 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptor: Advancing Assistive Teleoperation with Few-Shot Learning and Cross-Operator Generalization
Apr 10, 2026Assistive teleoperation enhances efficiency via shared control, yet inter-operator variability, stemming from diverse habits and expertise, induces highly heterogeneous trajectory distributions that undermine intent recognition stability. We present Adaptor, a few-shot framework for robust cross-operator intent recognition. The Adaptor bridges the domain gap through two stages: (i) preprocessing, which models intent uncertainty by synthesizing trajectory perturbations via noise injection and performs geometry-aware keyframe extraction; and (ii) policy learning, which encodes the processed trajectories with an Intention Expert and fuses them with the pre-trained vision-language model context to condition an Action Expert for action generation. Experiments on real-world and simulated benchmarks demonstrate that Adaptor achieves state-of-the-art performance, improving success rates and efficiency over baselines. Moreover, the method exhibits low variance across operators with varying expertise, demonstrating robust cross-operator generalization.
CompassAD: Intent-Driven 3D Affordance Grounding in Functionally Competing Objects
Apr 02, 2026When told to "cut the apple," a robot must choose the knife over nearby scissors, despite both objects affording the same cutting function. In real-world scenes, multiple objects may share identical affordances, yet only one is appropriate under the given task context. We call such cases confusing pairs. However, existing 3D affordance methods largely sidestep this challenge by evaluating isolated single objects, often with explicit category names provided in the query. We formalize Multi-Object Affordance Grounding under Intent-Driven Instructions, a new 3D affordance setting that requires predicting a per-point affordance mask on the correct object within a cluttered multi-object point cloud, conditioned on implicit natural language intent. To study this problem, we construct CompassAD, the first benchmark centered on implicit intent in confusable multi-object scenes. It comprises 30 confusing object pairs spanning 16 affordance types, 6,422 scenes, and 88K+ query-answer pairs. Furthermore, we propose CompassNet, a framework that incorporates two dedicated modules tailored to this task. Instance-bounded Cross Injection (ICI) constrains language-geometry alignment within object boundaries to prevent cross-object semantic leakage. Bi-level Contrastive Refinement (BCR) enforces discrimination at both geometric-group and point levels, sharpening distinctions between target and confusable surfaces. Extensive experiments demonstrate state-of-the-art results on both seen and unseen queries, and deployment on a robotic manipulator confirms effective transfer to real-world grasping in confusing multi-object scenes.
Scan Clusters, Not Pixels: A Cluster-Centric Paradigm for Efficient Ultra-high-definition Image Restoration
Feb 25, 2026Ultra-High-Definition (UHD) image restoration is trapped in a scalability crisis: existing models, bound to pixel-wise operations, demand unsustainable computation. While state space models (SSMs) like Mamba promise linear complexity, their pixel-serial scanning remains a fundamental bottleneck for the millions of pixels in UHD content. We ask: must we process every pixel to understand the image? This paper introduces C$^2$SSM, a visual state space model that breaks this taboo by shifting from pixel-serial to cluster-serial scanning. Our core discovery is that the rich feature distribution of a UHD image can be distilled into a sparse set of semantic centroids via a neural-parameterized mixture model. C$^2$SSM leverages this to reformulate global modeling into a novel dual-path process: it scans and reasons over a handful of cluster centers, then diffuses the global context back to all pixels through a principled similarity distribution, all while a lightweight modulator preserves fine details. This cluster-centric paradigm achieves a decisive leap in efficiency, slashing computational costs while establishing new state-of-the-art results across five UHD restoration tasks. More than a solution, C$^2$SSM charts a new course for efficient large-scale vision: scan clusters, not pixels.
Trace-Focused Diffusion Policy for Multi-Modal Action Disambiguation in Long-Horizon Robotic Manipulation
Feb 07, 2026Generative model-based policies have shown strong performance in imitation-based robotic manipulation by learning action distributions from demonstrations. However, in long-horizon tasks, visually similar observations often recur across execution stages while requiring distinct actions, which leads to ambiguous predictions when policies are conditioned only on instantaneous observations, termed multi-modal action ambiguity (MA2). To address this challenge, we propose the Trace-Focused Diffusion Policy (TF-DP), a simple yet effective diffusion-based framework that explicitly conditions action generation on the robot's execution history. TF-DP represents historical motion as an explicit execution trace and projects it into the visual observation space, providing stage-aware context when current observations alone are insufficient. In addition, the induced trace-focused field emphasizes task-relevant regions associated with historical motion, improving robustness to background visual disturbances. We evaluate TF-DP on real-world robotic manipulation tasks exhibiting pronounced multi-modal action ambiguity and visually cluttered conditions. Experimental results show that TF-DP improves temporal consistency and robustness, outperforming the vanilla diffusion policy by 80.56 percent on tasks with multi-modal action ambiguity and by 86.11 percent under visual disturbances, while maintaining inference efficiency with only a 6.4 percent runtime increase. These results demonstrate that execution-trace conditioning offers a scalable and principled approach for robust long-horizon robotic manipulation within a single policy.
