 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Attacks on Locally Private Graph Neural Networks
Mar 21, 2026Graph neural network (GNN) is a powerful tool for analyzing graph-structured data. However, their vulnerability to adversarial attacks raises serious concerns, especially when dealing with sensitive information. Local Differential Privacy (LDP) offers a privacy-preserving framework for training GNNs, but its impact on adversarial robustness remains underexplored. This paper investigates adversarial attacks on LDP-protected GNNs. We explore how the privacy guarantees of LDP can be leveraged or hindered by adversarial perturbations. The effectiveness of existing attack methods on LDP-protected GNNs are analyzed and potential challenges in crafting adversarial examples under LDP constraints are discussed. Additionally, we suggest directions for defending LDP-protected GNNs against adversarial attacks. This work investigates the interplay between privacy and security in graph learning, highlighting the need for robust and privacy-preserving GNN architectures.
Detecting Data Poisoning in Code Generation LLMs via Black-Box, Vulnerability-Oriented Scanning
Mar 17, 2026Code generation large language models (LLMs) are increasingly integrated into modern software development workflows. Recent work has shown that these models are vulnerable to backdoor and poisoning attacks that induce the generation of insecure code, yet effective defenses remain limited. Existing scanning approaches rely on token-level generation consistency to invert attack targets, which is ineffective for source code where identical semantics can appear in diverse syntactic forms. We present CodeScan, which, to the best of our knowledge, is the first poisoning-scanning framework tailored to code generation models. CodeScan identifies attack targets by analyzing structural similarities across multiple generations conditioned on different clean prompts. It combines iterative divergence analysis with abstract syntax tree (AST)-based normalization to abstract away surface-level variation and unify semantically equivalent code, isolating structures that recur consistently across generations. CodeScan then applies LLM-based vulnerability analysis to determine whether the extracted structures contain security vulnerabilities and flags the model as compromised when such a structure is found. We evaluate CodeScan against four representative attacks under both backdoor and poisoning settings across three real-world vulnerability classes. Experiments on 108 models spanning three architectures and multiple model sizes demonstrate 97%+ detection accuracy with substantially lower false positives than prior methods.
CogniMap3D: Cognitive 3D Mapping and Rapid Retrieval
Jan 13, 2026We present CogniMap3D, a bioinspired framework for dynamic 3D scene understanding and reconstruction that emulates human cognitive processes. Our approach maintains a persistent memory bank of static scenes, enabling efficient spatial knowledge storage and rapid retrieval. CogniMap3D integrates three core capabilities: a multi-stage motion cue framework for identifying dynamic objects, a cognitive mapping system for storing, recalling, and updating static scenes across multiple visits, and a factor graph optimization strategy for refining camera poses. Given an image stream, our model identifies dynamic regions through motion cues with depth and camera pose priors, then matches static elements against its memory bank. When revisiting familiar locations, CogniMap3D retrieves stored scenes, relocates cameras, and updates memory with new observations. Evaluations on video depth estimation, camera pose reconstruction, and 3D mapping tasks demonstrate its state-of-the-art performance, while effectively supporting continuous scene understanding across extended sequences and multiple visits.
