into a one-step model for efficient inference. VOSR requires less than one-tenth of the training cost of representative T2I-based SR methods, yet in both multi-step and one-step settings, it achieves competitive or even better perceptual quality and efficiency, while producing more faithful structures with fewer hallucinations on both synthetic and real-world benchmarks. Our results, for the first time, show that high-quality generative SR can be achieved without multimodal pretraining. The code and models can be found at https://github.com/cswry/VOSR.
NSARM: Next-Scale Autoregressive Modeling for Robust Real-World Image Super-Resolution
Oct 01, 2025



Most recent real-world image super-resolution (Real-ISR) methods employ pre-trained text-to-image (T2I) diffusion models to synthesize the high-quality image either from random Gaussian noise, which yields realistic results but is slow due to iterative denoising, or directly from the input low-quality image, which is efficient but at the price of lower output quality. These approaches train ControlNet or LoRA modules while keeping the pre-trained model fixed, which often introduces over-enhanced artifacts and hallucinations, suffering from the robustness to inputs of varying degradations. Recent visual autoregressive (AR) models, such as pre-trained Infinity, can provide strong T2I generation capabilities while offering superior efficiency by using the bitwise next-scale prediction strategy. Building upon next-scale prediction, we introduce a robust Real-ISR framework, namely Next-Scale Autoregressive Modeling (NSARM). Specifically, we train NSARM in two stages: a transformation network is first trained to map the input low-quality image to preliminary scales, followed by an end-to-end full-model fine-tuning. Such a comprehensive fine-tuning enhances the robustness of NSARM in Real-ISR tasks without compromising its generative capability. Extensive quantitative and qualitative evaluations demonstrate that as a pure AR model, NSARM achieves superior visual results over existing Real-ISR methods while maintaining a fast inference speed. Most importantly, it demonstrates much higher robustness to the quality of input images, showing stronger generalization performance. Project page: https://github.com/Xiangtaokong/NSARM
InstructRestore: Region-Customized Image Restoration with Human Instructions
Mar 31, 2025



Despite the significant progress in diffusion prior-based image restoration, most existing methods apply uniform processing to the entire image, lacking the capability to perform region-customized image restoration according to user instructions. In this work, we propose a new framework, namely InstructRestore, to perform region-adjustable image restoration following human instructions. To achieve this, we first develop a data generation engine to produce training triplets, each consisting of a high-quality image, the target region description, and the corresponding region mask. With this engine and careful data screening, we construct a comprehensive dataset comprising 536,945 triplets to support the training and evaluation of this task. We then examine how to integrate the low-quality image features under the ControlNet architecture to adjust the degree of image details enhancement. Consequently, we develop a ControlNet-like model to identify the target region and allocate different integration scales to the target and surrounding regions, enabling region-customized image restoration that aligns with user instructions. Experimental results demonstrate that our proposed InstructRestore approach enables effective human-instructed image restoration, such as images with bokeh effects and user-instructed local enhancement. Our work advances the investigation of interactive image restoration and enhancement techniques. Data, code, and models will be found at https://github.com/shuaizhengliu/InstructRestore.git.
Toward Generalizing Visual Brain Decoding to Unseen Subjects
Oct 21, 2024Visual brain decoding aims to decode visual information from human brain activities. Despite the great progress, one critical limitation of current brain decoding research lies in the lack of generalization capability to unseen subjects. Prior works typically focus on decoding brain activity of individuals based on the observation that different subjects exhibit different brain activities, while it remains unclear whether brain decoding can be generalized to unseen subjects. This study aims to answer this question. We first consolidate an image-fMRI dataset consisting of stimulus-image and fMRI-response pairs, involving 177 subjects in the movie-viewing task of the Human Connectome Project (HCP). This dataset allows us to investigate the brain decoding performance with the increase of participants. We then present a learning paradigm that applies uniform processing across all subjects, instead of employing different network heads or tokenizers for individuals as in previous methods, which can accommodate a large number of subjects to explore the generalization capability across different subjects. A series of experiments are conducted and we have the following findings. First, the network exhibits clear generalization capabilities with the increase of training subjects. Second, the generalization capability is common to popular network architectures (MLP, CNN and Transformer). Third, the generalization performance is affected by the similarity between subjects. Our findings reveal the inherent similarities in brain activities across individuals. With the emerging of larger and more comprehensive datasets, it is possible to train a brain decoding foundation model in the future. Codes and models can be found at https://github.com/Xiangtaokong/TGBD.
Training on the Benchmark Is Not All You Need
Sep 03, 2024



