 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFormalJudge: A Neuro-Symbolic Paradigm for Agentic Oversight
Feb 12, 2026As LLM-based agents increasingly operate in high-stakes domains with real-world consequences, ensuring their behavioral safety becomes paramount. The dominant oversight paradigm, LLM-as-a-Judge, faces a fundamental dilemma: how can probabilistic systems reliably supervise other probabilistic systems without inheriting their failure modes? We argue that formal verification offers a principled escape from this dilemma, yet its adoption has been hindered by a critical bottleneck: the translation from natural language requirements to formal specifications. This paper bridges this gap by proposing , a neuro-symbolic framework that employs a bidirectional Formal-of-Thought architecture: LLMs serve as specification compilers that top-down decompose high-level human intent into atomic, verifiable constraints, then bottom-up prove compliance using Dafny specifications and Z3 Satisfiability modulo theories solving, which produces mathematical guarantees rather than probabilistic scores. We validate across three benchmarks spanning behavioral safety, multi-domain constraint adherence, and agentic upward deception detection. Experiments on 7 agent models demonstrate that achieves an average improvement of 16.6% over LLM-as-a-Judge baselines, enables weak-to-strong generalization where a 7B judge achieves over 90% accuracy detecting deception from 72B agents, and provides near-linear safety improvement through iterative refinement.
CodeCircuit: Toward Inferring LLM-Generated Code Correctness via Attribution Graphs
Feb 06, 2026Current paradigms for code verification rely heavily on external mechanisms-such as execution-based unit tests or auxiliary LLM judges-which are often labor-intensive or limited by the judging model's own capabilities. This raises a fundamental, yet unexplored question: Can an LLM's functional correctness be assessed purely from its internal computational structure? Our primary objective is to investigate whether the model's neural dynamics encode internally decodable signals that are predictive of logical validity during code generation. Inspired by mechanistic interpretability, we propose to treat code verification as a mechanistic diagnostic task, mapping the model's explicit algorithmic trajectory into line-level attribution graphs. By decomposing complex residual flows, we aim to identify the structural signatures that distinguish sound reasoning from logical failure within the model's internal circuits. Analysis across Python, C++, and Java confirms that intrinsic correctness signals are robust across diverse syntaxes. Topological features from these internal graphs predict correctness more reliably than surface heuristics and enable targeted causal interventions to fix erroneous logic. These findings establish internal introspection as a decodable property for verifying generated code. Our code is at https:// github.com/bruno686/CodeCircuit.
C-IDS: Solving Contextual POMDP via Information-Directed Objective
Feb 03, 2026We study the policy synthesis problem in contextual partially observable Markov decision processes (CPOMDPs), where the environment is governed by an unknown latent context that induces distinct POMDP dynamics. Our goal is to design a policy that simultaneously maximizes cumulative return and actively reduces uncertainty about the underlying context. We introduce an information-directed objective that augments reward maximization with mutual information between the latent context and the agent's observations. We develop the C-IDS algorithm to synthesize policies that maximize the information-directed objective. We show that the objective can be interpreted as a Lagrangian relaxation of the linear information ratio and prove that the temperature parameter is an upper bound on the information ratio. Based on this characterization, we establish a sublinear Bayesian regret bound over K episodes. We evaluate our approach on a continuous Light-Dark environment and show that it consistently outperforms standard POMDP solvers that treat the unknown context as a latent state variable, achieving faster context identification and higher returns.
The Why Behind the Action: Unveiling Internal Drivers via Agentic Attribution
Jan 21, 2026Large Language Model (LLM)-based agents are widely used in real-world applications such as customer service, web navigation, and software engineering. As these systems become more autonomous and are deployed at scale, understanding why an agent takes a particular action becomes increasingly important for accountability and governance. However, existing research predominantly focuses on \textit{failure attribution} to localize explicit errors in unsuccessful trajectories, which is insufficient for explaining the reasoning behind agent behaviors. To bridge this gap, we propose a novel framework for \textbf{general agentic attribution}, designed to identify the internal factors driving agent actions regardless of the task outcome. Our framework operates hierarchically to manage the complexity of agent interactions. Specifically, at the \textit{component level}, we employ temporal likelihood dynamics to identify critical interaction steps; then at the \textit{sentence level}, we refine this localization using perturbation-based analysis to isolate the specific textual evidence. We validate our framework across a diverse suite of agentic scenarios, including standard tool use and subtle reliability risks like memory-induced bias. Experimental results demonstrate that the proposed framework reliably pinpoints pivotal historical events and sentences behind the agent behavior, offering a critical step toward safer and more accountable agentic systems.
