 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Silence Is Golden: Can LLMs Learn to Abstain in Temporal QA and Beyond?
Feb 04, 2026Large language models (LLMs) rarely admit uncertainty, often producing fluent but misleading answers, rather than abstaining (i.e., refusing to answer). This weakness is even evident in temporal question answering, where models frequently ignore time-sensitive evidence and conflate facts across different time-periods. In this paper, we present the first empirical study of training LLMs with an abstention ability while reasoning about temporal QA. Existing approaches such as calibration might be unreliable in capturing uncertainty in complex reasoning. We instead frame abstention as a teachable skill and introduce a pipeline that couples Chain-of-Thought (CoT) supervision with Reinforcement Learning (RL) guided by abstention-aware rewards. Our goal is to systematically analyze how different information types and training techniques affect temporal reasoning with abstention behavior in LLMs. Through extensive experiments studying various methods, we find that RL yields strong empirical gains on reasoning: a model initialized by Qwen2.5-1.5B-Instruct surpasses GPT-4o by $3.46\%$ and $5.80\%$ in Exact Match on TimeQA-Easy and Hard, respectively. Moreover, it improves the True Positive rate on unanswerable questions by $20\%$ over a pure supervised fine-tuned (SFT) variant. Beyond performance, our analysis shows that SFT induces overconfidence and harms reliability, while RL improves prediction accuracy but exhibits similar risks. Finally, by comparing implicit reasoning cues (e.g., original context, temporal sub-context, knowledge graphs) with explicit CoT supervision, we find that implicit information provides limited benefit for reasoning with abstention. Our study provides new insights into how abstention and reasoning can be jointly optimized, providing a foundation for building more reliable LLMs.
Accordion-Thinking: Self-Regulated Step Summaries for Efficient and Readable LLM Reasoning
Feb 03, 2026Scaling test-time compute via long Chain-ofThought unlocks remarkable gains in reasoning capabilities, yet it faces practical limits due to the linear growth of KV cache and quadratic attention complexity. In this paper, we introduce Accordion-Thinking, an end-to-end framework where LLMs learn to self-regulate the granularity of the reasoning steps through dynamic summarization. This mechanism enables a Fold inference mode, where the model periodically summarizes its thought process and discards former thoughts to reduce dependency on historical tokens. We apply reinforcement learning to incentivize this capability further, uncovering a critical insight: the accuracy gap between the highly efficient Fold mode and the exhaustive Unfold mode progressively narrows and eventually vanishes over the course of training. This phenomenon demonstrates that the model learns to encode essential reasoning information into compact summaries, achieving effective compression of the reasoning context. Our Accordion-Thinker demonstrates that with learned self-compression, LLMs can tackle complex reasoning tasks with minimal dependency token overhead without compromising solution quality, and it achieves a 3x throughput while maintaining accuracy on a 48GB GPU memory configuration, while the structured step summaries provide a human-readable account of the reasoning process.
Merging Beyond: Streaming LLM Updates via Activation-Guided Rotations
Feb 03, 2026The escalating scale of Large Language Models (LLMs) necessitates efficient adaptation techniques. Model merging has gained prominence for its efficiency and controllability. However, existing merging techniques typically serve as post-hoc refinements or focus on mitigating task interference, often failing to capture the dynamic optimization benefits of supervised fine-tuning (SFT). In this work, we propose Streaming Merging, an innovative model updating paradigm that conceptualizes merging as an iterative optimization process. Central to this paradigm is \textbf{ARM} (\textbf{A}ctivation-guided \textbf{R}otation-aware \textbf{M}erging), a strategy designed to approximate gradient descent dynamics. By treating merging coefficients as learning rates and deriving rotation vectors from activation subspaces, ARM effectively steers parameter updates along data-driven trajectories. Unlike conventional linear interpolation, ARM aligns semantic subspaces to preserve the geometric structure of high-dimensional parameter evolution. Remarkably, ARM requires only early SFT checkpoints and, through iterative merging, surpasses the fully converged SFT model. Experimental results across model scales (1.7B to 14B) and diverse domains (e.g., math, code) demonstrate that ARM can transcend converged checkpoints. Extensive experiments show that ARM provides a scalable and lightweight framework for efficient model adaptation.