The success of Large Language Models (LLMs) relies heavily on the huge amount of pre-training data learned in the pre-training phase. The opacity of the pre-training process and the training data causes the results of many benchmark tests to become unreliable. If any model has been trained on a benchmark test set, it can seriously hinder the health of the field. In order to automate and efficiently test the capabilities of large language models, numerous mainstream benchmarks adopt a multiple-choice format. As the swapping of the contents of multiple-choice options does not affect the meaning of the question itself, we propose a simple and effective data leakage detection method based on this property. Specifically, we shuffle the contents of the options in the data to generate the corresponding derived data sets, and then detect data leakage based on the model's log probability distribution over the derived data sets. If there is a maximum and outlier in the set of log probabilities, it indicates that the data is leaked. Our method is able to work under black-box conditions without access to model training data or weights, effectively identifying data leakage from benchmark test sets in model pre-training data, including both normal scenarios and complex scenarios where options may have been shuffled intentionally or unintentionally. Through experiments based on two LLMs and benchmark designs, we demonstrate the effectiveness of our method. In addition, we evaluate the degree of data leakage of 31 mainstream open-source LLMs on four benchmark datasets and give a ranking of the leaked LLMs for each benchmark, and we find that the Qwen family of LLMs has the highest degree of data leakage.
A Preliminary Exploration Towards General Image Restoration
Aug 27, 2024



Despite the tremendous success of deep models in various individual image restoration tasks, there are at least two major technical challenges preventing these works from being applied to real-world usages: (1) the lack of generalization ability and (2) the complex and unknown degradations in real-world scenarios. Existing deep models, tailored for specific individual image restoration tasks, often fall short in effectively addressing these challenges. In this paper, we present a new problem called general image restoration (GIR) which aims to address these challenges within a unified model. GIR covers most individual image restoration tasks (\eg, image denoising, deblurring, deraining and super-resolution) and their combinations for general purposes. This paper proceeds to delineate the essential aspects of GIR, including problem definition and the overarching significance of generalization performance. Moreover, the establishment of new datasets and a thorough evaluation framework for GIR models is discussed. We conduct a comprehensive evaluation of existing approaches for tackling the GIR challenge, illuminating their strengths and pragmatic challenges. By analyzing these approaches, we not only underscore the effectiveness of GIR but also highlight the difficulties in its practical implementation. At last, we also try to understand and interpret these models' behaviors to inspire the future direction. Our work can open up new valuable research directions and contribute to the research of general vision.
E-EVAL: A Comprehensive Chinese K-12 Education Evaluation Benchmark for Large Language Models
Jan 29, 2024



