 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJUDO: A Juxtaposed Domain-Oriented Multimodal Reasoner for Industrial Anomaly QA
May 19, 2026Industrial anomaly detection has been significantly advanced by Large Multimodal Models (LMMs), enabling diverse human instructions beyond detection, particularly through visually grounded reasoning for better image understanding. However, LMMs lack domain-specific knowledge, which limits their ability to generate accurate responses in complex industrial scenarios. In this work, we present JUDO, Juxtaposed Domain-Oriented Multimodal Reasoner, a framework that efficiently incorporates domain knowledge and context in visual and textual reasoning. Through visual reasoning, our model segments the defect region by juxtaposing query images with normal images as visual domain context, enabling a fine-grained visual comparative inspection. Furthermore, we inject domain knowledge through supervised fine-tuning (SFT) to enhance context understanding and subsequently guide domain reasoning through reinforcement learning (GRPO) with tailored rewards, opting for a domain-oriented reasoning process. Experimental results demonstrate that JUDO achieves superior performance on the MMAD benchmark, surpassing models such as Qwen2.5-VL-7B and GPT-4o. These results highlight the importance of enhancing domain knowledge and context for effective reasoning in anomaly understanding.
Gradient-Free Classifier Guidance for Diffusion Model Sampling
Nov 23, 2024



Image generation using diffusion models have demonstrated outstanding learning capabilities, effectively capturing the full distribution of the training dataset. They are known to generate wide variations in sampled images, albeit with a trade-off in image fidelity. Guided sampling methods, such as classifier guidance (CG) and classifier-free guidance (CFG), focus sampling in well-learned high-probability regions to generate images of high fidelity, but each has its limitations. CG is computationally expensive due to the use of back-propagation for classifier gradient descent, while CFG, being gradient-free, is more efficient but compromises class label alignment compared to CG. In this work, we propose an efficient guidance method that fully utilizes a pre-trained classifier without using gradient descent. By using the classifier solely in inference mode, a time-adaptive reference class label and corresponding guidance scale are determined at each time step for guided sampling. Experiments on both class-conditioned and text-to-image generation diffusion models demonstrate that the proposed Gradient-free Classifier Guidance (GFCG) method consistently improves class prediction accuracy. We also show GFCG to be complementary to other guided sampling methods like CFG. When combined with the state-of-the-art Autoguidance (ATG), without additional computational overhead, it enhances image fidelity while preserving diversity. For ImageNet 512$\times$512, we achieve a record $\text{FD}_{\text{DINOv2}}$ of 23.09, while simultaneously attaining a higher classification Precision (94.3%) compared to ATG (90.2%)
3D Reconstruction of Interacting Multi-Person in Clothing from a Single Image
Jan 12, 2024This paper introduces a novel pipeline to reconstruct the geometry of interacting multi-person in clothing on a globally coherent scene space from a single image. The main challenge arises from the occlusion: a part of a human body is not visible from a single view due to the occlusion by others or the self, which introduces missing geometry and physical implausibility (e.g., penetration). We overcome this challenge by utilizing two human priors for complete 3D geometry and surface contacts. For the geometry prior, an encoder learns to regress the image of a person with missing body parts to the latent vectors; a decoder decodes these vectors to produce 3D features of the associated geometry; and an implicit network combines these features with a surface normal map to reconstruct a complete and detailed 3D humans. For the contact prior, we develop an image-space contact detector that outputs a probability distribution of surface contacts between people in 3D. We use these priors to globally refine the body poses, enabling the penetration-free and accurate reconstruction of interacting multi-person in clothing on the scene space. The results demonstrate that our method is complete, globally coherent, and physically plausible compared to existing methods.