Distill Video Datasets into Images
Dec 16, 2025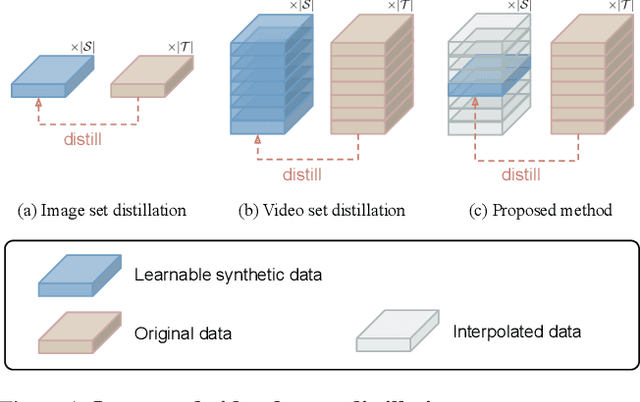
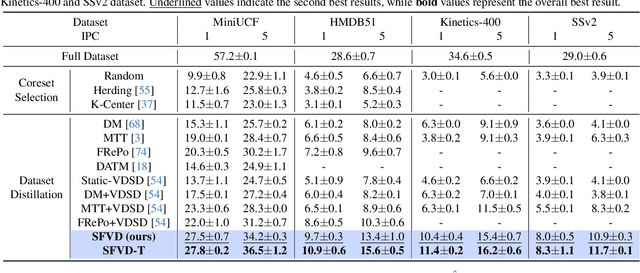
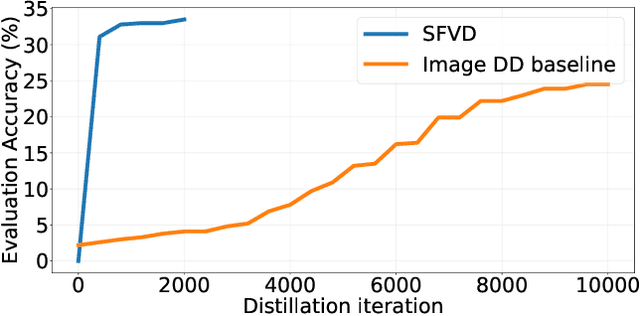
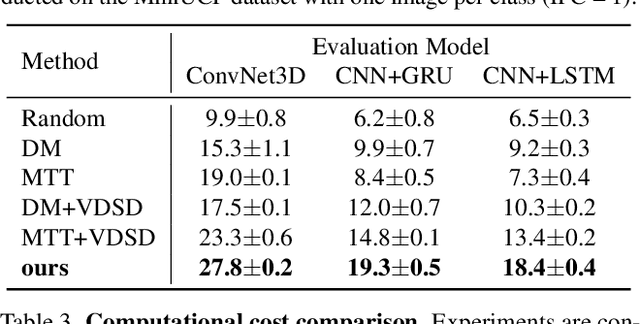
Dataset distillation aims to synthesize compact yet informative datasets that allow models trained on them to achieve performance comparable to training on the full dataset. While this approach has shown promising results for image data, extending dataset distillation methods to video data has proven challenging and often leads to suboptimal performance. In this work, we first identify the core challenge in video set distillation as the substantial increase in learnable parameters introduced by the temporal dimension of video, which complicates optimization and hinders convergence. To address this issue, we observe that a single frame is often sufficient to capture the discriminative semantics of a video. Leveraging this insight, we propose Single-Frame Video set Distillation (SFVD), a framework that distills videos into highly informative frames for each class. Using differentiable interpolation, these frames are transformed into video sequences and matched with the original dataset, while updates are restricted to the frames themselves for improved optimization efficiency. To further incorporate temporal information, the distilled frames are combined with sampled real videos from real videos during the matching process through a channel reshaping layer. Extensive experiments on multiple benchmarks demonstrate that SFVD substantially outperforms prior methods, achieving improvements of up to 5.3% on MiniUCF, thereby offering a more effective solution.
SecureV2X: An Efficient and Privacy-Preserving System for Vehicle-to-Everything (V2X) Applications
Aug 26, 2025Autonomous driving and V2X technologies have developed rapidly in the past decade, leading to improved safety and efficiency in modern transportation. These systems interact with extensive networks of vehicles, roadside infrastructure, and cloud resources to support their machine learning capabilities. However, the widespread use of machine learning in V2X systems raises issues over the privacy of the data involved. This is particularly concerning for smart-transit and driver safety applications which can implicitly reveal user locations or explicitly disclose medical data such as EEG signals. To resolve these issues, we propose SecureV2X, a scalable, multi-agent system for secure neural network inferences deployed between the server and each vehicle. Under this setting, we study two multi-agent V2X applications: secure drowsiness detection, and secure red-light violation detection. Our system achieves strong performance relative to baselines, and scales efficiently to support a large number of secure computation interactions simultaneously. For instance, SecureV2X is $9.4 \times$ faster, requires $143\times$ fewer computational rounds, and involves $16.6\times$ less communication on drowsiness detection compared to other secure systems. Moreover, it achieves a runtime nearly $100\times$ faster than state-of-the-art benchmarks in object detection tasks for red light violation detection.
