 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMXFP4: Taming Activation Outliers with Asymmetric Microscaling Floating-Point for 4-bit LLM Inference
Nov 15, 2024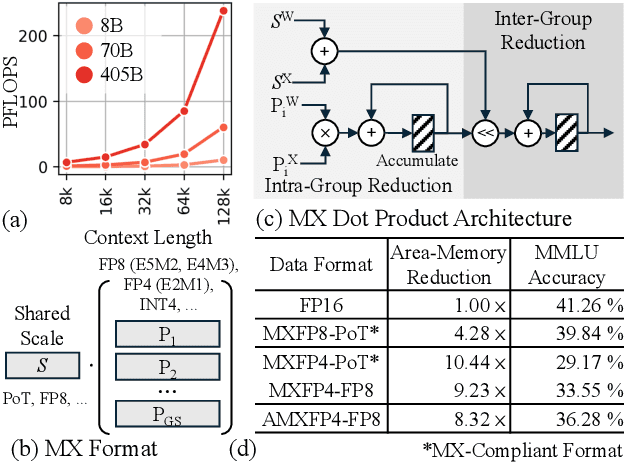
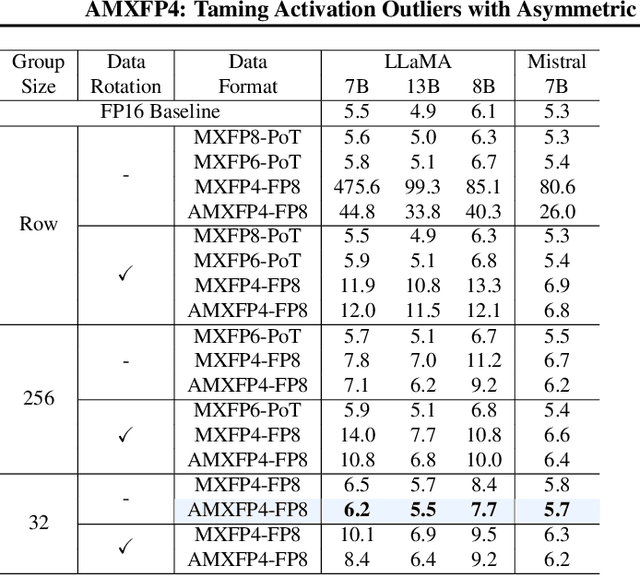
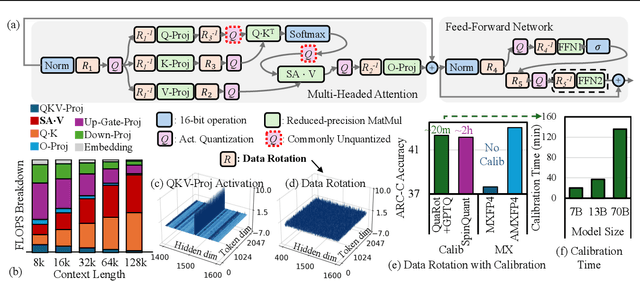
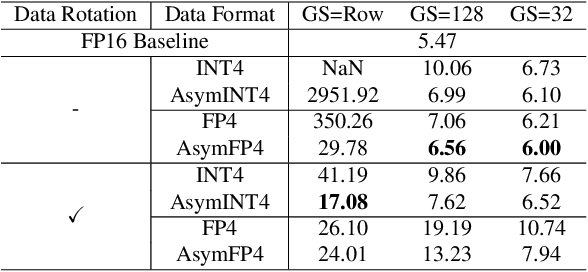
Scaling Large Language Models (LLMs) with extended context lengths has increased the need for efficient low-bit quantization to manage their substantial computational demands. However, reducing precision to 4 bits frequently degrades performance due to activation outliers. To address this, we propose Asymmetric Microscaling 4-bit Floating-Point (AMXFP4) for efficient LLM inference. This novel data format leverages asymmetric shared scales to mitigate outliers while naturally capturing the asymmetry introduced by group-wise quantization. Unlike conventional 4-bit quantization methods that rely on data rotation and costly calibration, AMXFP4 uses asymmetric shared scales for direct 4-bit casting, achieving near-ideal quantization accuracy across various LLM tasks, including multi-turn conversations, long-context reasoning, and visual question answering. Our AMXFP4 format significantly outperforms MXFP4 and other leading quantization techniques, enabling robust, calibration-free 4-bit inference.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.