 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAGNET: Towards Adaptive GUI Agents with Memory-Driven Knowledge Evolution
Jan 27, 2026Mobile GUI agents powered by large foundation models enable autonomous task execution, but frequent updates altering UI appearance and reorganizing workflows cause agents trained on historical data to fail. Despite surface changes, functional semantics and task intents remain fundamentally stable. Building on this insight, we introduce MAGNET, a memory-driven adaptive agent framework with dual-level memory: stationary memory linking diverse visual features to stable functional semantics for robust action grounding and procedural memory capturing stable task intents across varying workflows. We propose a dynamic memory evolution mechanism that continuously refines both memories by prioritizing frequently accessed knowledge. Online benchmark AndroidWorld evaluations show substantial improvements over baselines, while offline benchmarks confirm consistent gains under distribution shifts. These results validate that leveraging stable structures across interface changes improves agent performance and generalization in evolving software environments.
A Graph Prompt Fine-Tuning Method for WSN Spatio-Temporal Correlation Anomaly Detection
Jan 19, 2026Anomaly detection of multi-temporal modal data in Wireless Sensor Network (WSN) can provide an important guarantee for reliable network operation. Existing anomaly detection methods in multi-temporal modal data scenarios have the problems of insufficient extraction of spatio-temporal correlation features, high cost of anomaly sample category annotation, and imbalance of anomaly samples. In this paper, a graph neural network anomaly detection backbone network incorporating spatio-temporal correlation features and a multi-task self-supervised training strategy of "pre-training - graph prompting - fine-tuning" are designed for the characteristics of WSN graph structure data. First, the anomaly detection backbone network is designed by improving the Mamba model based on a multi-scale strategy and inter-modal fusion method, and combining it with a variational graph convolution module, which is capable of fully extracting spatio-temporal correlation features in the multi-node, multi-temporal modal scenarios of WSNs. Secondly, we design a three-subtask learning "pre-training" method with no-negative comparative learning, prediction, and reconstruction to learn generic features of WSN data samples from unlabeled data, and design a "graph prompting-fine-tuning" mechanism to guide the pre-trained self-supervised learning. The model is fine-tuned through the "graph prompting-fine-tuning" mechanism to guide the pre-trained self-supervised learning model to complete the parameter fine-tuning, thereby reducing the training cost and enhancing the detection generalization performance. The F1 metrics obtained from experiments on the public dataset and the actual collected dataset are up to 91.30% and 92.31%, respectively, which provides better detection performance and generalization ability than existing methods designed by the method.
SpatialNav: Leveraging Spatial Scene Graphs for Zero-Shot Vision-and-Language Navigation
Jan 11, 2026Although learning-based vision-and-language navigation (VLN) agents can learn spatial knowledge implicitly from large-scale training data, zero-shot VLN agents lack this process, relying primarily on local observations for navigation, which leads to inefficient exploration and a significant performance gap. To deal with the problem, we consider a zero-shot VLN setting that agents are allowed to fully explore the environment before task execution. Then, we construct the Spatial Scene Graph (SSG) to explicitly capture global spatial structure and semantics in the explored environment. Based on the SSG, we introduce SpatialNav, a zero-shot VLN agent that integrates an agent-centric spatial map, a compass-aligned visual representation, and a remote object localization strategy for efficient navigation. Comprehensive experiments in both discrete and continuous environments demonstrate that SpatialNav significantly outperforms existing zero-shot agents and clearly narrows the gap with state-of-the-art learning-based methods. Such results highlight the importance of global spatial representations for generalizable navigation.
A robust and compliant robotic assembly control strategy for batch precision assembly task with uncertain fit types and fit amounts
Aug 17, 2025In some high-precision industrial applications, robots are deployed to perform precision assembly tasks on mass batches of manufactured pegs and holes. If the peg and hole are designed with transition fit, machining errors may lead to either a clearance or an interference fit for a specific pair of components, with uncertain fit amounts. This paper focuses on the robotic batch precision assembly task involving components with uncertain fit types and fit amounts, and proposes an efficient methodology to construct the robust and compliant assembly control strategy. Specifically, the batch precision assembly task is decomposed into multiple deterministic subtasks, and a force-vision fusion controller-driven reinforcement learning method and a multi-task reinforcement learning training method (FVFC-MTRL) are proposed to jointly learn multiple compliance control strategies for these subtasks. Subsequently, the multi-teacher policy distillation approach is designed to integrate multiple trained strategies into a unified student network, thereby establishing a robust control strategy. Real-world experiments demonstrate that the proposed method successfully constructs the robust control strategy for high-precision assembly task with different fit types and fit amounts. Moreover, the MTRL framework significantly improves training efficiency, and the final developed control strategy achieves superior force compliance and higher success rate compared with many existing methods.
AutoJudger: An Agent-Driven Framework for Efficient Benchmarking of MLLMs
May 27, 2025Evaluating multimodal large language models (MLLMs) is increasingly expensive, as the growing size and cross-modality complexity of benchmarks demand significant scoring efforts. To tackle with this difficulty, we introduce AutoJudger, an agent-driven framework for efficient and adaptive benchmarking of MLLMs that tackles this escalating cost. AutoJudger employs the Item Response Theory (IRT) to estimate the question difficulty and an autonomous evaluation agent to dynamically select the most informative test questions based on the model's real-time performance. Specifically, AutoJudger incorporates two pivotal components: a semantic-aware retrieval mechanism to ensure that selected questions cover diverse and challenging scenarios across both vision and language modalities, and a dynamic memory that maintains contextual statistics of previously evaluated questions to guide coherent and globally informed question selection throughout the evaluation process. Extensive experiments on four representative multimodal benchmarks demonstrate that our adaptive framework dramatically reduces evaluation expenses, i.e. AutoJudger uses only 4% of the data to achieve over 90% ranking accuracy with the full benchmark evaluation on MMT-Bench.
TextHawk2: A Large Vision-Language Model Excels in Bilingual OCR and Grounding with 16x Fewer Tokens
Oct 07, 2024Reading dense text and locating objects within images are fundamental abilities for Large Vision-Language Models (LVLMs) tasked with advanced jobs. Previous LVLMs, including superior proprietary models like GPT-4o, have struggled to excel in both tasks simultaneously. Moreover, previous LVLMs with fine-grained perception cost thousands of tokens per image, making them resource-intensive. We present TextHawk2, a bilingual LVLM featuring efficient fine-grained perception and demonstrating cutting-edge performance across general-purpose, OCR, and grounding tasks with 16 times fewer image tokens. Critical improvements include: (1) Token Compression: Building on the efficient architecture of its predecessor, TextHawk2 significantly reduces the number of tokens per image by 16 times, facilitating training and deployment of the TextHawk series with minimal resources. (2) Visual Encoder Reinforcement: We enhance the visual encoder through LVLM co-training, unlocking its potential for previously unseen tasks like Chinese OCR and grounding. (3) Data Diversity: We maintain a comparable scale of 100 million samples while diversifying the sources of pre-training data. We assess TextHawk2 across multiple benchmarks, where it consistently delivers superior performance and outperforms closed-source models of similar scale, such as achieving 78.4% accuracy on OCRBench, 81.4% accuracy on ChartQA, 89.6% ANLS on DocVQA, and 88.1% accuracy@0.5 on RefCOCOg-test.
VoCoT: Unleashing Visually Grounded Multi-Step Reasoning in Large Multi-Modal Models
May 28, 2024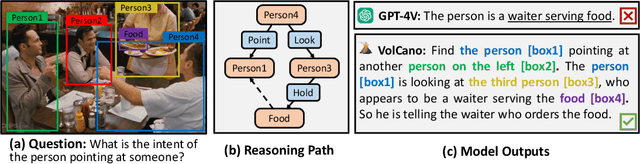

