 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoute to Reason: Adaptive Routing for LLM and Reasoning Strategy Selection
May 26, 2025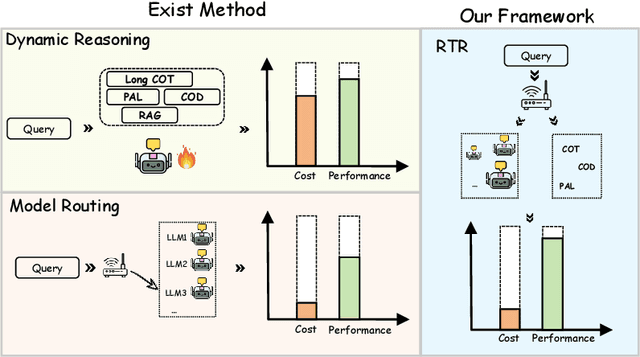
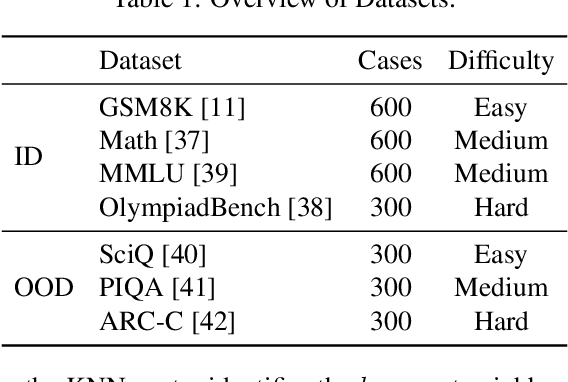
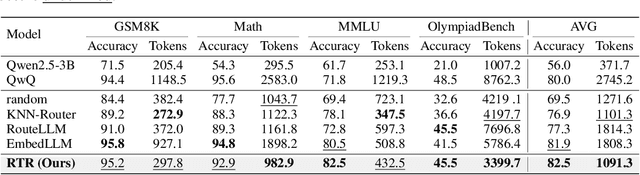
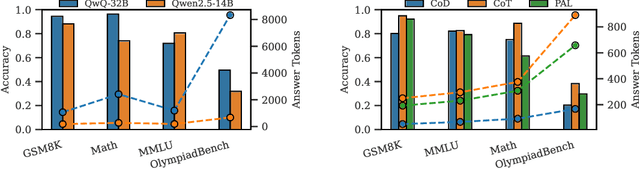
The inherent capabilities of a language model (LM) and the reasoning strategies it employs jointly determine its performance in reasoning tasks. While test-time scaling is regarded as an effective approach to tackling complex reasoning tasks, it incurs substantial computational costs and often leads to "overthinking", where models become trapped in "thought pitfalls". To address this challenge, we propose Route-To-Reason (RTR), a novel unified routing framework that dynamically allocates both LMs and reasoning strategies according to task difficulty under budget constraints. RTR learns compressed representations of both expert models and reasoning strategies, enabling their joint and adaptive selection at inference time. This method is low-cost, highly flexible, and can be seamlessly extended to arbitrary black-box or white-box models and strategies, achieving true plug-and-play functionality. Extensive experiments across seven open source models and four reasoning strategies demonstrate that RTR achieves an optimal trade-off between accuracy and computational efficiency among all baselines, achieving higher accuracy than the best single model while reducing token usage by over 60%.