With the accelerating development of Large Language Models (LLMs), many LLMs are beginning to be used in the Chinese K-12 education domain. The integration of LLMs and education is getting closer and closer, however, there is currently no benchmark for evaluating LLMs that focuses on the Chinese K-12 education domain. Therefore, there is an urgent need for a comprehensive natural language processing benchmark to accurately assess the capabilities of various LLMs in the Chinese K-12 education domain. To address this, we introduce the E-EVAL, the first comprehensive evaluation benchmark specifically designed for the Chinese K-12 education field. The E-EVAL consists of 4,351 multiple-choice questions at the primary, middle, and high school levels across a wide range of subjects, including Chinese, English, Politics, History, Ethics, Physics, Chemistry, Mathematics, and Geography. We conducted a comprehensive evaluation of E-EVAL on advanced LLMs, including both English-dominant and Chinese-dominant models. Findings show that Chinese-dominant models perform well compared to English-dominant models, with many scoring even above the GPT 4.0. However, almost all models perform poorly in complex subjects such as mathematics. We also found that most Chinese-dominant LLMs did not achieve higher scores at the primary school level compared to the middle school level. We observe that the mastery of higher-order knowledge by the model does not necessarily imply the mastery of lower-order knowledge as well. Additionally, the experimental results indicate that the Chain of Thought (CoT) technique is effective only for the challenging science subjects, while Few-shot prompting is more beneficial for liberal arts subjects. With E-EVAL, we aim to analyze the strengths and limitations of LLMs in educational applications, and to contribute to the progress and development of Chinese K-12 education and LLMs.
Scaling Up to Excellence: Practicing Model Scaling for Photo-Realistic Image Restoration In the Wild
Jan 24, 2024
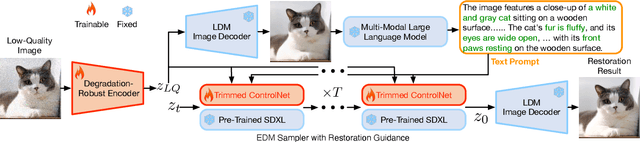
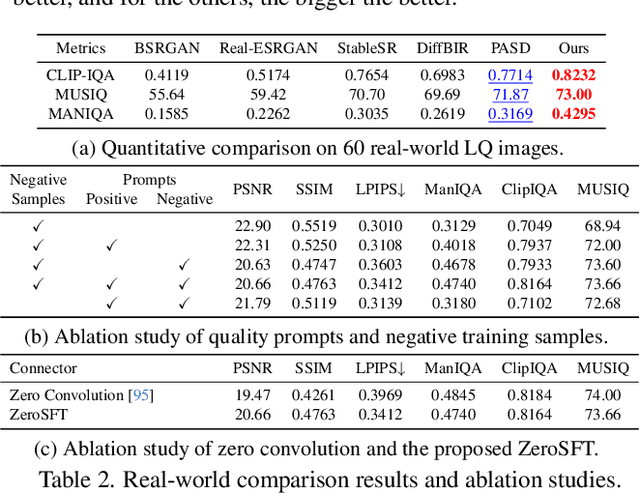

We introduce SUPIR (Scaling-UP Image Restoration), a groundbreaking image restoration method that harnesses generative prior and the power of model scaling up. Leveraging multi-modal techniques and advanced generative prior, SUPIR marks a significant advance in intelligent and realistic image restoration. As a pivotal catalyst within SUPIR, model scaling dramatically enhances its capabilities and demonstrates new potential for image restoration. We collect a dataset comprising 20 million high-resolution, high-quality images for model training, each enriched with descriptive text annotations. SUPIR provides the capability to restore images guided by textual prompts, broadening its application scope and potential. Moreover, we introduce negative-quality prompts to further improve perceptual quality. We also develop a restoration-guided sampling method to suppress the fidelity issue encountered in generative-based restoration. Experiments demonstrate SUPIR's exceptional restoration effects and its novel capacity to manipulate restoration through textual prompts.
Towards Effective Multiple-in-One Image Restoration: A Sequential and Prompt Learning Strategy
Jan 07, 2024While single task image restoration (IR) has achieved significant successes, it remains a challenging issue to train a single model which can tackle multiple IR tasks. In this work, we investigate in-depth the multiple-in-one (MiO) IR problem, which comprises seven popular IR tasks. We point out that MiO IR faces two pivotal challenges: the optimization of diverse objectives and the adaptation to multiple tasks. To tackle these challenges, we present two simple yet effective strategies. The first strategy, referred to as sequential learning, attempts to address how to optimize the diverse objectives, which guides the network to incrementally learn individual IR tasks in a sequential manner rather than mixing them together. The second strategy, i.e., prompt learning, attempts to address how to adapt to the different IR tasks, which assists the network to understand the specific task and improves the generalization ability. By evaluating on 19 test sets, we demonstrate that the sequential and prompt learning strategies can significantly enhance the MiO performance of commonly used CNN and Transformer backbones. Our experiments also reveal that the two strategies can supplement each other to learn better degradation representations and enhance the model robustness. It is expected that our proposed MiO IR formulation and strategies could facilitate the research on how to train IR models with higher generalization capabilities.