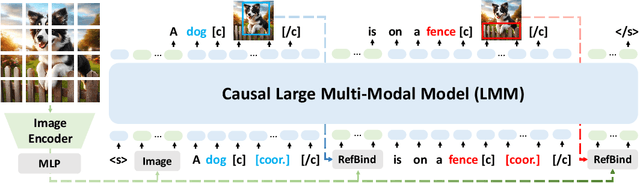
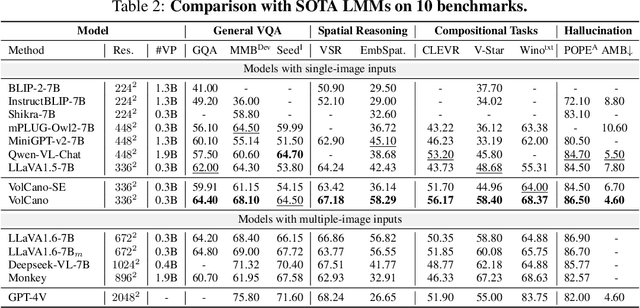
While large multi-modal models (LMMs) have exhibited impressive capabilities across diverse tasks, their effectiveness in handling complex tasks has been limited by the prevailing single-step reasoning paradigm. To this end, this paper proposes VoCoT, a multi-step Visually grounded object-centric Chain-of-Thought reasoning framework tailored for inference with LMMs. VoCoT is characterized by two key features: (1) object-centric reasoning paths that revolve around cross-modal shared object-level information, and (2) visually grounded representation of object concepts in a multi-modal interleaved and aligned manner, which effectively bridges the modality gap within LMMs during long-term generation. Additionally, we construct an instruction dataset to facilitate LMMs in adapting to reasoning with VoCoT. By introducing VoCoT into the prevalent open-source LMM architecture, we introduce VolCano. With only 7B parameters and limited input resolution, VolCano demonstrates excellent performance across various scenarios, surpassing SOTA models, including GPT-4V, in tasks requiring complex reasoning. Our code, data and model will be available at https://github.com/RupertLuo/VoCoT.
DELAN: Dual-Level Alignment for Vision-and-Language Navigation by Cross-Modal Contrastive Learning
Apr 02, 2024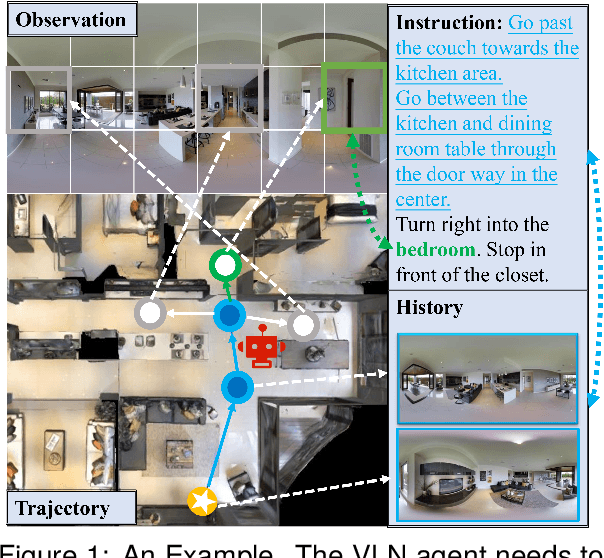

