 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCertifying Adapters: Enabling and Enhancing the Certification of Classifier Adversarial Robustness
May 25, 2024
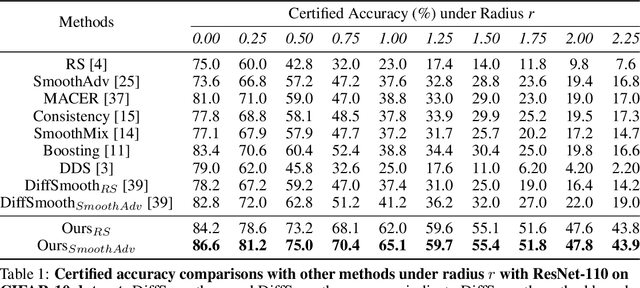
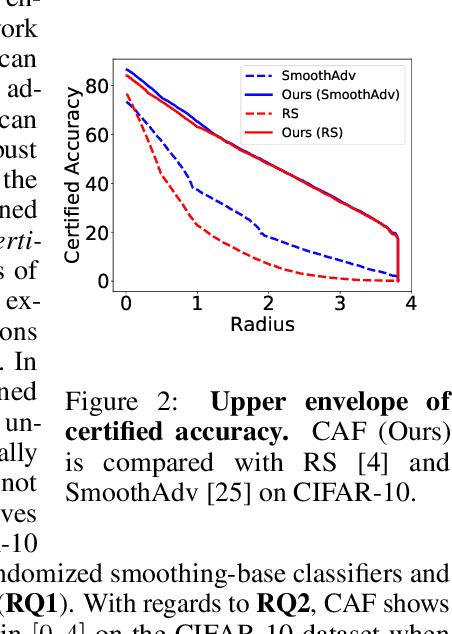

Randomized smoothing has become a leading method for achieving certified robustness in deep classifiers against l_{p}-norm adversarial perturbations. Current approaches for achieving certified robustness, such as data augmentation with Gaussian noise and adversarial training, require expensive training procedures that tune large models for different Gaussian noise levels and thus cannot leverage high-performance pre-trained neural networks. In this work, we introduce a novel certifying adapters framework (CAF) that enables and enhances the certification of classifier adversarial robustness. Our approach makes few assumptions about the underlying training algorithm or feature extractor and is thus broadly applicable to different feature extractor architectures (e.g., convolutional neural networks or vision transformers) and smoothing algorithms. We show that CAF (a) enables certification in uncertified models pre-trained on clean datasets and (b) substantially improves the performance of certified classifiers via randomized smoothing and SmoothAdv at multiple radii in CIFAR-10 and ImageNet. We demonstrate that CAF achieves improved certified accuracies when compared to methods based on random or denoised smoothing, and that CAF is insensitive to certifying adapter hyperparameters. Finally, we show that an ensemble of adapters enables a single pre-trained feature extractor to defend against a range of noise perturbation scales.
Distilling Adversarial Robustness Using Heterogeneous Teachers
Feb 23, 2024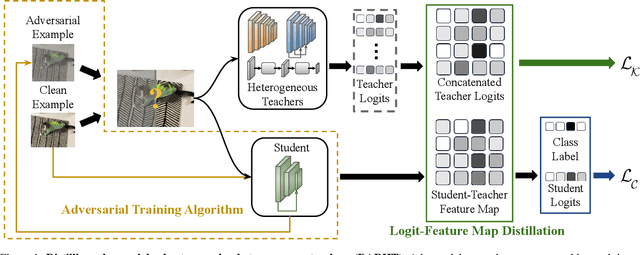
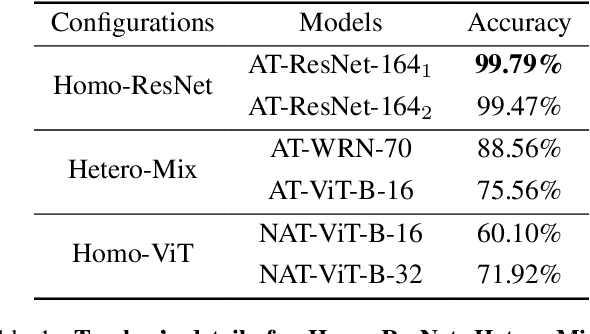
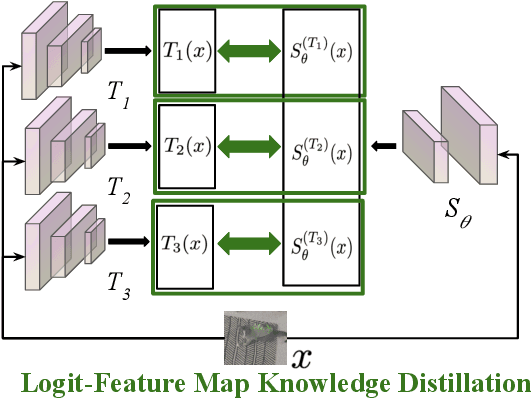
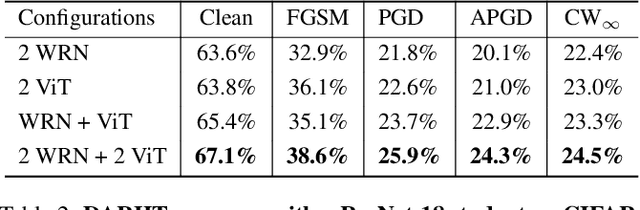