TERRA: Beam Management for Outdoor mm-Wave Networks
Jan 10, 2023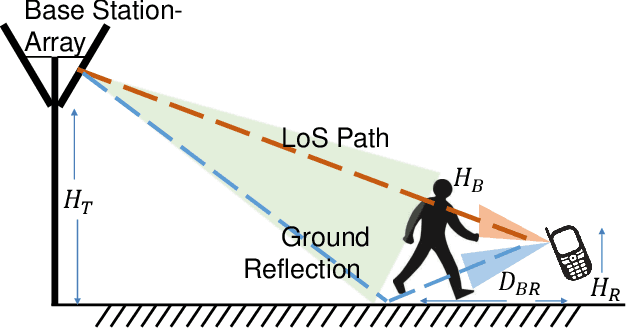
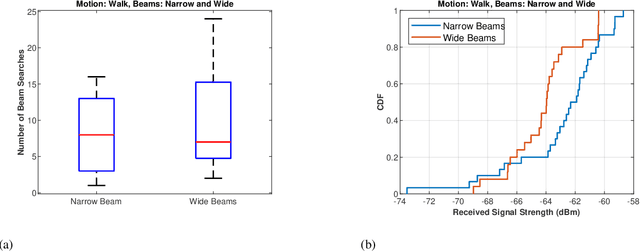
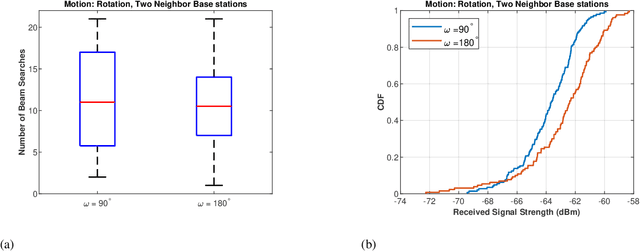
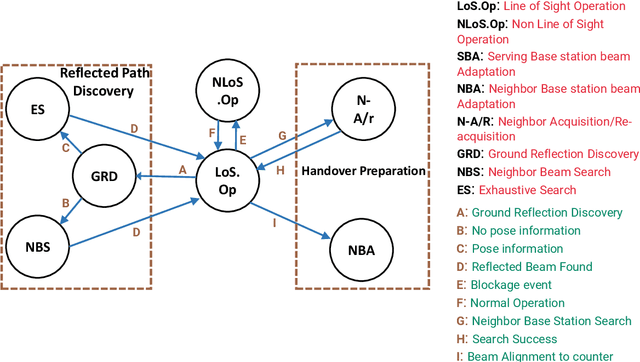
mm-Wave communication systems use narrow directional beams due to the spectrum's characteristic nature: high path and penetration losses. The mobile and the base station primarily employ beams in line of sight (LoS) direction and when needed in non-line of sight direction. Beam management protocol adapts the base station and mobile side beam direction during user mobility and to sustain the link during blockages. To avoid outage in transient pedestrian blockage of the LoS path, the mobile uses reflected or NLoS path available in indoor environments. Reflected paths can sustain time synchronization and maintain connectivity during temporary blockages. In outdoor environments, such reflections may not be available and prior work relied on dense base station deployment or co-ordinated multi-point access to address outage problem. Instead of dense and hence cost-intensive network deployments, we found experimentally that the mobile can capitalize on ground reflection. We developed TERRA protocol to effectively handle mobile side beam direction during transient blockage events. TERRA avoids outage during pedestrian blockages 84.5 $\%$ of the time in outdoor environments on concrete and gravel surfaces. TERRA also enables the mobile to perform a soft handover to a reserve neighbor base station in the event of a permanent blockage, without requiring any side information, unlike the existing works. Evaluations show that TERRA maintains received signal strength close to the optimal solution while keeping track of the neighbor base station.
Enhanced Meta Reinforcement Learning using Demonstrations in Sparse Reward Environments
Sep 26, 2022
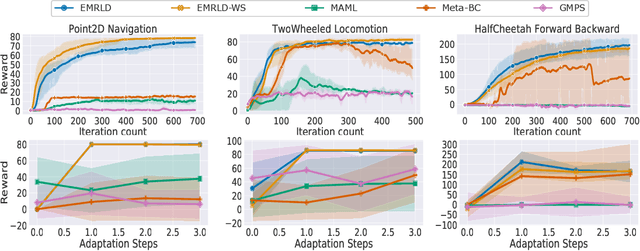
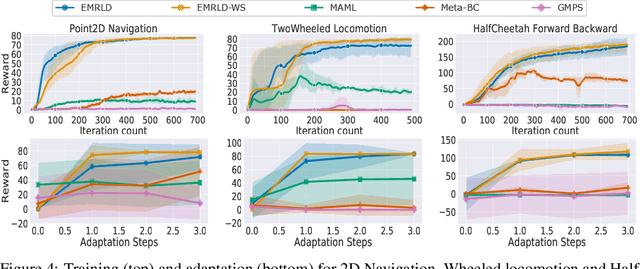
Meta reinforcement learning (Meta-RL) is an approach wherein the experience gained from solving a variety of tasks is distilled into a meta-policy. The meta-policy, when adapted over only a small (or just a single) number of steps, is able to perform near-optimally on a new, related task. However, a major challenge to adopting this approach to solve real-world problems is that they are often associated with sparse reward functions that only indicate whether a task is completed partially or fully. We consider the situation where some data, possibly generated by a sub-optimal agent, is available for each task. We then develop a class of algorithms entitled Enhanced Meta-RL using Demonstrations (EMRLD) that exploit this information even if sub-optimal to obtain guidance during training. We show how EMRLD jointly utilizes RL and supervised learning over the offline data to generate a meta-policy that demonstrates monotone performance improvements. We also develop a warm started variant called EMRLD-WS that is particularly efficient for sub-optimal demonstration data. Finally, we show that our EMRLD algorithms significantly outperform existing approaches in a variety of sparse reward environments, including that of a mobile robot.