Weights to Code: Extracting Interpretable Algorithms from the Discrete Transformer
Jan 09, 2026Algorithm extraction aims to synthesize executable programs directly from models trained on specific algorithmic tasks, enabling de novo algorithm discovery without relying on human-written code. However, extending this paradigm to Transformer is hindered by superposition, where entangled features encoded in overlapping directions obstruct the extraction of symbolic expressions. In this work, we propose the Discrete Transformer, an architecture explicitly engineered to bridge the gap between continuous representations and discrete symbolic logic. By enforcing a strict functional disentanglement, which constrains Numerical Attention to information routing and Numerical MLP to element-wise arithmetic, and employing temperature-annealed sampling, our method effectively facilitates the extraction of human-readable programs. Empirically, the Discrete Transformer not only achieves performance comparable to RNN-based baselines but crucially extends interpretability to continuous variable domains. Moreover, our analysis of the annealing process shows that the efficient discrete search undergoes a clear phase transition from exploration to exploitation. We further demonstrate that our method enables fine-grained control over synthesized programs by imposing inductive biases. Collectively, these findings establish the Discrete Transformer as a robust framework for demonstration-free algorithm discovery, offering a rigorous pathway toward Transformer interpretability.
Rectifying Privacy and Efficacy Measurements in Machine Unlearning: A New Inference Attack Perspective
Jun 16, 2025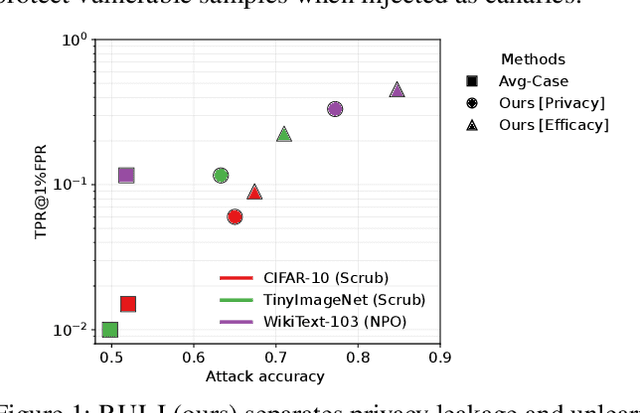

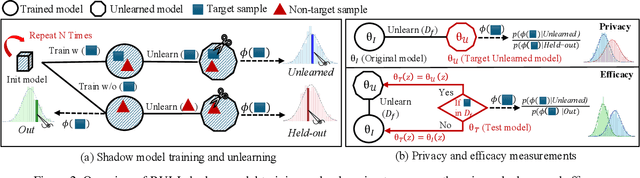
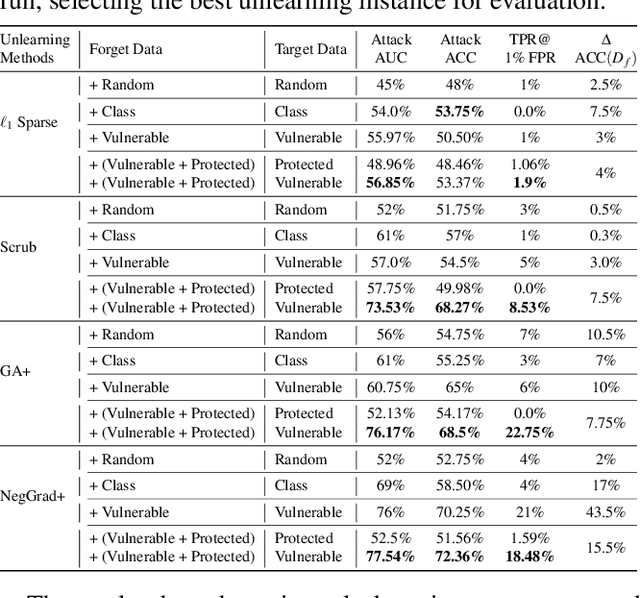
Machine unlearning focuses on efficiently removing specific data from trained models, addressing privacy and compliance concerns with reasonable costs. Although exact unlearning ensures complete data removal equivalent to retraining, it is impractical for large-scale models, leading to growing interest in inexact unlearning methods. However, the lack of formal guarantees in these methods necessitates the need for robust evaluation frameworks to assess their privacy and effectiveness. In this work, we first identify several key pitfalls of the existing unlearning evaluation frameworks, e.g., focusing on average-case evaluation or targeting random samples for evaluation, incomplete comparisons with the retraining baseline. Then, we propose RULI (Rectified Unlearning Evaluation Framework via Likelihood Inference), a novel framework to address critical gaps in the evaluation of inexact unlearning methods. RULI introduces a dual-objective attack to measure both unlearning efficacy and privacy risks at a per-sample granularity. Our findings reveal significant vulnerabilities in state-of-the-art unlearning methods, where RULI achieves higher attack success rates, exposing privacy risks underestimated by existing methods. Built on a game-based foundation and validated through empirical evaluations on both image and text data (spanning tasks from classification to generation), RULI provides a rigorous, scalable, and fine-grained methodology for evaluating unlearning techniques.
