 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocPuzzle: A Process-Aware Benchmark for Evaluating Realistic Long-Context Reasoning Capabilities
Feb 25, 2025We present DocPuzzle, a rigorously constructed benchmark for evaluating long-context reasoning capabilities in large language models (LLMs). This benchmark comprises 100 expert-level QA problems requiring multi-step reasoning over long real-world documents. To ensure the task quality and complexity, we implement a human-AI collaborative annotation-validation pipeline. DocPuzzle introduces an innovative evaluation framework that mitigates guessing bias through checklist-guided process analysis, establishing new standards for assessing reasoning capacities in LLMs. Our evaluation results show that: 1)Advanced slow-thinking reasoning models like o1-preview(69.7%) and DeepSeek-R1(66.3%) significantly outperform best general instruct models like Claude 3.5 Sonnet(57.7%); 2)Distilled reasoning models like DeepSeek-R1-Distill-Qwen-32B(41.3%) falls far behind the teacher model, suggesting challenges to maintain the generalization of reasoning capabilities relying solely on distillation.
Android in the Zoo: Chain-of-Action-Thought for GUI Agents
Mar 05, 2024



Large language model (LLM) leads to a surge of autonomous GUI agents for smartphone, which completes a task triggered by natural language through predicting a sequence of actions of API. Even though the task highly relies on past actions and visual observations, existing studies typical consider little semantic information carried out by intermediate screenshots and screen operations. To address this, this work presents Chain-of-Action-Thought (dubbed CoAT), which takes the description of the previous actions, the current screen, and more importantly the action thinking of what actions should be performed and the outcomes led by the chosen action. We demonstrate that, in a zero-shot setting upon an off-the-shell LLM, CoAT significantly improves the goal progress compared to standard context modeling. To further facilitate the research in this line, we construct a benchmark Android-In-The-Zoo (AitZ), which contains 18,643 screen-action pairs together with chain-of-action-thought annotations. Experiments show that fine-tuning a 200M model on our AitZ dataset achieves on par performance with CogAgent-Chat-18B.
DocStormer: Revitalizing Multi-Degraded Colored Document Images to Pristine PDF
Oct 27, 2023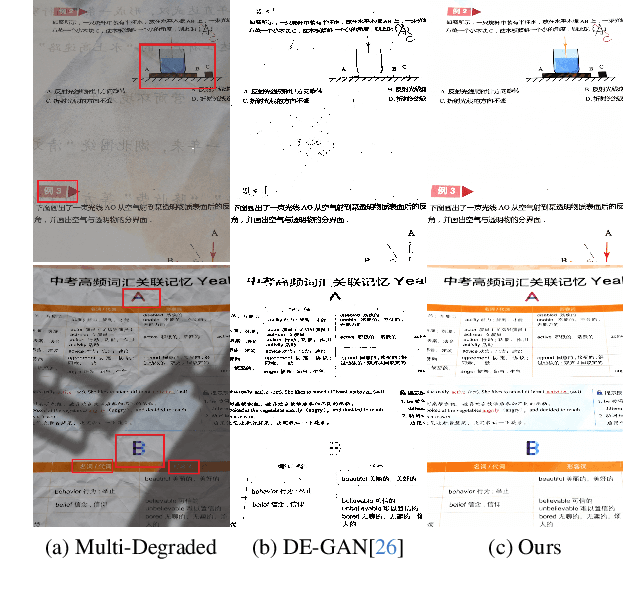


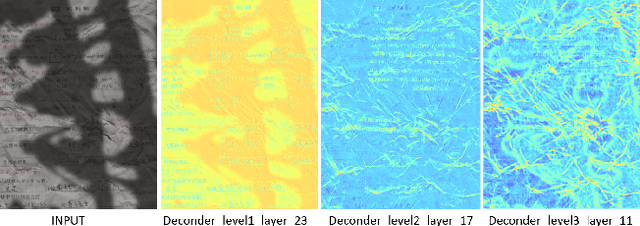
For capturing colored document images, e.g. posters and magazines, it is common that multiple degradations such as shadows, wrinkles, etc., are simultaneously introduced due to external factors. Restoring multi-degraded colored document images is a great challenge, yet overlooked, as most existing algorithms focus on enhancing color-ignored document images via binarization. Thus, we propose DocStormer, a novel algorithm designed to restore multi-degraded colored documents to their potential pristine PDF. The contributions are: firstly, we propose a "Perceive-then-Restore" paradigm with a reinforced transformer block, which more effectively encodes and utilizes the distribution of degradations. Secondly, we are the first to utilize GAN and pristine PDF magazine images to narrow the distribution gap between the enhanced results and PDF images, in pursuit of less degradation and better visual quality. Thirdly, we propose a non-parametric strategy, PFILI, which enables a smaller training scale and larger testing resolutions with acceptable detail trade-off, while saving memory and inference time. Fourthly, we are the first to propose a novel Multi-Degraded Colored Document image Enhancing dataset, named MD-CDE, for both training and evaluation. Experimental results show that the DocStormer exhibits superior performance, capable of revitalizing multi-degraded colored documents into their potential pristine digital versions, which fills the current academic gap from the perspective of method, data, and task.