ACE: Attribution-Controlled Knowledge Editing for Multi-hop Factual Recall
Oct 09, 2025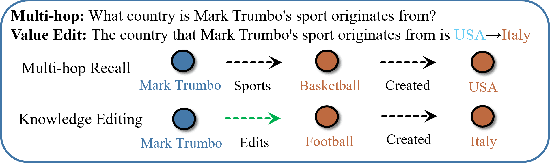

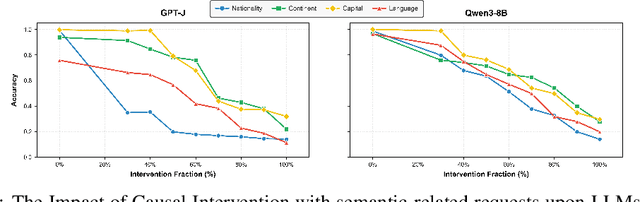
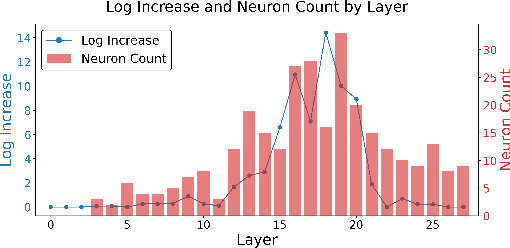
Large Language Models (LLMs) require efficient knowledge editing (KE) to update factual information, yet existing methods exhibit significant performance decay in multi-hop factual recall. This failure is particularly acute when edits involve intermediate implicit subjects within reasoning chains. Through causal analysis, we reveal that this limitation stems from an oversight of how chained knowledge is dynamically represented and utilized at the neuron level. We discover that during multi hop reasoning, implicit subjects function as query neurons, which sequentially activate corresponding value neurons across transformer layers to accumulate information toward the final answer, a dynamic prior KE work has overlooked. Guided by this insight, we propose ACE: Attribution-Controlled Knowledge Editing for Multi-hop Factual Recall, a framework that leverages neuron-level attribution to identify and edit these critical query-value (Q-V) pathways. ACE provides a mechanistically grounded solution for multi-hop KE, empirically outperforming state-of-the-art methods by 9.44% on GPT-J and 37.46% on Qwen3-8B. Our analysis further reveals more fine-grained activation patterns in Qwen3 and demonstrates that the semantic interpretability of value neurons is orchestrated by query-driven accumulation. These findings establish a new pathway for advancing KE capabilities based on the principled understanding of internal reasoning mechanisms.
When Inverse Data Outperforms: Exploring the Pitfalls of Mixed Data in Multi-Stage Fine-Tuning
Sep 16, 2025Existing work has shown that o1-level performance can be achieved with limited data distillation, but most existing methods focus on unidirectional supervised fine-tuning (SFT), overlooking the intricate interplay between diverse reasoning patterns. In this paper, we construct r1k, a high-quality reverse reasoning dataset derived by inverting 1,000 forward examples from s1k, and examine how SFT and Direct Preference Optimization (DPO) affect alignment under bidirectional reasoning objectives. SFT on r1k yields a 1.6%--6.8% accuracy improvement over s1k across evaluated benchmarks. However, naively mixing forward and reverse data during SFT weakens the directional distinction. Although DPO can partially recover this distinction, it also suppresses less preferred reasoning paths by shifting the probability mass toward irrelevant outputs. These findings suggest that mixed reasoning data introduce conflicting supervision signals, underscoring the need for robust and direction-aware alignment strategies.
ClimateViz: A Benchmark for Statistical Reasoning and Fact Verification on Scientific Charts
Jun 11, 2025Scientific fact-checking has mostly focused on text and tables, overlooking scientific charts, which are key for presenting quantitative evidence and statistical reasoning. We introduce ClimateViz, the first large-scale benchmark for scientific fact-checking using expert-curated scientific charts. ClimateViz contains 49,862 claims linked to 2,896 visualizations, each labeled as support, refute, or not enough information. To improve interpretability, each example includes structured knowledge graph explanations covering trends, comparisons, and causal relations. We evaluate state-of-the-art multimodal language models, including both proprietary and open-source systems, in zero-shot and few-shot settings. Results show that current models struggle with chart-based reasoning: even the best systems, such as Gemini 2.5 and InternVL 2.5, reach only 76.2 to 77.8 percent accuracy in label-only settings, far below human performance (89.3 and 92.7 percent). Explanation-augmented outputs improve performance in some models. We released our dataset and code alongside the paper.
