 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatch-aware Vector Quantized Codebook Learning for Unsupervised Visual Defect Detection
Jan 15, 2025


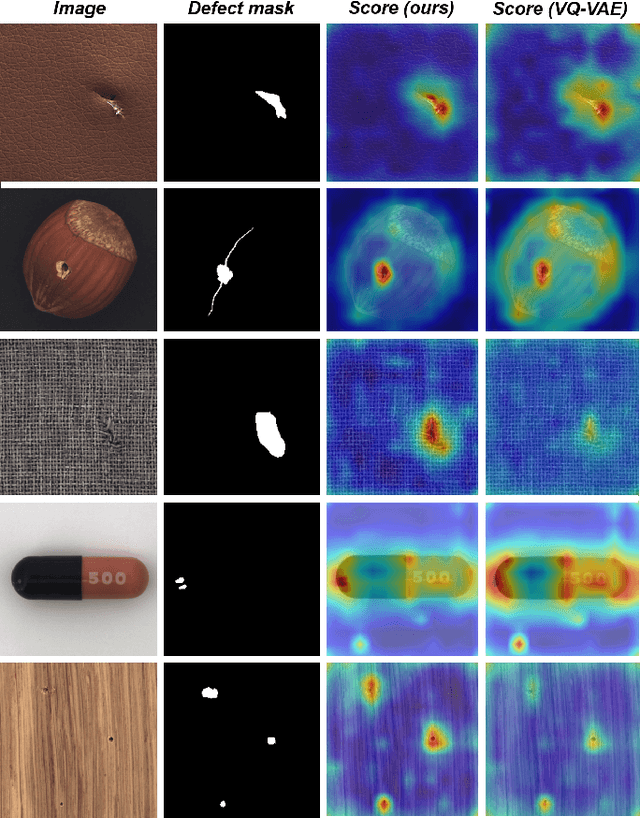
Unsupervised visual defect detection is critical in industrial applications, requiring a representation space that captures normal data features while detecting deviations. Achieving a balance between expressiveness and compactness is challenging; an overly expressive space risks inefficiency and mode collapse, impairing detection accuracy. We propose a novel approach using an enhanced VQ-VAE framework optimized for unsupervised defect detection. Our model introduces a patch-aware dynamic code assignment scheme, enabling context-sensitive code allocation to optimize spatial representation. This strategy enhances normal-defect distinction and improves detection accuracy during inference. Experiments on MVTecAD, BTAD, and MTSD datasets show our method achieves state-of-the-art performance.
RILQ: Rank-Insensitive LoRA-based Quantization Error Compensation for Boosting 2-bit Large Language Model Accuracy
Dec 02, 2024Low-rank adaptation (LoRA) has become the dominant method for parameter-efficient LLM fine-tuning, with LoRA-based quantization error compensation (LQEC) emerging as a powerful tool for recovering accuracy in compressed LLMs. However, LQEC has underperformed in sub-4-bit scenarios, with no prior investigation into understanding this limitation. We propose RILQ (Rank-Insensitive LoRA-based Quantization Error Compensation) to understand fundamental limitation and boost 2-bit LLM accuracy. Based on rank analysis revealing model-wise activation discrepancy loss's rank-insensitive nature, RILQ employs this loss to adjust adapters cooperatively across layers, enabling robust error compensation with low-rank adapters. Evaluations on LLaMA-2 and LLaMA-3 demonstrate RILQ's consistent improvements in 2-bit quantized inference across various state-of-the-art quantizers and enhanced accuracy in task-specific fine-tuning. RILQ maintains computational efficiency comparable to existing LoRA methods, enabling adapter-merged weight-quantized LLM inference with significantly enhanced accuracy, making it a promising approach for boosting 2-bit LLM performance.