Action-to-Action Flow Matching
Feb 07, 2026Diffusion-based policies have recently achieved remarkable success in robotics by formulating action prediction as a conditional denoising process. However, the standard practice of sampling from random Gaussian noise often requires multiple iterative steps to produce clean actions, leading to high inference latency that incurs a major bottleneck for real-time control. In this paper, we challenge the necessity of uninformed noise sampling and propose Action-to-Action flow matching (A2A), a novel policy paradigm that shifts from random sampling to initialization informed by the previous action. Unlike existing methods that treat proprioceptive action feedback as static conditions, A2A leverages historical proprioceptive sequences, embedding them into a high-dimensional latent space as the starting point for action generation. This design bypasses costly iterative denoising while effectively capturing the robot's physical dynamics and temporal continuity. Extensive experiments demonstrate that A2A exhibits high training efficiency, fast inference speed, and improved generalization. Notably, A2A enables high-quality action generation in as few as a single inference step (0.56 ms latency), and exhibits superior robustness to visual perturbations and enhanced generalization to unseen configurations. Lastly, we also extend A2A to video generation, demonstrating its broader versatility in temporal modeling. Project site: https://lorenzo-0-0.github.io/A2A_Flow_Matching.
Generative Video Compression: Towards 0.01% Compression Rate for Video Transmission
Dec 30, 2025Whether a video can be compressed at an extreme compression rate as low as 0.01%? To this end, we achieve the compression rate as 0.02% at some cases by introducing Generative Video Compression (GVC), a new framework that redefines the limits of video compression by leveraging modern generative video models to achieve extreme compression rates while preserving a perception-centric, task-oriented communication paradigm, corresponding to Level C of the Shannon-Weaver model. Besides, How we trade computation for compression rate or bandwidth? GVC answers this question by shifting the burden from transmission to inference: it encodes video into extremely compact representations and delegates content reconstruction to the receiver, where powerful generative priors synthesize high-quality video from minimal transmitted information. Is GVC practical and deployable? To ensure practical deployment, we propose a compression-computation trade-off strategy, enabling fast inference on consume-grade GPUs. Within the AI Flow framework, GVC opens new possibility for video communication in bandwidth- and resource-constrained environments such as emergency rescue, remote surveillance, and mobile edge computing. Through empirical validation, we demonstrate that GVC offers a viable path toward a new effective, efficient, scalable, and practical video communication paradigm.
UniPercept: Towards Unified Perceptual-Level Image Understanding across Aesthetics, Quality, Structure, and Texture
Dec 25, 2025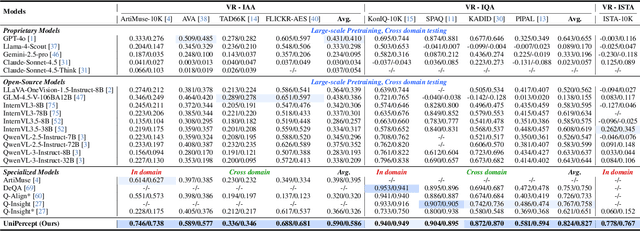

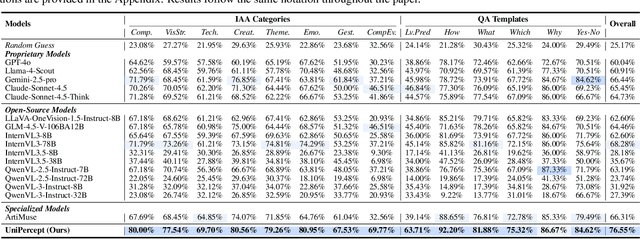
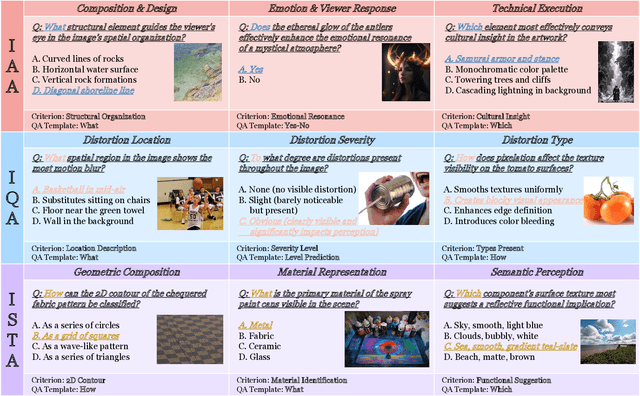
Multimodal large language models (MLLMs) have achieved remarkable progress in visual understanding tasks such as visual grounding, segmentation, and captioning. However, their ability to perceive perceptual-level image features remains limited. In this work, we present UniPercept-Bench, a unified framework for perceptual-level image understanding across three key domains: Aesthetics, Quality, Structure and Texture. We establish a hierarchical definition system and construct large-scale datasets to evaluate perceptual-level image understanding. Based on this foundation, we develop a strong baseline UniPercept trained via Domain-Adaptive Pre-Training and Task-Aligned RL, enabling robust generalization across both Visual Rating (VR) and Visual Question Answering (VQA) tasks. UniPercept outperforms existing MLLMs on perceptual-level image understanding and can serve as a plug-and-play reward model for text-to-image generation. This work defines Perceptual-Level Image Understanding in the era of MLLMs and, through the introduction of a comprehensive benchmark together with a strong baseline, provides a solid foundation for advancing perceptual-level multimodal image understanding.