TreeReview: A Dynamic Tree of Questions Framework for Deep and Efficient LLM-based Scientific Peer Review
Jun 09, 2025
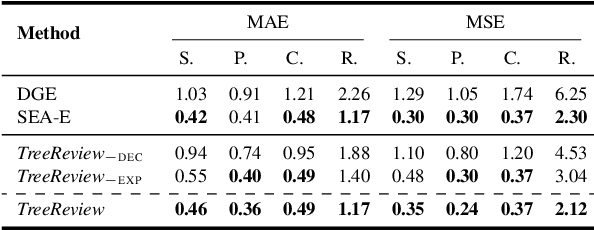
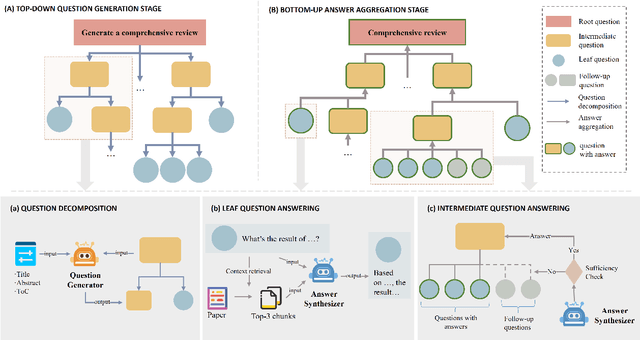
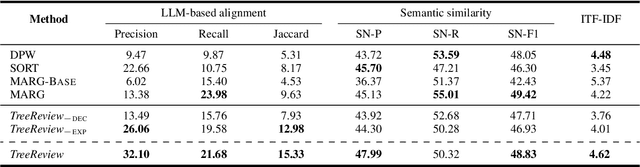
While Large Language Models (LLMs) have shown significant potential in assisting peer review, current methods often struggle to generate thorough and insightful reviews while maintaining efficiency. In this paper, we propose TreeReview, a novel framework that models paper review as a hierarchical and bidirectional question-answering process. TreeReview first constructs a tree of review questions by recursively decomposing high-level questions into fine-grained sub-questions and then resolves the question tree by iteratively aggregating answers from leaf to root to get the final review. Crucially, we incorporate a dynamic question expansion mechanism to enable deeper probing by generating follow-up questions when needed. We construct a benchmark derived from ICLR and NeurIPS venues to evaluate our method on full review generation and actionable feedback comments generation tasks. Experimental results of both LLM-based and human evaluation show that TreeReview outperforms strong baselines in providing comprehensive, in-depth, and expert-aligned review feedback, while reducing LLM token usage by up to 80% compared to computationally intensive approaches. Our code and benchmark dataset are available at https://github.com/YuanChang98/tree-review.
TreeRPO: Tree Relative Policy Optimization
Jun 05, 2025Large Language Models (LLMs) have shown remarkable reasoning capabilities through Reinforcement Learning with Verifiable Rewards (RLVR) methods. However, a key limitation of existing approaches is that rewards defined at the full trajectory level provide insufficient guidance for optimizing the intermediate steps of a reasoning process. To address this, we introduce \textbf{\name}, a novel method that estimates the mathematical expectations of rewards at various reasoning steps using tree sampling. Unlike prior methods that rely on a separate step reward model, \name directly estimates these rewards through this sampling process. Building on the group-relative reward training mechanism of GRPO, \name innovatively computes rewards based on step-level groups generated during tree sampling. This advancement allows \name to produce fine-grained and dense reward signals, significantly enhancing the learning process and overall performance of LLMs. Experimental results demonstrate that our \name algorithm substantially improves the average Pass@1 accuracy of Qwen-2.5-Math on test benchmarks, increasing it from 19.0\% to 35.5\%. Furthermore, \name significantly outperforms GRPO by 2.9\% in performance while simultaneously reducing the average response length by 18.1\%, showcasing its effectiveness and efficiency. Our code will be available at \href{https://github.com/yangzhch6/TreeRPO}{https://github.com/yangzhch6/TreeRPO}.