Gradient-Free Classifier Guidance for Diffusion Model Sampling
Nov 23, 2024



Image generation using diffusion models have demonstrated outstanding learning capabilities, effectively capturing the full distribution of the training dataset. They are known to generate wide variations in sampled images, albeit with a trade-off in image fidelity. Guided sampling methods, such as classifier guidance (CG) and classifier-free guidance (CFG), focus sampling in well-learned high-probability regions to generate images of high fidelity, but each has its limitations. CG is computationally expensive due to the use of back-propagation for classifier gradient descent, while CFG, being gradient-free, is more efficient but compromises class label alignment compared to CG. In this work, we propose an efficient guidance method that fully utilizes a pre-trained classifier without using gradient descent. By using the classifier solely in inference mode, a time-adaptive reference class label and corresponding guidance scale are determined at each time step for guided sampling. Experiments on both class-conditioned and text-to-image generation diffusion models demonstrate that the proposed Gradient-free Classifier Guidance (GFCG) method consistently improves class prediction accuracy. We also show GFCG to be complementary to other guided sampling methods like CFG. When combined with the state-of-the-art Autoguidance (ATG), without additional computational overhead, it enhances image fidelity while preserving diversity. For ImageNet 512$\times$512, we achieve a record $\text{FD}_{\text{DINOv2}}$ of 23.09, while simultaneously attaining a higher classification Precision (94.3%) compared to ATG (90.2%)
Retrieving Conditions from Reference Images for Diffusion Models
Dec 05, 2023

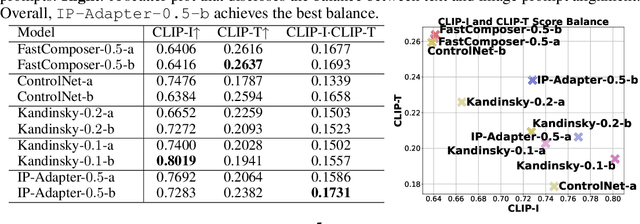

Recent diffusion-based subject driven generative methods have enabled image generations with good fidelity for specific objects or human portraits. However, to achieve better versatility for applications, we argue that not only improved datasets and evaluations are desired, but also more careful methods to retrieve only relevant information from conditional images are anticipated. To this end, we propose an anime figures dataset RetriBooru-V1, with enhanced identity and clothing labels. We state new tasks enabled by this dataset, and introduce a new diversity metric to measure success in completing these tasks, quantifying the flexibility of image generations. We establish an RAG-inspired baseline method, designed to retrieve precise conditional information from reference images. Then, we compare with current methods on existing task to demonstrate the capability of the proposed method. Finally, we provide baseline experiment results on new tasks, and conduct ablation studies on the possible structural choices.
Effective Real Image Editing with Accelerated Iterative Diffusion Inversion
Sep 10, 2023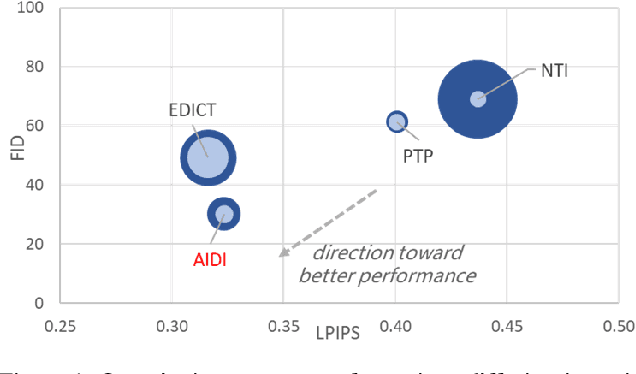
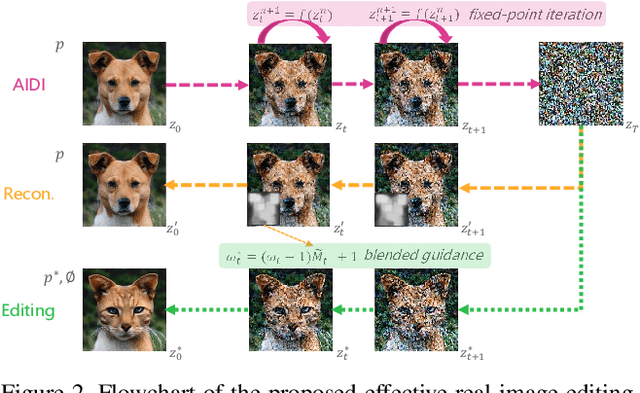


Despite all recent progress, it is still challenging to edit and manipulate natural images with modern generative models. When using Generative Adversarial Network (GAN), one major hurdle is in the inversion process mapping a real image to its corresponding noise vector in the latent space, since its necessary to be able to reconstruct an image to edit its contents. Likewise for Denoising Diffusion Implicit Models (DDIM), the linearization assumption in each inversion step makes the whole deterministic inversion process unreliable. Existing approaches that have tackled the problem of inversion stability often incur in significant trade-offs in computational efficiency. In this work we propose an Accelerated Iterative Diffusion Inversion method, dubbed AIDI, that significantly improves reconstruction accuracy with minimal additional overhead in space and time complexity. By using a novel blended guidance technique, we show that effective results can be obtained on a large range of image editing tasks without large classifier-free guidance in inversion. Furthermore, when compared with other diffusion inversion based works, our proposed process is shown to be more robust for fast image editing in the 10 and 20 diffusion steps' regimes.
