 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning Meets Personalization: Unleashing the Potential of Large Reasoning Model for Personalized Generation
May 23, 2025Personalization is a critical task in modern intelligent systems, with applications spanning diverse domains, including interactions with large language models (LLMs). Recent advances in reasoning capabilities have significantly enhanced LLMs, enabling unprecedented performance in tasks such as mathematics and coding. However, their potential for personalization tasks remains underexplored. In this paper, we present the first systematic evaluation of large reasoning models (LRMs) for personalization tasks. Surprisingly, despite generating more tokens, LRMs do not consistently outperform general-purpose LLMs, especially in retrieval-intensive scenarios where their advantages diminish. Our analysis identifies three key limitations: divergent thinking, misalignment of response formats, and ineffective use of retrieved information. To address these challenges, we propose Reinforced Reasoning for Personalization (\model), a novel framework that incorporates a hierarchical reasoning thought template to guide LRMs in generating structured outputs. Additionally, we introduce a reasoning process intervention method to enforce adherence to designed reasoning patterns, enhancing alignment. We also propose a cross-referencing mechanism to ensure consistency. Extensive experiments demonstrate that our approach significantly outperforms existing techniques.
RALLRec+: Retrieval Augmented Large Language Model Recommendation with Reasoning
Mar 26, 2025



Large Language Models (LLMs) have been integrated into recommender systems to enhance user behavior comprehension. The Retrieval Augmented Generation (RAG) technique is further incorporated into these systems to retrieve more relevant items and improve system performance. However, existing RAG methods have two shortcomings. \textit{(i)} In the \textit{retrieval} stage, they rely primarily on textual semantics and often fail to incorporate the most relevant items, thus constraining system effectiveness. \textit{(ii)} In the \textit{generation} stage, they lack explicit chain-of-thought reasoning, further limiting their potential. In this paper, we propose Representation learning and \textbf{R}easoning empowered retrieval-\textbf{A}ugmented \textbf{L}arge \textbf{L}anguage model \textbf{Rec}ommendation (RALLRec+). Specifically, for the retrieval stage, we prompt LLMs to generate detailed item descriptions and perform joint representation learning, combining textual and collaborative signals extracted from the LLM and recommendation models, respectively. To account for the time-varying nature of user interests, we propose a simple yet effective reranking method to capture preference dynamics. For the generation phase, we first evaluate reasoning LLMs on recommendation tasks, uncovering valuable insights. Then we introduce knowledge-injected prompting and consistency-based merging approach to integrate reasoning LLMs with general-purpose LLMs, enhancing overall performance. Extensive experiments on three real world datasets validate our method's effectiveness.
RALLRec: Improving Retrieval Augmented Large Language Model Recommendation with Representation Learning
Feb 10, 2025Large Language Models (LLMs) have been integrated into recommendation systems to enhance user behavior comprehension. The Retrieval Augmented Generation (RAG) technique is further incorporated into these systems to retrieve more relevant items and improve system performance. However, existing RAG methods rely primarily on textual semantics and often fail to incorporate the most relevant items, limiting the effectiveness of the systems. In this paper, we propose Representation learning for retrieval-Augmented Large Language model Recommendation (RALLRec). Specifically, we enhance textual semantics by prompting LLMs to generate more detailed item descriptions, followed by joint representation learning of textual and collaborative semantics, which are extracted by the LLM and recommendation models, respectively. Considering the potential time-varying characteristics of user interest, a simple yet effective reranking method is further introduced to capture the dynamics of user preference. We conducted extensive experiments on three real-world datasets, and the evaluation results validated the effectiveness of our method. Code is made public at https://github.com/JianXu95/RALLRec.
Privacy in LLM-based Recommendation: Recent Advances and Future Directions
Jun 03, 2024Nowadays, large language models (LLMs) have been integrated with conventional recommendation models to improve recommendation performance. However, while most of the existing works have focused on improving the model performance, the privacy issue has only received comparatively less attention. In this paper, we review recent advancements in privacy within LLM-based recommendation, categorizing them into privacy attacks and protection mechanisms. Additionally, we highlight several challenges and propose future directions for the community to address these critical problems.
Learning From Correctness Without Prompting Makes LLM Efficient Reasoner
Mar 28, 2024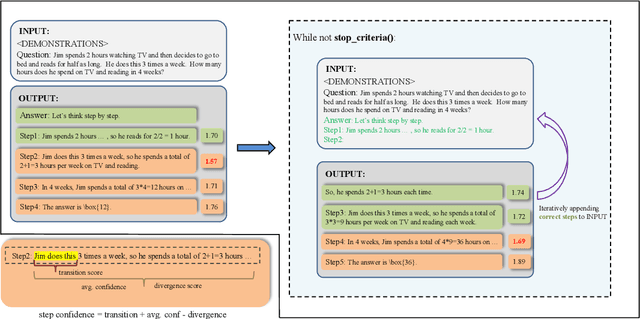



Large language models (LLMs) have demonstrated outstanding performance across various tasks, yet they still exhibit limitations such as hallucination, unfaithful reasoning, and toxic content. One potential approach to mitigate these issues is learning from human or external feedback (e.g. tools). In this paper, we introduce an intrinsic self-correct reasoning framework for LLMs that eliminates the need for human feedback, external tools, and handcraft prompts. The proposed framework, based on a multi-step reasoning paradigm \textbf{Le}arning from \textbf{Co}rrectness (\textsc{LeCo}), improves reasoning performance without needing to learn from errors. This paradigm prioritizes learning from correct reasoning steps, and a unique method to measure confidence for each reasoning step based on generation logits. Experimental results across various multi-step reasoning tasks demonstrate the effectiveness of the framework in improving reasoning performance with reduced token consumption.
Improved Quantization Strategies for Managing Heavy-tailed Gradients in Distributed Learning
Feb 02, 2024Gradient compression has surfaced as a key technique to address the challenge of communication efficiency in distributed learning. In distributed deep learning, however, it is observed that gradient distributions are heavy-tailed, with outliers significantly influencing the design of compression strategies. Existing parameter quantization methods experience performance degradation when this heavy-tailed feature is ignored. In this paper, we introduce a novel compression scheme specifically engineered for heavy-tailed gradients, which effectively combines gradient truncation with quantization. This scheme is adeptly implemented within a communication-limited distributed Stochastic Gradient Descent (SGD) framework. We consider a general family of heavy-tail gradients that follow a power-law distribution, we aim to minimize the error resulting from quantization, thereby determining optimal values for two critical parameters: the truncation threshold and the quantization density. We provide a theoretical analysis on the convergence error bound under both uniform and non-uniform quantization scenarios. Comparative experiments with other benchmarks demonstrate the effectiveness of our proposed method in managing the heavy-tailed gradients in a distributed learning environment.