Beyond Heuristics: A Decision-Theoretic Framework for Agent Memory Management
Dec 25, 2025External memory is a key component of modern large language model (LLM) systems, enabling long-term interaction and personalization. Despite its importance, memory management is still largely driven by hand-designed heuristics, offering little insight into the long-term and uncertain consequences of memory decisions. In practice, choices about what to read or write shape future retrieval and downstream behavior in ways that are difficult to anticipate. We argue that memory management should be viewed as a sequential decision-making problem under uncertainty, where the utility of memory is delayed and dependent on future interactions. To this end, we propose DAM (Decision-theoretic Agent Memory), a decision-theoretic framework that decomposes memory management into immediate information access and hierarchical storage maintenance. Within this architecture, candidate operations are evaluated via value functions and uncertainty estimators, enabling an aggregate policy to arbitrate decisions based on estimated long-term utility and risk. Our contribution is not a new algorithm, but a principled reframing that clarifies the limitations of heuristic approaches and provides a foundation for future research on uncertainty-aware memory systems.
FAPE-IR: Frequency-Aware Planning and Execution Framework for All-in-One Image Restoration
Nov 18, 2025All-in-One Image Restoration (AIO-IR) aims to develop a unified model that can handle multiple degradations under complex conditions. However, existing methods often rely on task-specific designs or latent routing strategies, making it hard to adapt to real-world scenarios with various degradations. We propose FAPE-IR, a Frequency-Aware Planning and Execution framework for image restoration. It uses a frozen Multimodal Large Language Model (MLLM) as a planner to analyze degraded images and generate concise, frequency-aware restoration plans. These plans guide a LoRA-based Mixture-of-Experts (LoRA-MoE) module within a diffusion-based executor, which dynamically selects high- or low-frequency experts, complemented by frequency features of the input image. To further improve restoration quality and reduce artifacts, we introduce adversarial training and a frequency regularization loss. By coupling semantic planning with frequency-based restoration, FAPE-IR offers a unified and interpretable solution for all-in-one image restoration. Extensive experiments show that FAPE-IR achieves state-of-the-art performance across seven restoration tasks and exhibits strong zero-shot generalization under mixed degradations.
Taming VR Teleoperation and Learning from Demonstration for Multi-Task Bimanual Table Service Manipulation
Aug 21, 2025


This technical report presents the champion solution of the Table Service Track in the ICRA 2025 What Bimanuals Can Do (WBCD) competition. We tackled a series of demanding tasks under strict requirements for speed, precision, and reliability: unfolding a tablecloth (deformable-object manipulation), placing a pizza into the container (pick-and-place), and opening and closing a food container with the lid. Our solution combines VR-based teleoperation and Learning from Demonstrations (LfD) to balance robustness and autonomy. Most subtasks were executed through high-fidelity remote teleoperation, while the pizza placement was handled by an ACT-based policy trained from 100 in-person teleoperated demonstrations with randomized initial configurations. By carefully integrating scoring rules, task characteristics, and current technical capabilities, our approach achieved both high efficiency and reliability, ultimately securing the first place in the competition.