 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM2IV: Towards Efficient and Fine-grained Multimodal In-Context Learning in Large Vision-Language Models
Apr 06, 2025Multimodal in-context learning (ICL) is a vital capability for Large Vision-Language Models (LVLMs), allowing task adaptation via contextual prompts without parameter retraining. However, its application is hindered by the token-intensive nature of inputs and the high complexity of cross-modal few-shot learning, which limits the expressive power of representation methods. To tackle these challenges, we propose \textbf{M2IV}, a method that substitutes explicit demonstrations with learnable \textbf{I}n-context \textbf{V}ectors directly integrated into LVLMs. By exploiting the complementary strengths of multi-head attention (\textbf{M}HA) and multi-layer perceptrons (\textbf{M}LP), M2IV achieves robust cross-modal fidelity and fine-grained semantic distillation through training. This significantly enhances performance across diverse LVLMs and tasks and scales efficiently to many-shot scenarios, bypassing the context window limitations. We also introduce \textbf{VLibrary}, a repository for storing and retrieving M2IV, enabling flexible LVLM steering for tasks like cross-modal alignment, customized generation and safety improvement. Experiments across seven benchmarks and three LVLMs show that M2IV surpasses Vanilla ICL and prior representation engineering approaches, with an average accuracy gain of \textbf{3.74\%} over ICL with the same shot count, alongside substantial efficiency advantages.
Unifying Prediction and Explanation in Time-Series Transformers via Shapley-based Pretraining
Jan 25, 2025



In this paper, we propose ShapTST, a framework that enables time-series transformers to efficiently generate Shapley-value-based explanations alongside predictions in a single forward pass. Shapley values are widely used to evaluate the contribution of different time-steps and features in a test sample, and are commonly generated through repeatedly inferring on each sample with different parts of information removed. Therefore, it requires expensive inference-time computations that occur at every request for model explanations. In contrast, our framework unifies the explanation and prediction in training through a novel Shapley-based pre-training design, which eliminates the undesirable test-time computation and replaces it with a single-time pre-training. Moreover, this specialized pre-training benefits the prediction performance by making the transformer model more effectively weigh different features and time-steps in the time-series, particularly improving the robustness against data noise that is common to raw time-series data. We experimentally validated our approach on eight public datasets, where our time-series model achieved competitive results in both classification and regression tasks, while providing Shapley-based explanations similar to those obtained with post-hoc computation. Our work offers an efficient and explainable solution for time-series analysis tasks in the safety-critical applications.
Patch-aware Vector Quantized Codebook Learning for Unsupervised Visual Defect Detection
Jan 15, 2025