Achieving resiliency against adversarial attacks is necessary prior to deploying neural network classifiers in domains where misclassification incurs substantial costs, e.g., self-driving cars or medical imaging. Recent work has demonstrated that robustness can be transferred from an adversarially trained teacher to a student model using knowledge distillation. However, current methods perform distillation using a single adversarial and vanilla teacher and consider homogeneous architectures (i.e., residual networks) that are susceptible to misclassify examples from similar adversarial subspaces. In this work, we develop a defense framework against adversarial attacks by distilling adversarial robustness using heterogeneous teachers (DARHT). In DARHT, the student model explicitly represents teacher logits in a student-teacher feature map and leverages multiple teachers that exhibit low adversarial example transferability (i.e., exhibit high performance on dissimilar adversarial examples). Experiments on classification tasks in both white-box and black-box scenarios demonstrate that DARHT achieves state-of-the-art clean and robust accuracies when compared to competing adversarial training and distillation methods in the CIFAR-10, CIFAR-100, and Tiny ImageNet datasets. Comparisons with homogeneous and heterogeneous teacher sets suggest that leveraging teachers with low adversarial example transferability increases student model robustness.
Improving Opioid Use Disorder Risk Modelling through Behavioral and Genetic Feature Integration
Sep 19, 2023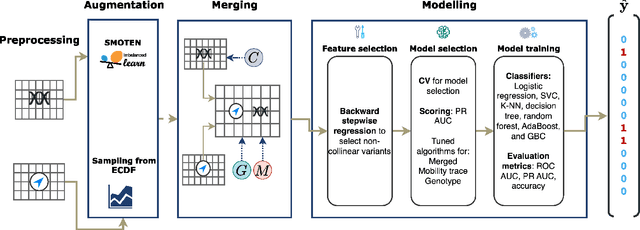
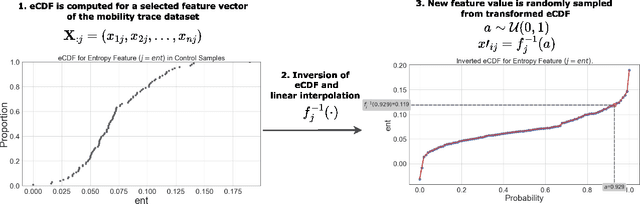
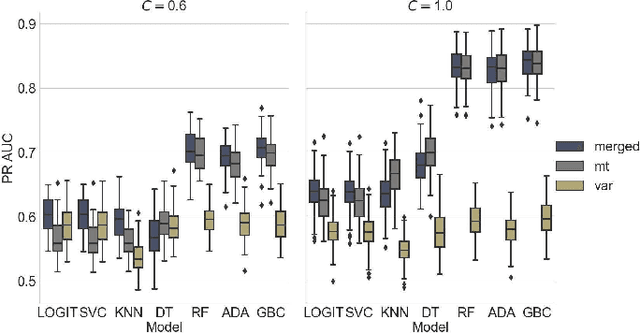
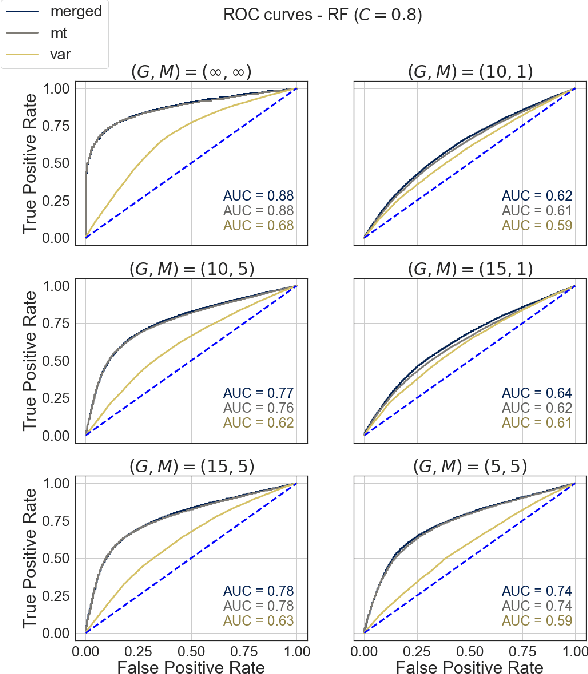
Opioids are an effective analgesic for acute and chronic pain, but also carry a considerable risk of addiction leading to millions of opioid use disorder (OUD) cases and tens of thousands of premature deaths in the United States yearly. Estimating OUD risk prior to prescription could improve the efficacy of treatment regimens, monitoring programs, and intervention strategies, but risk estimation is typically based on self-reported data or questionnaires. We develop an experimental design and computational methods that combines genetic variants associated with OUD with behavioral features extracted from GPS and Wi-Fi spatiotemporal coordinates to assess OUD risk. Since both OUD mobility and genetic data do not exist for the same cohort, we develop algorithms to (1) generate mobility features from empirical distributions and (2) synthesize