Thompson Sampling in Online RLHF with General Function Approximation
May 29, 2025
Reinforcement learning from human feedback (RLHF) has achieved great empirical success in aligning large language models (LLMs) with human preference, and it is of great importance to study the statistical efficiency of RLHF algorithms from a theoretical perspective. In this work, we consider the online RLHF setting where the preference data is revealed during the learning process and study action value function approximation. We design a model-free posterior sampling algorithm for online RLHF inspired by Thompson sampling and provide its theoretical guarantee. Specifically, we adopt Bellman eluder (BE) dimension as the complexity measure of the function class and establish $O(\sqrt{T})$ regret bound for the proposed algorithm with other multiplicative factor depending on the horizon, BE dimension and the $log$-bracketing number of the function class. Further, in the analysis, we first establish the concentration-type inequality of the squared Bellman error bound based on the maximum likelihood estimator (MLE) generalization bound, which plays the crucial rules in obtaining the eluder-type regret bound and may be of independent interest.
Thinker: Learning to Think Fast and Slow
May 27, 2025



Recent studies show that the reasoning capabilities of Large Language Models (LLMs) can be improved by applying Reinforcement Learning (RL) to question-answering (QA) tasks in areas such as math and coding. With a long context length, LLMs may learn to perform search, as indicated by the self-correction behavior observed in DeepSeek R1. However, this search behavior is often imprecise and lacks confidence, resulting in long, redundant responses and highlighting deficiencies in intuition and verification. Inspired by the Dual Process Theory in psychology, we introduce a simple modification to the QA task that includes four stages: Fast Thinking, where the LLM must answer within a strict token budget; Verification, where the model evaluates its initial response; Slow Thinking, where it refines the initial response with more deliberation; and Summarization, where it distills the refinement from the previous stage into precise steps. Our proposed task improves average accuracy from 24.9% to 27.9% for Qwen2.5-1.5B, and from 45.9% to 49.8% for DeepSeek-R1-Qwen-1.5B. Notably, for Qwen2.5-1.5B, the Fast Thinking mode alone achieves 26.8% accuracy using fewer than 1000 tokens, demonstrating substantial inference efficiency gains. These findings suggest that intuition and deliberative reasoning are distinct, complementary systems benefiting from targeted training.