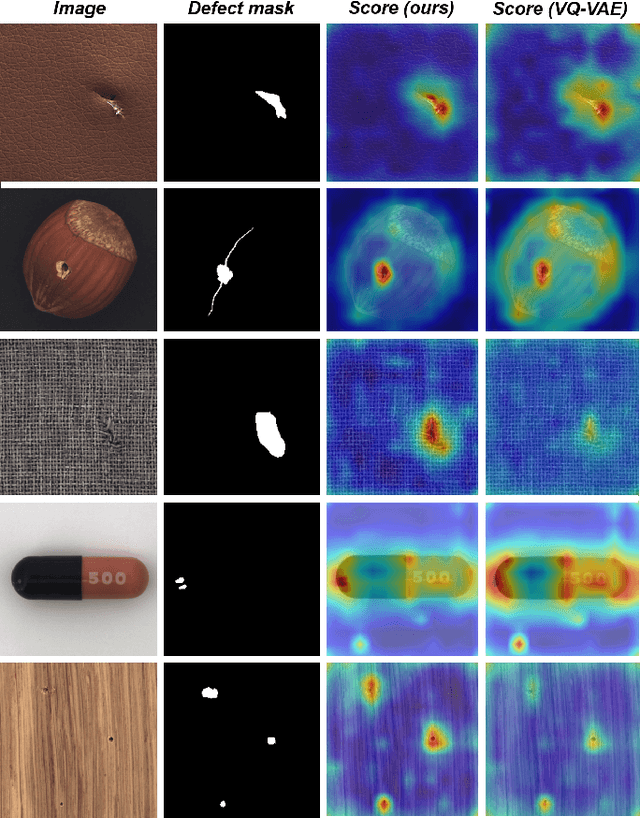
Unsupervised visual defect detection is critical in industrial applications, requiring a representation space that captures normal data features while detecting deviations. Achieving a balance between expressiveness and compactness is challenging; an overly expressive space risks inefficiency and mode collapse, impairing detection accuracy. We propose a novel approach using an enhanced VQ-VAE framework optimized for unsupervised defect detection. Our model introduces a patch-aware dynamic code assignment scheme, enabling context-sensitive code allocation to optimize spatial representation. This strategy enhances normal-defect distinction and improves detection accuracy during inference. Experiments on MVTecAD, BTAD, and MTSD datasets show our method achieves state-of-the-art performance.
Multi-view Fuzzy Graph Attention Networks for Enhanced Graph Learning
Dec 23, 2024Fuzzy Graph Attention Network (FGAT), which combines Fuzzy Rough Sets and Graph Attention Networks, has shown promise in tasks requiring robust graph-based learning. However, existing models struggle to effectively capture dependencies from multiple perspectives, limiting their ability to model complex data. To address this gap, we propose the Multi-view Fuzzy Graph Attention Network (MFGAT), a novel framework that constructs and aggregates multi-view information using a specially designed Transformation Block. This block dynamically transforms data from multiple aspects and aggregates the resulting representations via a weighted sum mechanism, enabling comprehensive multi-view modeling. The aggregated information is fed into FGAT to enhance fuzzy graph convolutions. Additionally, we introduce a simple yet effective learnable global pooling mechanism for improved graph-level understanding. Extensive experiments on graph classification tasks demonstrate that MFGAT outperforms state-of-the-art baselines, underscoring its effectiveness and versatility.
Gradient-Free Classifier Guidance for Diffusion Model Sampling
Nov 23, 2024



Image generation using diffusion models have demonstrated outstanding learning capabilities, effectively capturing the full distribution of the training dataset. They are known to generate wide variations in sampled images, albeit with a trade-off in image fidelity. Guided sampling methods, such as classifier guidance (CG) and classifier-free guidance (CFG), focus sampling in well-learned high-probability regions to generate images of high fidelity, but each has its limitations. CG is computationally expensive due to the use of back-propagation for classifier gradient descent, while CFG, being gradient-free, is more efficient but compromises class label alignment compared to CG. In this work, we propose an efficient guidance method that fully utilizes a pre-trained classifier without using gradient descent. By using the classifier solely in inference mode, a time-adaptive reference class label and corresponding guidance scale are determined at each time step for guided sampling. Experiments on both class-conditioned and text-to-image generation diffusion models demonstrate that the proposed Gradient-free Classifier Guidance (GFCG) method consistently improves class prediction accuracy. We also show GFCG to be complementary to other guided sampling methods like CFG. When combined with the state-of-the-art Autoguidance (ATG), without additional computational overhead, it enhances image fidelity while preserving diversity. For ImageNet 512$\times$512, we achieve a record $\text{FD}_{\text{DINOv2}}$ of 23.09, while simultaneously attaining a higher classification Precision (94.3%) compared to ATG (90.2%)
SHAPNN: Shapley Value Regularized Tabular Neural Network
Sep 15, 2023We present SHAPNN, a novel deep tabular data modeling architecture designed for supervised learning. Our approach leverages Shapley values, a well-established technique for explaining black-box models. Our neural network is trained using standard backward propagation optimization methods, and is regularized with realtime estimated Shapley values. Our method offers several advantages, including the ability to provide valid explanations with no computational overhead for data instances and datasets. Additionally, prediction with explanation serves as a regularizer, which improves the model's performance. Moreover, the regularized prediction enhances the model's capability for continual learning. We evaluate our method on various publicly available datasets and compare it with state-of-the-art deep neural network models, demonstrating the superior performance of SHAPNN in terms of AUROC, transparency, as well as robustness to streaming data.