Rectifying Privacy and Efficacy Measurements in Machine Unlearning: A New Inference Attack Perspective
Jun 16, 2025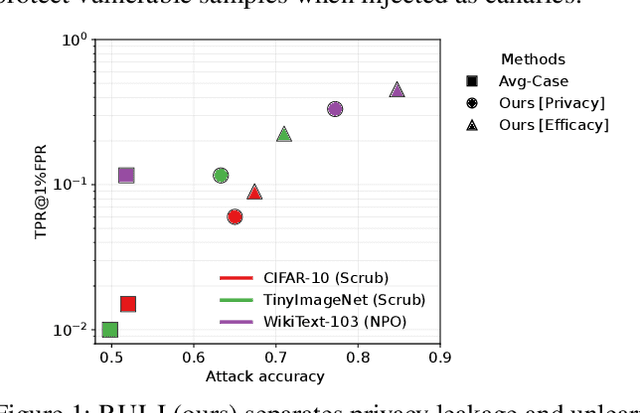

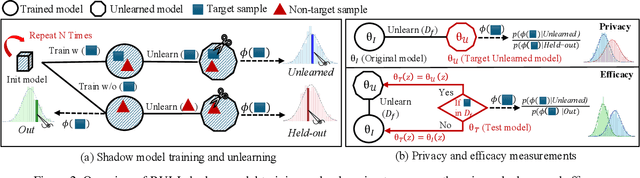
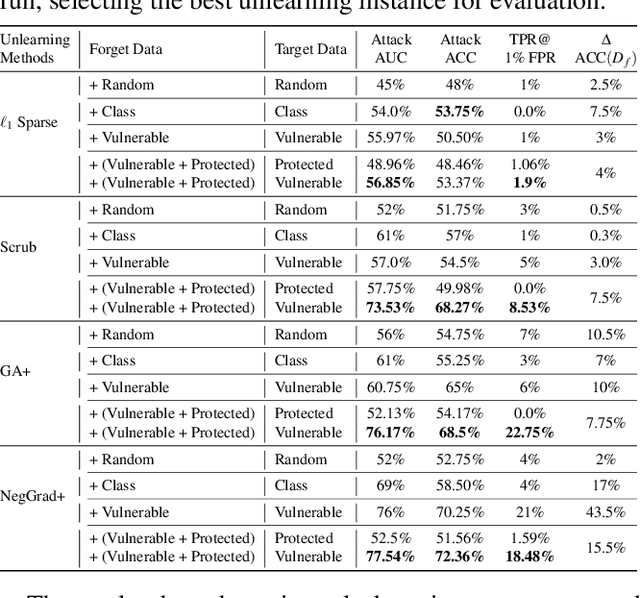
Machine unlearning focuses on efficiently removing specific data from trained models, addressing privacy and compliance concerns with reasonable costs. Although exact unlearning ensures complete data removal equivalent to retraining, it is impractical for large-scale models, leading to growing interest in inexact unlearning methods. However, the lack of formal guarantees in these methods necessitates the need for robust evaluation frameworks to assess their privacy and effectiveness. In this work, we first identify several key pitfalls of the existing unlearning evaluation frameworks, e.g., focusing on average-case evaluation or targeting random samples for evaluation, incomplete comparisons with the retraining baseline. Then, we propose RULI (Rectified Unlearning Evaluation Framework via Likelihood Inference), a novel framework to address critical gaps in the evaluation of inexact unlearning methods. RULI introduces a dual-objective attack to measure both unlearning efficacy and privacy risks at a per-sample granularity. Our findings reveal significant vulnerabilities in state-of-the-art unlearning methods, where RULI achieves higher attack success rates, exposing privacy risks underestimated by existing methods. Built on a game-based foundation and validated through empirical evaluations on both image and text data (spanning tasks from classification to generation), RULI provides a rigorous, scalable, and fine-grained methodology for evaluating unlearning techniques.
Backdoor Attacks on Discrete Graph Diffusion Models
Mar 08, 2025Diffusion models are powerful generative models in continuous data domains such as image and video data. Discrete graph diffusion models (DGDMs) have recently extended them for graph generation, which are crucial in fields like molecule and protein modeling, and obtained the SOTA performance. However, it is risky to deploy DGDMs for safety-critical applications (e.g., drug discovery) without understanding their security vulnerabilities. In this work, we perform the first study on graph diffusion models against backdoor attacks, a severe attack that manipulates both the training and inference/generation phases in graph diffusion models. We first define the threat model, under which we design the attack such that the backdoored graph diffusion model can generate 1) high-quality graphs without backdoor activation, 2) effective, stealthy, and persistent backdoored graphs with backdoor activation, and 3) graphs that are permutation invariant and exchangeable--two core properties in graph generative models. 1) and 2) are validated via empirical evaluations without and with backdoor defenses, while 3) is validated via theoretical results.
GALOT: Generative Active Learning via Optimizable Zero-shot Text-to-image Generation
Dec 18, 2024Active Learning (AL) represents a crucial methodology within machine learning, emphasizing the identification and utilization of the most informative samples for efficient model training. However, a significant challenge of AL is its dependence on the limited labeled data samples and data distribution, resulting in limited performance. To address this limitation, this paper integrates the zero-shot text-to-image (T2I) synthesis and active learning by designing a novel framework that can efficiently train a machine learning (ML) model sorely using the text description. Specifically, we leverage the AL criteria to optimize the text inputs for generating more informative and diverse data samples, annotated by the pseudo-label crafted from text, then served as a synthetic dataset for active learning. This approach reduces the cost of data collection and annotation while increasing the efficiency of model training by providing informative training samples, enabling a novel end-to-end ML task from text description to vision models. Through comprehensive evaluations, our framework demonstrates consistent and significant improvements over traditional AL methods.