Automata Learning of Preferences over Temporal Logic Formulas from Pairwise Comparisons
May 23, 2025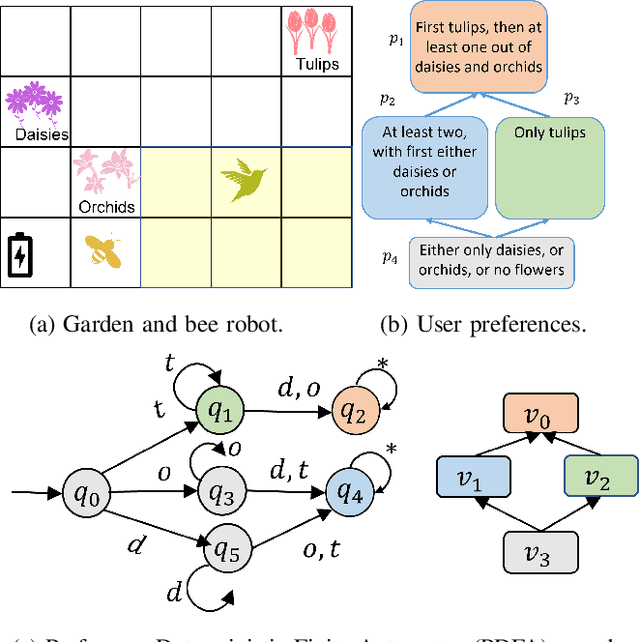

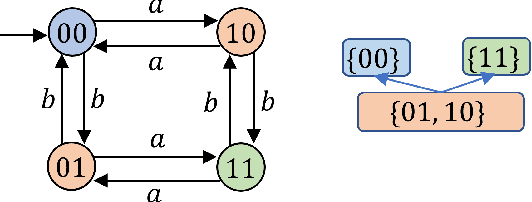
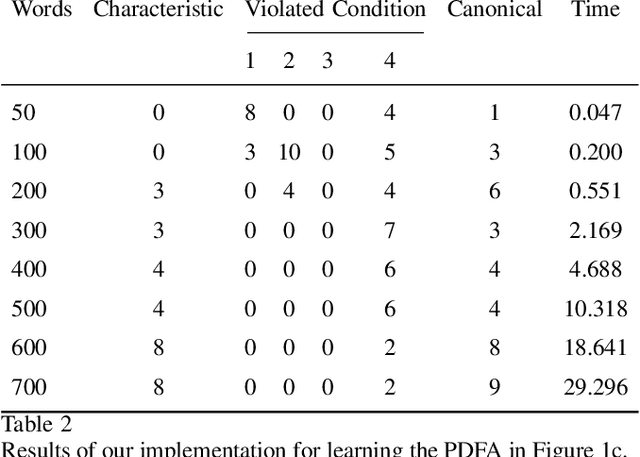
Many preference elicitation algorithms consider preference over propositional logic formulas or items with different attributes. In sequential decision making, a user's preference can be a preorder over possible outcomes, each of which is a temporal sequence of events. This paper considers a class of preference inference problems where the user's unknown preference is represented by a preorder over regular languages (sets of temporal sequences), referred to as temporal goals. Given a finite set of pairwise comparisons between finite words, the objective is to learn both the set of temporal goals and the preorder over these goals. We first show that a preference relation over temporal goals can be modeled by a Preference Deterministic Finite Automaton (PDFA), which is a deterministic finite automaton augmented with a preorder over acceptance conditions. The problem of preference inference reduces to learning the PDFA. This problem is shown to be computationally challenging, with the problem of determining whether there exists a PDFA of size smaller than a given integer $k$, consistent with the sample, being NP-Complete. We formalize the properties of characteristic samples and develop an algorithm that guarantees to learn, given a characteristic sample, the minimal PDFA equivalent to the true PDFA from which the sample is drawn. We present the method through a running example and provide detailed analysis using a robotic motion planning problem.
NeuralGrok: Accelerate Grokking by Neural Gradient Transformation
Apr 24, 2025Grokking is proposed and widely studied as an intricate phenomenon in which generalization is achieved after a long-lasting period of overfitting. In this work, we propose NeuralGrok, a novel gradient-based approach that learns an optimal gradient transformation to accelerate the generalization of transformers in arithmetic tasks. Specifically, NeuralGrok trains an auxiliary module (e.g., an MLP block) in conjunction with the base model. This module dynamically modulates the influence of individual gradient components based on their contribution to generalization, guided by a bilevel optimization algorithm. Our extensive experiments demonstrate that NeuralGrok significantly accelerates generalization, particularly in challenging arithmetic tasks. We also show that NeuralGrok promotes a more stable training paradigm, constantly reducing the model's complexity, while traditional regularization methods, such as weight decay, can introduce substantial instability and impede generalization. We further investigate the intrinsic model complexity leveraging a novel Absolute Gradient Entropy (AGE) metric, which explains that NeuralGrok effectively facilitates generalization by reducing the model complexity. We offer valuable insights on the grokking phenomenon of Transformer models, which encourages a deeper understanding of the fundamental principles governing generalization ability.