HollowNeRF: Pruning Hashgrid-Based NeRFs with Trainable Collision Mitigation
Aug 19, 2023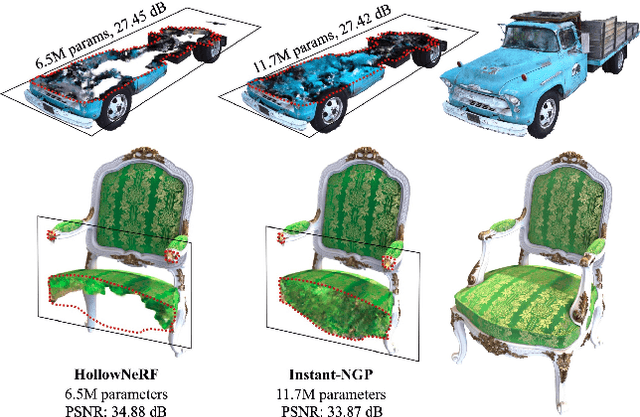
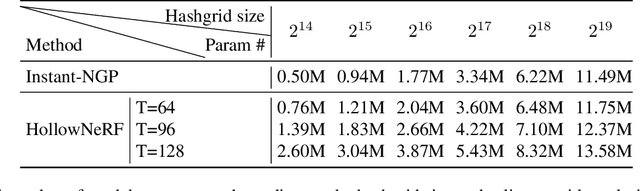
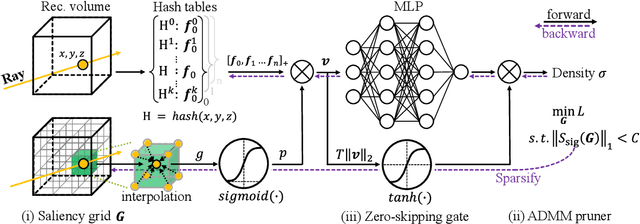
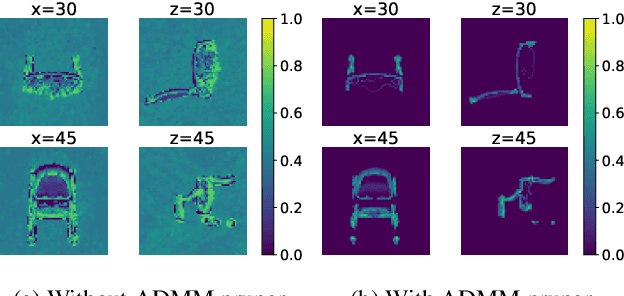
Neural radiance fields (NeRF) have garnered significant attention, with recent works such as Instant-NGP accelerating NeRF training and evaluation through a combination of hashgrid-based positional encoding and neural networks. However, effectively leveraging the spatial sparsity of 3D scenes remains a challenge. To cull away unnecessary regions of the feature grid, existing solutions rely on prior knowledge of object shape or periodically estimate object shape during training by repeated model evaluations, which are costly and wasteful. To address this issue, we propose HollowNeRF, a novel compression solution for hashgrid-based NeRF which automatically sparsifies the feature grid during the training phase. Instead of directly compressing dense features, HollowNeRF trains a coarse 3D saliency mask that guides efficient feature pruning, and employs an alternating direction method of multipliers (ADMM) pruner to sparsify the 3D saliency mask during training. By exploiting the sparsity in the 3D scene to redistribute hash collisions, HollowNeRF improves rendering quality while using a fraction of the parameters of comparable state-of-the-art solutions, leading to a better cost-accuracy trade-off. Our method delivers comparable rendering quality to Instant-NGP, while utilizing just 31% of the parameters. In addition, our solution can achieve a PSNR accuracy gain of up to 1dB using only 56% of the parameters.
GBSD: Generative Bokeh with Stage Diffusion
Jun 14, 2023The bokeh effect is an artistic technique that blurs out-of-focus areas in a photograph and has gained interest due to recent developments in text-to-image synthesis and the ubiquity of smart-phone cameras and photo-sharing apps. Prior work on rendering bokeh effects have focused on post hoc image manipulation to produce similar blurring effects in existing photographs using classical computer graphics or neural rendering techniques, but have either depth discontinuity artifacts or are restricted to reproducing bokeh effects that are present in the training data. More recent diffusion based models can synthesize images with an artistic style, but either require the generation of high-dimensional masks, expensive fine-tuning, or affect global image characteristics. In this paper, we present GBSD, the first generative text-to-image model that synthesizes photorealistic images with a bokeh style. Motivated by how image synthesis occurs progressively in diffusion models, our approach combines latent diffusion models with a 2-stage conditioning algorithm to render bokeh effects on semantically defined objects. Since we can focus the effect on objects, this semantic bokeh effect is more versatile than classical rendering techniques. We evaluate GBSD both quantitatively and qualitatively and demonstrate its ability to be applied in both text-to-image and image-to-image settings.