A Generalized Supervised Contrastive Learning Framework
Jun 01, 2022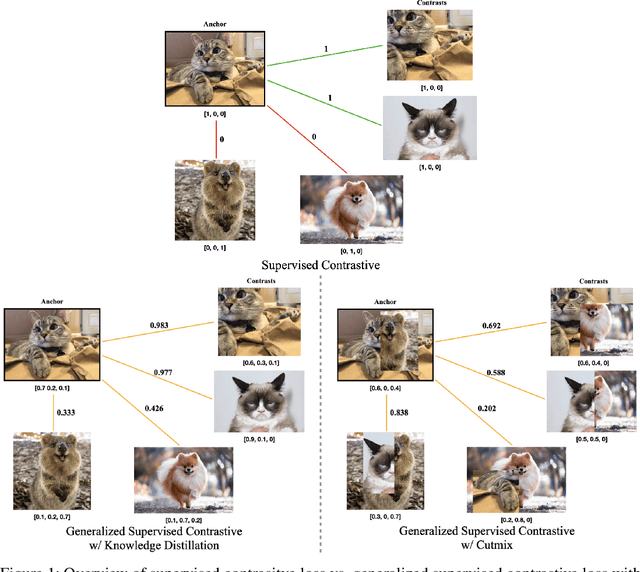

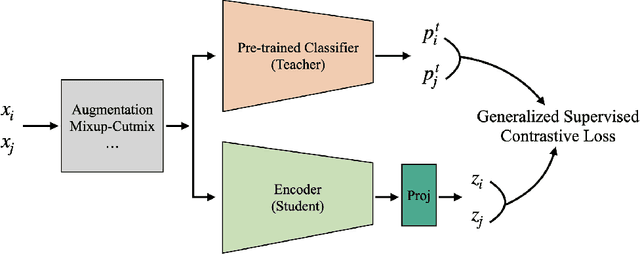

Based on recent remarkable achievements of contrastive learning in self-supervised representation learning, supervised contrastive learning (SupCon) has successfully extended the batch contrastive approaches to the supervised context and outperformed cross-entropy on various datasets on ResNet. In this work, we present GenSCL: a generalized supervised contrastive learning framework that seamlessly adapts modern image-based regularizations (such as Mixup-Cutmix) and knowledge distillation (KD) to SupCon by our generalized supervised contrastive loss. Generalized supervised contrastive loss is a further extension of supervised contrastive loss measuring cross-entropy between the similarity of labels and that of latent features. Then a model can learn to what extent contrastives should be pulled closer to an anchor in the latent space. By explicitly and fully leveraging label information, GenSCL breaks the boundary between conventional positives and negatives, and any kind of pre-trained teacher classifier can be utilized. ResNet-50 trained in GenSCL with Mixup-Cutmix and KD achieves state-of-the-art accuracies of 97.6% and 84.7% on CIFAR10 and CIFAR100 without external data, which significantly improves the results reported in the original SupCon (1.6% and 8.2%, respectively). Pytorch implementation is available at https://t.ly/yuUO.
Silent Tracker: In-band Beam Management for Soft Handover for mm-Wave Networks
Jul 18, 2021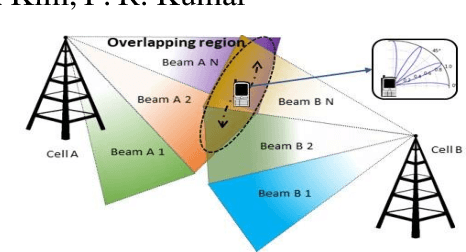
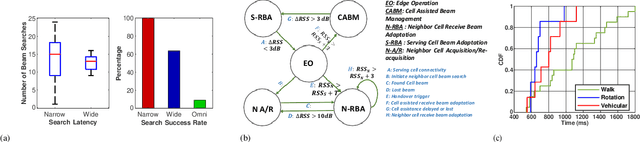
In mm-wave networks, cell sizes are small due to high path and penetration losses. Mobiles need to frequently switch softly from one cell to another to preserve network connections and context. Each soft handover involves the mobile performing directional neighbor cell search, tracking cell beam, completing cell access request, and finally, context switching. The mobile must independently discover cell beams, derive timing information, and maintain beam alignment throughout the process to avoid packet loss and hard handover. We propose Silent tracker which enables a mobile to reliably manage handover events by maintaining an aligned beam until the successful handover completion. It is entirely in-band beam mechanism that does not need any side information. Experimental evaluations show that Silent Tracker maintains the mobile's receive beam aligned to the potential target base station's transmit beam till the successful conclusion of handover in three mobility scenarios: human walk, device rotation, and 20 mph vehicular speed.