AMXFP4: Taming Activation Outliers with Asymmetric Microscaling Floating-Point for 4-bit LLM Inference
Nov 15, 2024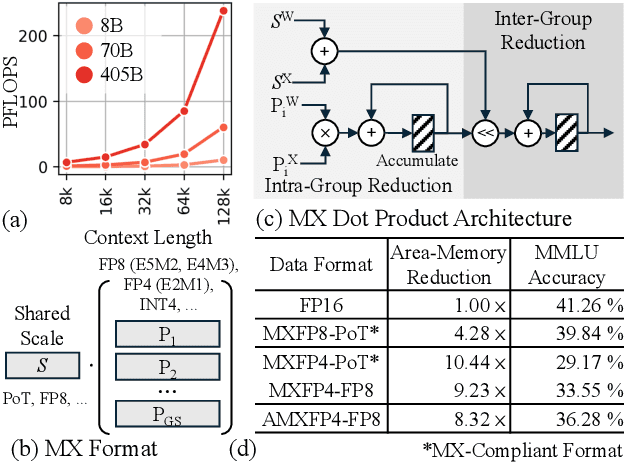
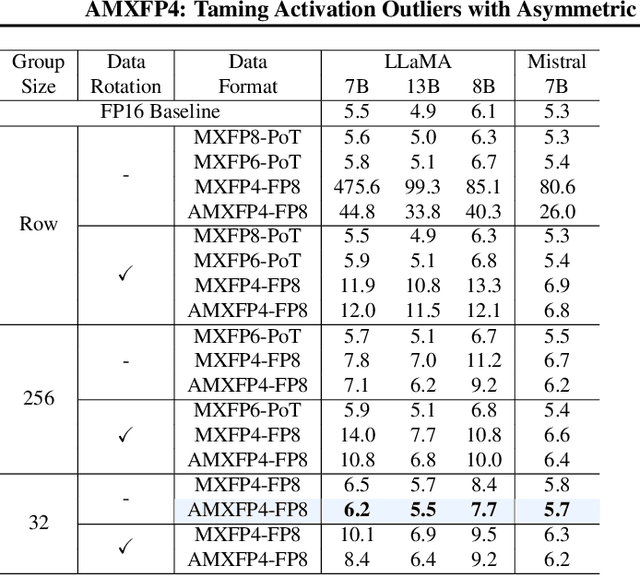
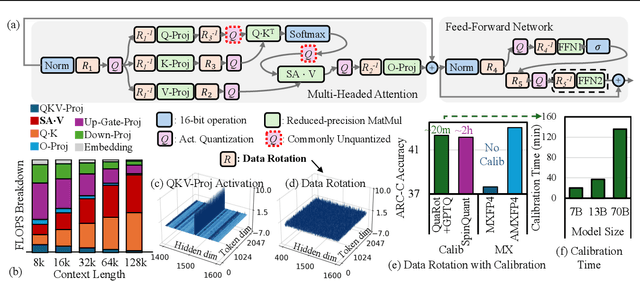
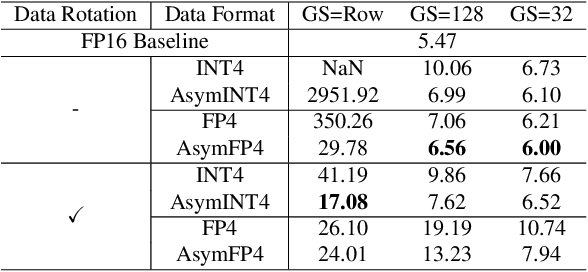
Scaling Large Language Models (LLMs) with extended context lengths has increased the need for efficient low-bit quantization to manage their substantial computational demands. However, reducing precision to 4 bits frequently degrades performance due to activation outliers. To address this, we propose Asymmetric Microscaling 4-bit Floating-Point (AMXFP4) for efficient LLM inference. This novel data format leverages asymmetric shared scales to mitigate outliers while naturally capturing the asymmetry introduced by group-wise quantization. Unlike conventional 4-bit quantization methods that rely on data rotation and costly calibration, AMXFP4 uses asymmetric shared scales for direct 4-bit casting, achieving near-ideal quantization accuracy across various LLM tasks, including multi-turn conversations, long-context reasoning, and visual question answering. Our AMXFP4 format significantly outperforms MXFP4 and other leading quantization techniques, enabling robust, calibration-free 4-bit inference.
Efficient Generation of Molecular Clusters with Dual-Scale Equivariant Flow Matching
Oct 10, 2024Amorphous molecular solids offer a promising alternative to inorganic semiconductors, owing to their mechanical flexibility and solution processability. The packing structure of these materials plays a crucial role in determining their electronic and transport properties, which are key to enhancing the efficiency of devices like organic solar cells (OSCs). However, obtaining these optoelectronic properties computationally requires molecular dynamics (MD) simulations to generate a conformational ensemble, a process that can be computationally expensive due to the large system sizes involved. Recent advances have focused on using generative models, particularly flow-based models as Boltzmann generators, to improve the efficiency of MD sampling. In this work, we developed a dual-scale flow matching method that separates training and inference into coarse-grained and all-atom stages and enhances both the accuracy and efficiency of standard flow matching samplers. We demonstrate the effectiveness of this method on a dataset of Y6 molecular clusters obtained through MD simulations, and we benchmark its efficiency and accuracy against single-scale flow matching methods.
Improving Conversational Abilities of Quantized Large Language Models via Direct Preference Alignment
Jul 03, 2024The rapid advancement of large language models (LLMs) has facilitated their transformation into conversational chatbots that can grasp contextual nuances and generate pertinent sentences, closely mirroring human values through advanced techniques such as instruction tuning and reinforcement learning from human feedback (RLHF). However, the computational efficiency required for LLMs, achieved through techniques like post-training quantization (PTQ), presents challenges such as token-flipping that can impair chatbot performance. In response, we propose a novel preference alignment approach, quantization-aware direct preference optimization (QDPO), that aligns quantized LLMs with their full-precision counterparts, improving conversational abilities. Evaluated on two instruction-tuned LLMs in various languages, QDPO demonstrated superior performance in improving conversational abilities compared to established PTQ and knowledge-distillation fine-tuning techniques, marking a significant step forward in the development of efficient and effective conversational LLMs.