Fast Diffusion Probabilistic Model Sampling through the lens of Backward Error Analysis
Apr 22, 2023



Denoising diffusion probabilistic models (DDPMs) are a class of powerful generative models. The past few years have witnessed the great success of DDPMs in generating high-fidelity samples. A significant limitation of the DDPMs is the slow sampling procedure. DDPMs generally need hundreds or thousands of sequential function evaluations (steps) of neural networks to generate a sample. This paper aims to develop a fast sampling method for DDPMs requiring much fewer steps while retaining high sample quality. The inference process of DDPMs approximates solving the corresponding diffusion ordinary differential equations (diffusion ODEs) in the continuous limit. This work analyzes how the backward error affects the diffusion ODEs and the sample quality in DDPMs. We propose fast sampling through the \textbf{Restricting Backward Error schedule (RBE schedule)} based on dynamically moderating the long-time backward error. Our method accelerates DDPMs without any further training. Our experiments show that sampling with an RBE schedule generates high-quality samples within only 8 to 20 function evaluations on various benchmark datasets. We achieved 12.01 FID in 8 function evaluations on the ImageNet $128\times128$, and a $20\times$ speedup compared with previous baseline samplers.
Raising The Limit Of Image Rescaling Using Auxiliary Encoding
Mar 12, 2023Normalizing flow models using invertible neural networks (INN) have been widely investigated for successful generative image super-resolution (SR) by learning the transformation between the normal distribution of latent variable $z$ and the conditional distribution of high-resolution (HR) images gave a low-resolution (LR) input. Recently, image rescaling models like IRN utilize the bidirectional nature of INN to push the performance limit of image upscaling by optimizing the downscaling and upscaling steps jointly. While the random sampling of latent variable $z$ is useful in generating diverse photo-realistic images, it is not desirable for image rescaling when accurate restoration of the HR image is more important. Hence, in places of random sampling of $z$, we propose auxiliary encoding modules to further push the limit of image rescaling performance. Two options to store the encoded latent variables in downscaled LR images, both readily supported in existing image file format, are proposed. One is saved as the alpha-channel, the other is saved as meta-data in the image header, and the corresponding modules are denoted as suffixes -A and -M respectively. Optimal network architectural changes are investigated for both options to demonstrate their effectiveness in raising the rescaling performance limit on different baseline models including IRN and DLV-IRN.
