 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIME: A Multi-level Benchmark for Temporal Reasoning of LLMs in Real-World Scenarios
May 19, 2025Temporal reasoning is pivotal for Large Language Models (LLMs) to comprehend the real world. However, existing works neglect the real-world challenges for temporal reasoning: (1) intensive temporal information, (2) fast-changing event dynamics, and (3) complex temporal dependencies in social interactions. To bridge this gap, we propose a multi-level benchmark TIME, designed for temporal reasoning in real-world scenarios. TIME consists of 38,522 QA pairs, covering 3 levels with 11 fine-grained sub-tasks. This benchmark encompasses 3 sub-datasets reflecting different real-world challenges: TIME-Wiki, TIME-News, and TIME-Dial. We conduct extensive experiments on reasoning models and non-reasoning models. And we conducted an in-depth analysis of temporal reasoning performance across diverse real-world scenarios and tasks, and summarized the impact of test-time scaling on temporal reasoning capabilities. Additionally, we release TIME-Lite, a human-annotated subset to foster future research and standardized evaluation in temporal reasoning. The code is available at https://github.com/sylvain-wei/TIME , and the dataset is available at https://huggingface.co/datasets/SylvainWei/TIME .
DocPuzzle: A Process-Aware Benchmark for Evaluating Realistic Long-Context Reasoning Capabilities
Feb 25, 2025We present DocPuzzle, a rigorously constructed benchmark for evaluating long-context reasoning capabilities in large language models (LLMs). This benchmark comprises 100 expert-level QA problems requiring multi-step reasoning over long real-world documents. To ensure the task quality and complexity, we implement a human-AI collaborative annotation-validation pipeline. DocPuzzle introduces an innovative evaluation framework that mitigates guessing bias through checklist-guided process analysis, establishing new standards for assessing reasoning capacities in LLMs. Our evaluation results show that: 1)Advanced slow-thinking reasoning models like o1-preview(69.7%) and DeepSeek-R1(66.3%) significantly outperform best general instruct models like Claude 3.5 Sonnet(57.7%); 2)Distilled reasoning models like DeepSeek-R1-Distill-Qwen-32B(41.3%) falls far behind the teacher model, suggesting challenges to maintain the generalization of reasoning capabilities relying solely on distillation.
Neighbors Are Not Strangers: Improving Non-Autoregressive Translation under Low-Frequency Lexical Constraints
Apr 28, 2022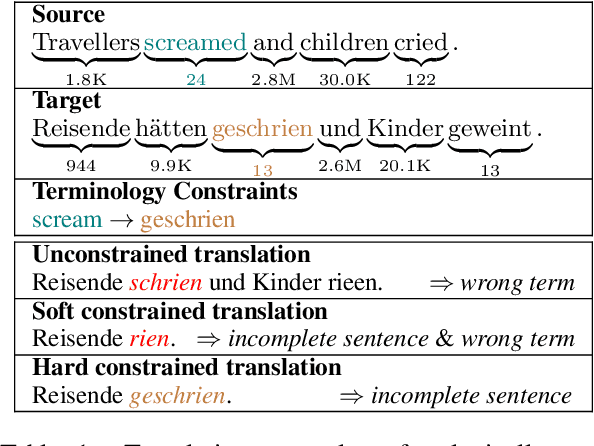
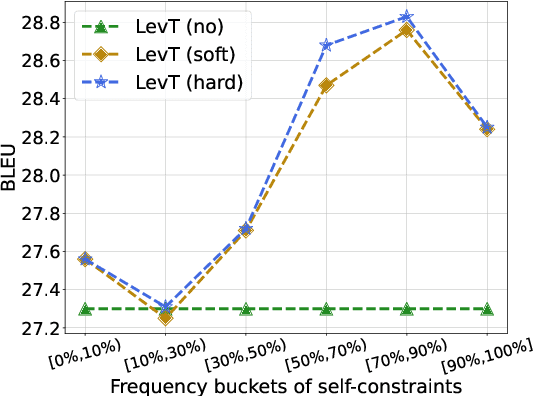

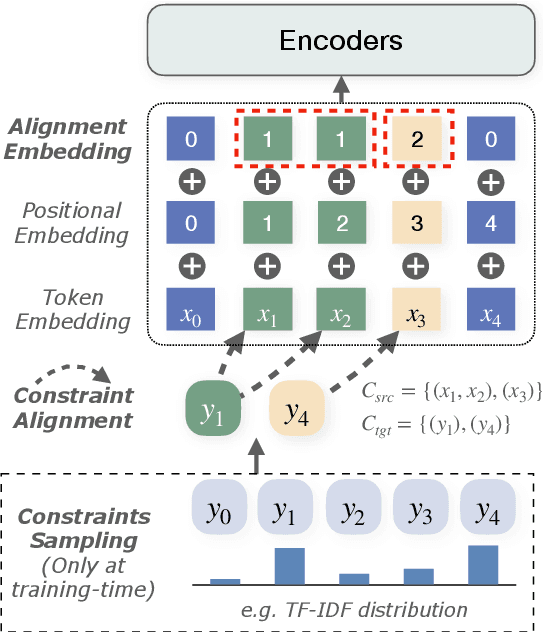
However, current autoregressive approaches suffer from high latency. In this paper, we focus on non-autoregressive translation (NAT) for this problem for its efficiency advantage. We identify that current constrained NAT models, which are based on iterative editing, do not handle low-frequency constraints well. To this end, we propose a plug-in algorithm for this line of work, i.e., Aligned Constrained Training (ACT), which alleviates this problem by familiarizing the model with the source-side context of the constraints. Experiments on the general and domain datasets show that our model improves over the backbone constrained NAT model in constraint preservation and translation quality, especially for rare constraints.