SHAPNN: Shapley Value Regularized Tabular Neural Network
Sep 15, 2023We present SHAPNN, a novel deep tabular data modeling architecture designed for supervised learning. Our approach leverages Shapley values, a well-established technique for explaining black-box models. Our neural network is trained using standard backward propagation optimization methods, and is regularized with realtime estimated Shapley values. Our method offers several advantages, including the ability to provide valid explanations with no computational overhead for data instances and datasets. Additionally, prediction with explanation serves as a regularizer, which improves the model's performance. Moreover, the regularized prediction enhances the model's capability for continual learning. We evaluate our method on various publicly available datasets and compare it with state-of-the-art deep neural network models, demonstrating the superior performance of SHAPNN in terms of AUROC, transparency, as well as robustness to streaming data.
Token-Scaled Logit Distillation for Ternary Weight Generative Language Models
Aug 13, 2023Generative Language Models (GLMs) have shown impressive performance in tasks such as text generation, understanding, and reasoning. However, the large model size poses challenges for practical deployment. To solve this problem, Quantization-Aware Training (QAT) has become increasingly popular. However, current QAT methods for generative models have resulted in a noticeable loss of accuracy. To counteract this issue, we propose a novel knowledge distillation method specifically designed for GLMs. Our method, called token-scaled logit distillation, prevents overfitting and provides superior learning from the teacher model and ground truth. This research marks the first evaluation of ternary weight quantization-aware training of large-scale GLMs with less than 1.0 degradation in perplexity and no loss of accuracy in a reasoning task.
PillarAcc: Sparse PointPillars Accelerator for Real-Time Point Cloud 3D Object Detection on Edge Devices
May 15, 2023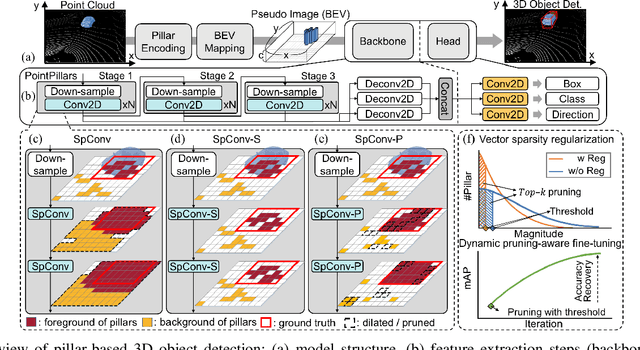
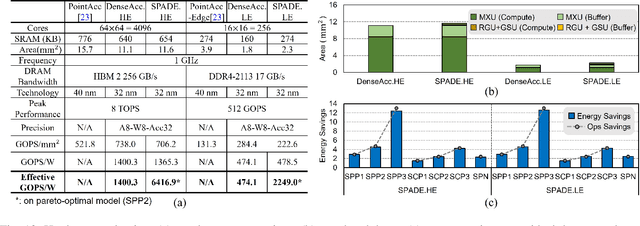
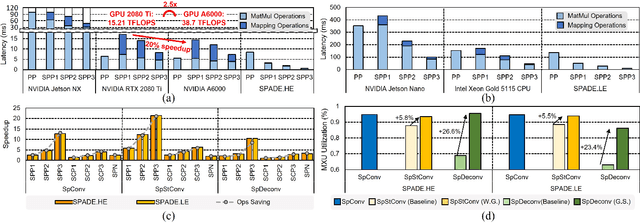
3D object detection using point cloud (PC) data is vital for autonomous driving perception pipelines, where efficient encoding is key to meeting stringent resource and latency requirements. PointPillars, a widely adopted bird's-eye view (BEV) encoding, aggregates 3D point cloud data into 2D pillars for high-accuracy 3D object detection. However, most state-of-the-art methods employing PointPillar overlook the inherent sparsity of pillar encoding, missing opportunities for significant computational reduction. In this study, we propose a groundbreaking algorithm-hardware co-design that accelerates sparse convolution processing and maximizes sparsity utilization in pillar-based 3D object detection networks. We investigate sparsification opportunities using an advanced pillar-pruning method, achieving an optimal balance between accuracy and sparsity. We introduce PillarAcc, a state-of-the-art sparsity support mechanism that enhances sparse pillar convolution through linear complexity input-output mapping generation and conflict-free gather-scatter memory access. Additionally, we propose dataflow optimization techniques, dynamically adjusting the pillar processing schedule for optimal hardware utilization under diverse sparsity operations. We evaluate PillarAcc on various cutting-edge 3D object detection networks and benchmarks, achieving remarkable speedup and energy savings compared to representative edge platforms, demonstrating record-breaking PointPillars speed of 500FPS with minimal compromise in accuracy.