Smooth and Stepwise Self-Distillation for Object Detection
Mar 09, 2023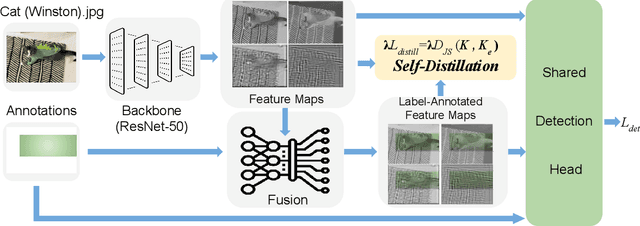
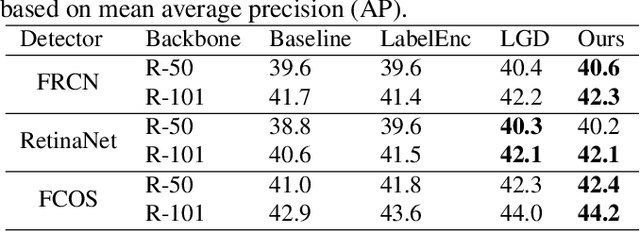
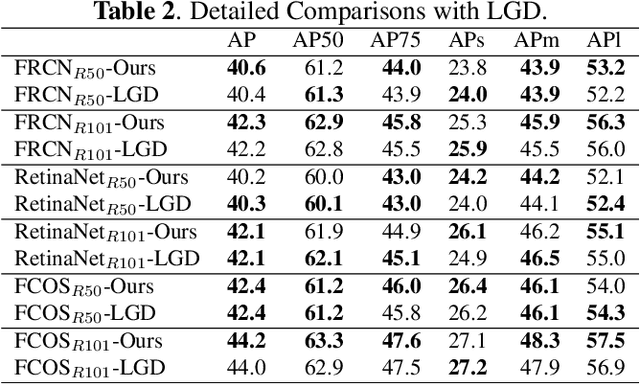
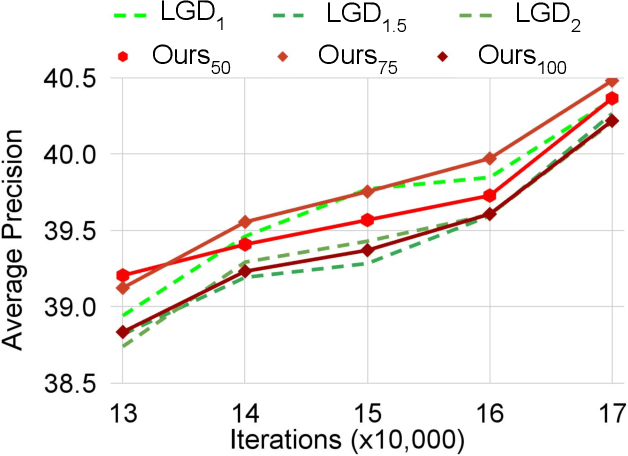
Distilling the structured information captured in feature maps has contributed to improved results for object detection tasks, but requires careful selection of baseline architectures and substantial pre-training. Self-distillation addresses these limitations and has recently achieved state-of-the-art performance for object detection despite making several simplifying architectural assumptions. Building on this work, we propose Smooth and Stepwise Self-Distillation (SSSD) for object detection. Our SSSD architecture forms an implicit teacher from object labels and a feature pyramid network backbone to distill label-annotated feature maps using Jensen-Shannon distance, which is smoother than distillation losses used in prior work. We additionally add a distillation coefficient that is adaptively configured based on the learning rate. We extensively benchmark SSSD against a baseline and two state-of-the-art object detector architectures on the COCO dataset by varying the coefficients and backbone and detector networks. We demonstrate that SSSD achieves higher average precision in most experimental settings, is robust to a wide range of coefficients, and benefits from our stepwise distillation procedure.
Arbitrary Style Guidance for Enhanced Diffusion-Based Text-to-Image Generation
Nov 14, 2022
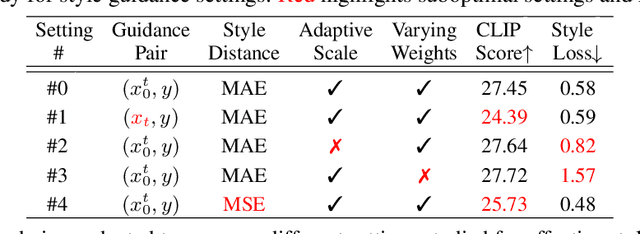

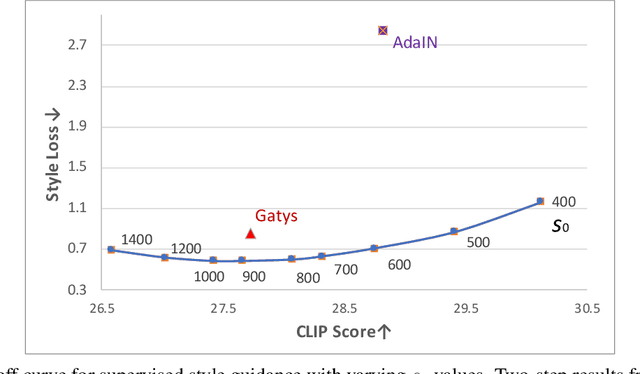
Diffusion-based text-to-image generation models like GLIDE and DALLE-2 have gained wide success recently for their superior performance in turning complex text inputs into images of high quality and wide diversity. In particular, they are proven to be very powerful in creating graphic arts of various formats and styles. Although current models supported specifying style formats like oil painting or pencil drawing, fine-grained style features like color distributions and brush strokes are hard to specify as they are randomly picked from a conditional distribution based on the given text input. Here we propose a novel style guidance method to support generating images using arbitrary style guided by a reference image. The generation method does not require a separate style transfer model to generate desired styles while maintaining image quality in generated content as controlled by the text input. Additionally, the guidance method can be applied without a style reference, denoted as self style guidance, to generate images of more diverse styles. Comprehensive experiments prove that the proposed method remains robust and effective in a wide range of conditions, including diverse graphic art forms, image content types and diffusion models.