SwingArena: Competitive Programming Arena for Long-context GitHub Issue Solving
May 29, 2025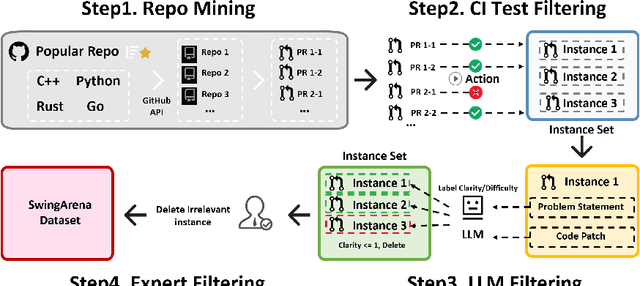
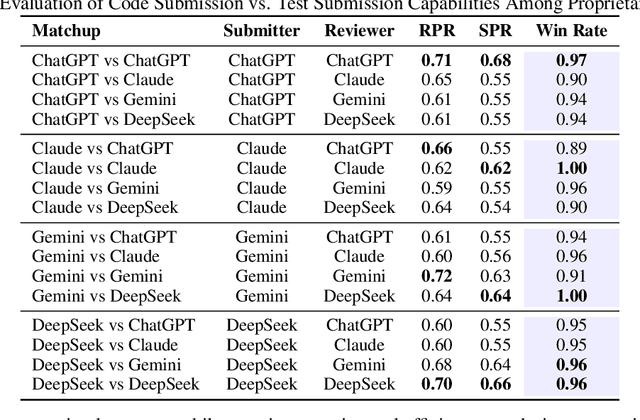
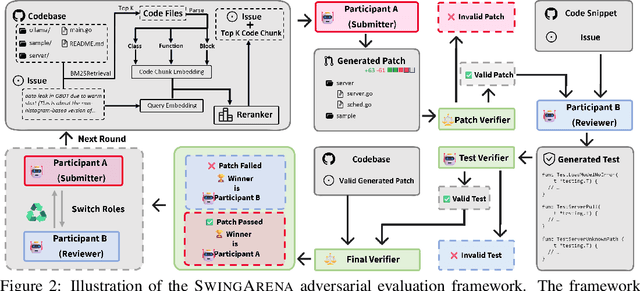
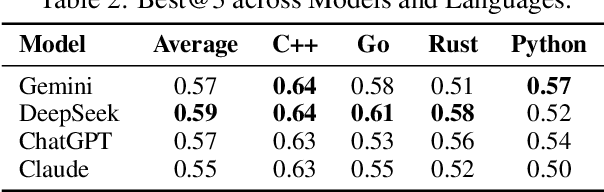
We present SwingArena, a competitive evaluation framework for Large Language Models (LLMs) that closely mirrors real-world software development workflows. Unlike traditional static benchmarks, SwingArena models the collaborative process of software iteration by pairing LLMs as submitters, who generate patches, and reviewers, who create test cases and verify the patches through continuous integration (CI) pipelines. To support these interactive evaluations, we introduce a retrieval-augmented code generation (RACG) module that efficiently handles long-context challenges by providing syntactically and semantically relevant code snippets from large codebases, supporting multiple programming languages (C++, Python, Rust, and Go). This enables the framework to scale across diverse tasks and contexts while respecting token limitations. Our experiments, using over 400 high-quality real-world GitHub issues selected from a pool of 2,300 issues, show that models like GPT-4o excel at aggressive patch generation, whereas DeepSeek and Gemini prioritize correctness in CI validation. SwingArena presents a scalable and extensible methodology for evaluating LLMs in realistic, CI-driven software development settings. More details are available on our project page: swing-bench.github.io
AVerImaTeC: A Dataset for Automatic Verification of Image-Text Claims with Evidence from the Web
May 23, 2025Textual claims are often accompanied by images to enhance their credibility and spread on social media, but this also raises concerns about the spread of misinformation. Existing datasets for automated verification of image-text claims remain limited, as they often consist of synthetic claims and lack evidence annotations to capture the reasoning behind the verdict. In this work, we introduce AVerImaTeC, a dataset consisting of 1,297 real-world image-text claims. Each claim is annotated with question-answer (QA) pairs containing evidence from the web, reflecting a decomposed reasoning regarding the verdict. We mitigate common challenges in fact-checking datasets such as contextual dependence, temporal leakage, and evidence insufficiency, via claim normalization, temporally constrained evidence annotation, and a two-stage sufficiency check. We assess the consistency of the annotation in AVerImaTeC via inter-annotator studies, achieving a $\kappa=0.742$ on verdicts and $74.7\%$ consistency on QA pairs. We also propose a novel evaluation method for evidence retrieval and conduct extensive experiments to establish baselines for verifying image-text claims using open-web evidence.