mobility and genetic samples assuming a level of comorbidity and relative risks. We show that integrating genetic and mobility modalities improves risk modelling using classification accuracy, area under the precision-recall and receiver operator characteristic curves, and $F_1$ score. Interpreting the fitted models suggests that mobility features have more influence on OUD risk, although the genetic contribution was significant, particularly in linear models. While there exists concerns with respect to privacy, security, bias, and generalizability that must be evaluated in clinical trials before being implemented in practice, our framework provides preliminary evidence that behavioral and genetic features may improve OUD risk estimation to assist with personalized clinical decision-making.
GBSD: Generative Bokeh with Stage Diffusion
Jun 14, 2023The bokeh effect is an artistic technique that blurs out-of-focus areas in a photograph and has gained interest due to recent developments in text-to-image synthesis and the ubiquity of smart-phone cameras and photo-sharing apps. Prior work on rendering bokeh effects have focused on post hoc image manipulation to produce similar blurring effects in existing photographs using classical computer graphics or neural rendering techniques, but have either depth discontinuity artifacts or are restricted to reproducing bokeh effects that are present in the training data. More recent diffusion based models can synthesize images with an artistic style, but either require the generation of high-dimensional masks, expensive fine-tuning, or affect global image characteristics. In this paper, we present GBSD, the first generative text-to-image model that synthesizes photorealistic images with a bokeh style. Motivated by how image synthesis occurs progressively in diffusion models, our approach combines latent diffusion models with a 2-stage conditioning algorithm to render bokeh effects on semantically defined objects. Since we can focus the effect on objects, this semantic bokeh effect is more versatile than classical rendering techniques. We evaluate GBSD both quantitatively and qualitatively and demonstrate its ability to be applied in both text-to-image and image-to-image settings.