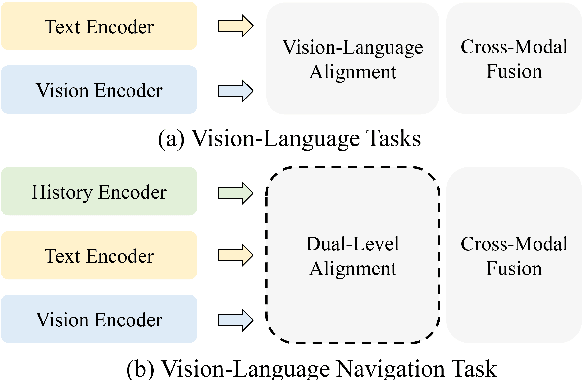

Vision-and-Language navigation (VLN) requires an agent to navigate in unseen environment by following natural language instruction. For task completion, the agent needs to align and integrate various navigation modalities, including instruction, observation and navigation history. Existing works primarily concentrate on cross-modal attention at the fusion stage to achieve this objective. Nevertheless, modality features generated by disparate uni-encoders reside in their own spaces, leading to a decline in the quality of cross-modal fusion and decision. To address this problem, we propose a Dual-levEL AligNment (DELAN) framework by cross-modal contrastive learning. This framework is designed to align various navigation-related modalities before fusion, thereby enhancing cross-modal interaction and action decision-making. Specifically, we divide the pre-fusion alignment into dual levels: instruction-history level and landmark-observation level according to their semantic correlations. We also reconstruct a dual-level instruction for adaptation to the dual-level alignment. As the training signals for pre-fusion alignment are extremely limited, self-supervised contrastive learning strategies are employed to enforce the matching between different modalities. Our approach seamlessly integrates with the majority of existing models, resulting in improved navigation performance on various VLN benchmarks, including R2R, R4R, RxR and CVDN.
Android in the Zoo: Chain-of-Action-Thought for GUI Agents
Mar 05, 2024



Large language model (LLM) leads to a surge of autonomous GUI agents for smartphone, which completes a task triggered by natural language through predicting a sequence of actions of API. Even though the task highly relies on past actions and visual observations, existing studies typical consider little semantic information carried out by intermediate screenshots and screen operations. To address this, this work presents Chain-of-Action-Thought (dubbed CoAT), which takes the description of the previous actions, the current screen, and more importantly the action thinking of what actions should be performed and the outcomes led by the chosen action. We demonstrate that, in a zero-shot setting upon an off-the-shell LLM, CoAT significantly improves the goal progress compared to standard context modeling. To further facilitate the research in this line, we construct a benchmark Android-In-The-Zoo (AitZ), which contains 18,643 screen-action pairs together with chain-of-action-thought annotations. Experiments show that fine-tuning a 200M model on our AitZ dataset achieves on par performance with CogAgent-Chat-18B.
ReForm-Eval: Evaluating Large Vision Language Models via Unified Re-Formulation of Task-Oriented Benchmarks
Oct 17, 2023



Recent years have witnessed remarkable progress in the development of large vision-language models (LVLMs). Benefiting from the strong language backbones and efficient cross-modal alignment strategies, LVLMs exhibit surprising capabilities to perceive visual signals and perform visually grounded reasoning. However, the capabilities of LVLMs have not been comprehensively and quantitatively evaluate. Most existing multi-modal benchmarks require task-oriented input-output formats, posing great challenges to automatically assess the free-form text output of LVLMs. To effectively leverage the annotations available in existing benchmarks and reduce the manual effort required for constructing new benchmarks, we propose to re-formulate existing benchmarks into unified LVLM-compatible formats. Through systematic data collection and reformulation, we present the ReForm-Eval benchmark, offering substantial data for evaluating various capabilities of LVLMs. Based on ReForm-Eval, we conduct extensive experiments, thoroughly analyze the strengths and weaknesses of existing LVLMs, and identify the underlying factors. Our benchmark and evaluation framework will be open-sourced as a cornerstone for advancing the development of LVLMs.