Learning Robust and Privacy-Preserving Representations via Information Theory
Dec 15, 2024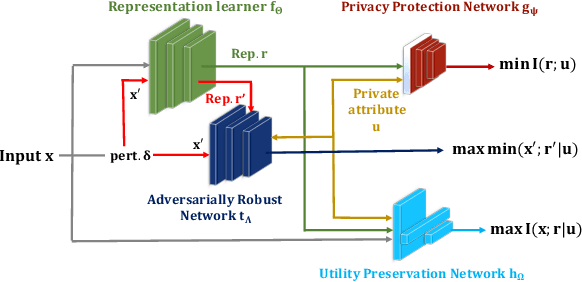
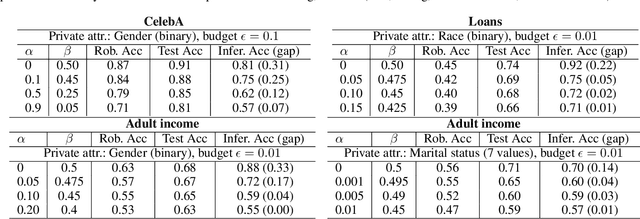
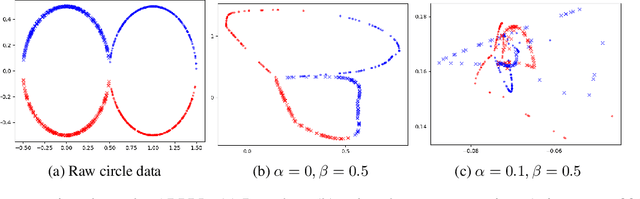
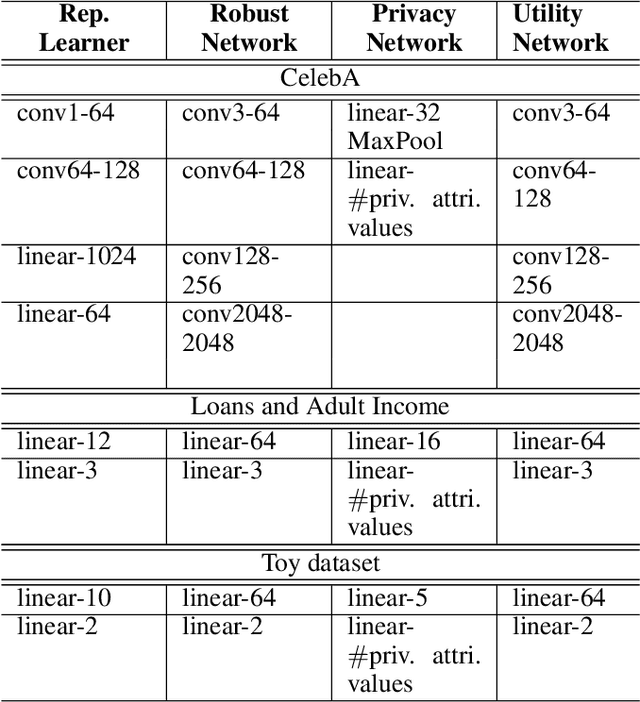
Machine learning models are vulnerable to both security attacks (e.g., adversarial examples) and privacy attacks (e.g., private attribute inference). We take the first step to mitigate both the security and privacy attacks, and maintain task utility as well. Particularly, we propose an information-theoretic framework to achieve the goals through the lens of representation learning, i.e., learning representations that are robust to both adversarial examples and attribute inference adversaries. We also derive novel theoretical results under our framework, e.g., the inherent trade-off between adversarial robustness/utility and attribute privacy, and guaranteed attribute privacy leakage against attribute inference adversaries.
Understanding Data Reconstruction Leakage in Federated Learning from a Theoretical Perspective
Aug 22, 2024Federated learning (FL) is an emerging collaborative learning paradigm that aims to protect data privacy. Unfortunately, recent works show FL algorithms are vulnerable to the serious data reconstruction attacks. However, existing works lack a theoretical foundation on to what extent the devices' data can be reconstructed and the effectiveness of these attacks cannot be compared fairly due to their unstable performance. To address this deficiency, we propose a theoretical framework to understand data reconstruction attacks to FL. Our framework involves bounding the data reconstruction error and an attack's error bound reflects its inherent attack effectiveness. Under the framework, we can theoretically compare the effectiveness of existing attacks. For instance, our results on multiple datasets validate that the iDLG attack inherently outperforms the DLG attack.