Smooth and Stepwise Self-Distillation for Object Detection
Mar 09, 2023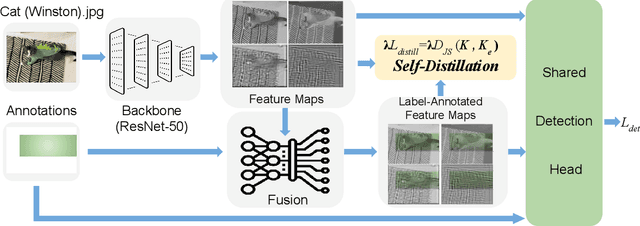
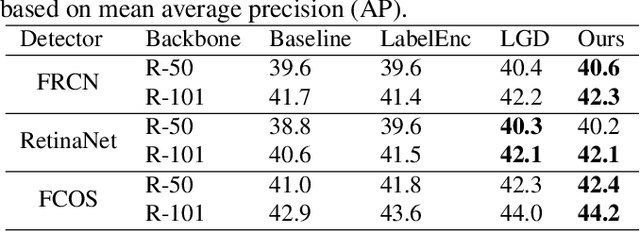
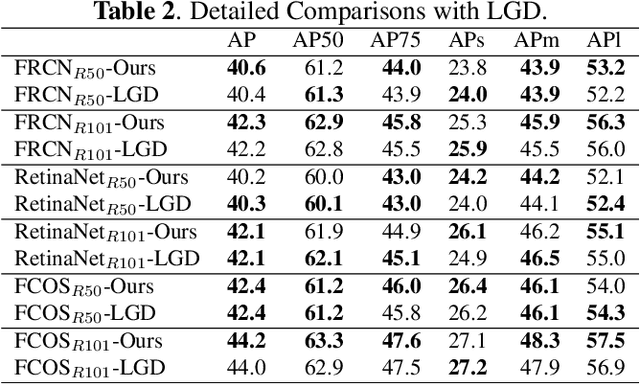
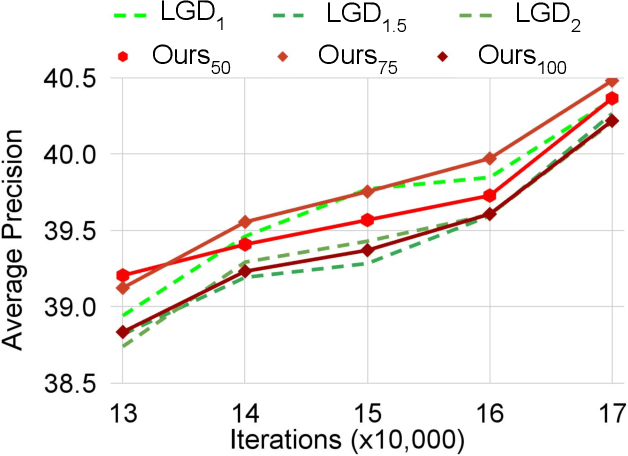
Distilling the structured information captured in feature maps has contributed to improved results for object detection tasks, but requires careful selection of baseline architectures and substantial pre-training. Self-distillation addresses these limitations and has recently achieved state-of-the-art performance for object detection despite making several simplifying architectural assumptions. Building on this work, we propose Smooth and Stepwise Self-Distillation (SSSD) for object detection. Our SSSD architecture forms an implicit teacher from object labels and a feature pyramid network backbone to distill label-annotated feature maps using Jensen-Shannon distance, which is smoother than distillation losses used in prior work. We additionally add a distillation coefficient that is adaptively configured based on the learning rate. We extensively benchmark SSSD against a baseline and two state-of-the-art object detector architectures on the COCO dataset by varying the coefficients and backbone and detector networks. We demonstrate that SSSD achieves higher average precision in most experimental settings, is robust to a wide range of coefficients, and benefits from our stepwise distillation procedure.
Bayesian Reconstruction and Differential Testing of Excised mRNA
Nov 14, 2022Characterizing the differential excision of mRNA is critical for understanding the functional complexity of a cell or tissue, from normal developmental processes to disease pathogenesis. Most transcript reconstruction methods infer full-length transcripts from high-throughput sequencing data. However, this is a challenging task due to incomplete annotations and the differential expression of transcripts across cell-types, tissues, and experimental conditions. Several recent methods circumvent these difficulties by considering local splicing events, but these methods lose transcript-level splicing information and may conflate transcripts. We develop the first probabilistic model that reconciles the transcript and local splicing perspectives. First, we formalize the sequence of mRNA excisions (SME) reconstruction problem, which aims to assemble variable-length sequences of mRNA excisions from RNA-sequencing data. We then present a novel hierarchical Bayesian admixture model for the Reconstruction of Excised mRNA (BREM). BREM interpolates between local splicing events and full-length transcripts and thus focuses only on SMEs that have high posterior probability. We develop posterior inference algorithms based on Gibbs sampling and local search of independent sets and characterize differential SME usage using generalized linear models based on converged BREM model parameters. We show that BREM achieves higher F1 score for reconstruction tasks and improved accuracy and sensitivity in differential splicing when compared with four state-of-the-art transcript and local splicing methods on simulated data. Lastly, we evaluate BREM on both bulk and scRNA sequencing data based on transcript reconstruction, novelty of transcripts produced, model sensitivity to hyperparameters, and a functional analysis of differentially expressed SMEs, demonstrating that BREM captures relevant biological signal.
Auto-Encoding Goodness of Fit
Oct 12, 2022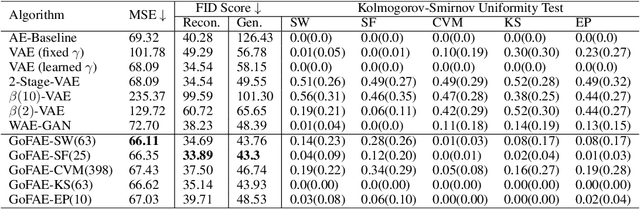
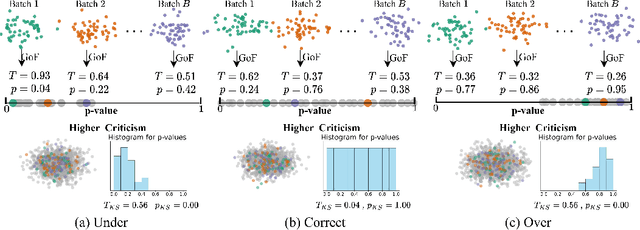
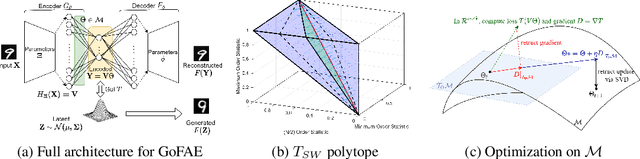
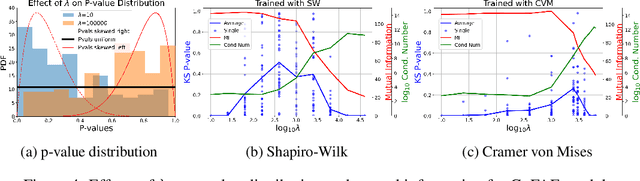
For generative autoencoders to learn a meaningful latent representation for data generation, a careful balance must be achieved between reconstruction error and how close the distribution in the latent space is to the prior. However, this balance is challenging to achieve due to a lack of criteria that work both at the mini-batch (local) and aggregated posterior (global) level. Goodness of fit (GoF) hypothesis tests provide a measure of statistical indistinguishability between the latent distribution and a target distribution class. In this work, we develop the Goodness of Fit Autoencoder (GoFAE), which incorporates hypothesis tests at two levels. At the mini-batch level, it uses GoF test statistics as regularization objectives. At a more global level, it selects a regularization coefficient based on higher criticism, i.e., a test on the uniformity of the local GoF p-values. We justify the use of GoF tests by providing a relaxed $L_2$-Wasserstein bound on the distance between the latent distribution and target prior. We propose to use GoF tests and prove that optimization based on these tests can be done with stochastic gradient (SGD) descent on a compact Riemannian manifold. Empirically, we show that our higher criticism parameter selection procedure balances reconstruction and generation using mutual information and uniformity of p-values respectively. Finally, we show that GoFAE achieves comparable FID scores and mean squared errors with competing deep generative models while retaining statistical indistinguishability from Gaussian in the latent space based on a variety of hypothesis tests.
Interpretable Fake News Detection with Topic and Deep Variational Models
Sep 04, 2022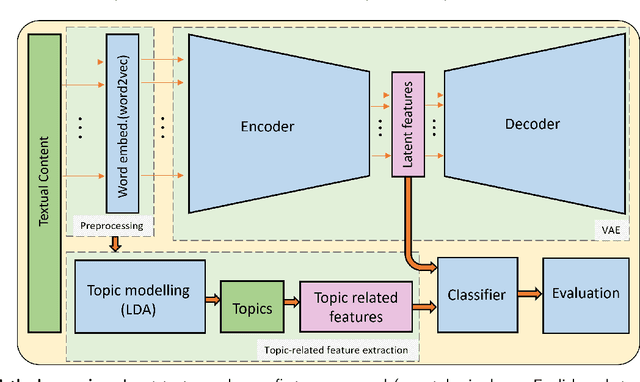
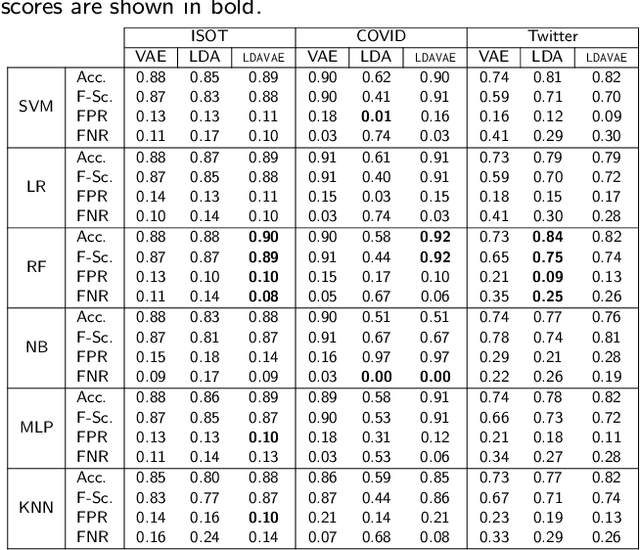
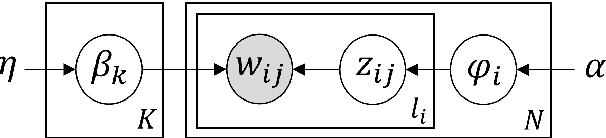
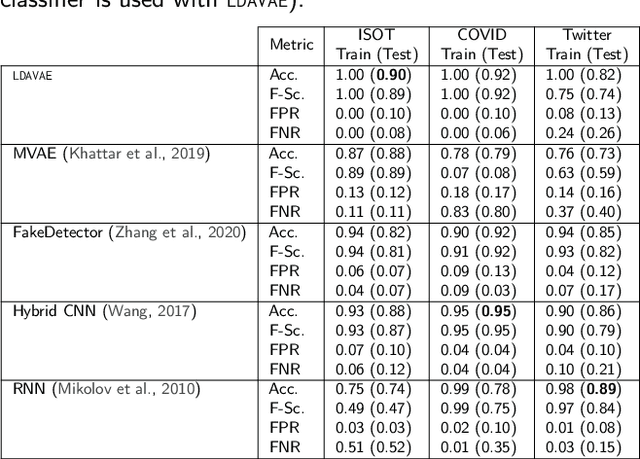
The growing societal dependence on social media and user generated content for news and information has increased the influence of unreliable sources and fake content, which muddles public discourse and lessens trust in the media. Validating the credibility of such information is a difficult task that is susceptible to confirmation bias, leading to the development of algorithmic techniques to distinguish between fake and real news. However, most existing methods are challenging to interpret, making it difficult to establish trust in predictions, and make assumptions that are unrealistic in many real-world scenarios, e.g., the availability of audiovisual features or provenance. In this work, we focus on fake news detection of textual content using interpretable features and methods. In particular, we have developed a deep probabilistic model that integrates a dense representation of textual news using a variational autoencoder and bi-directional Long Short-Term Memory (LSTM) networks with semantic topic-related features inferred from a Bayesian admixture model. Extensive experimental studies with 3 real-world datasets demonstrate that our model achieves comparable performance to state-of-the-art competing models while facilitating model interpretability from the learned topics. Finally, we have conducted model ablation studies to justify the effectiveness and accuracy of integrating neural embeddings and topic features both quantitatively by evaluating performance and qualitatively through separability in lower dimensional embeddings.