 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMXFP4: Taming Activation Outliers with Asymmetric Microscaling Floating-Point for 4-bit LLM Inference
Nov 15, 2024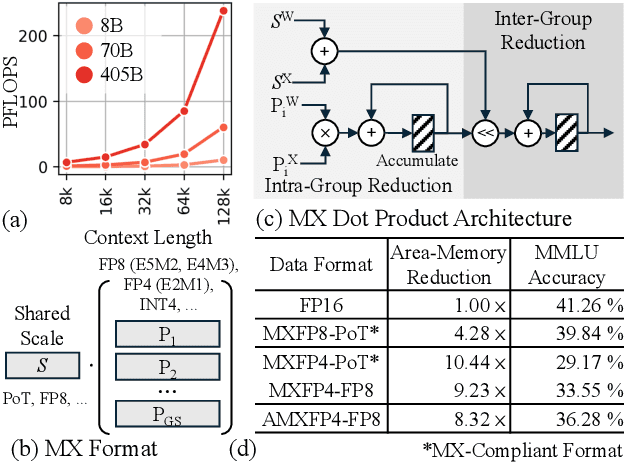
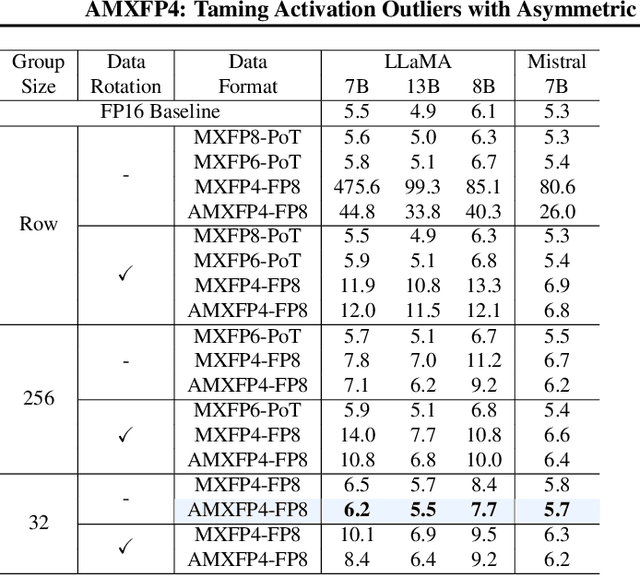
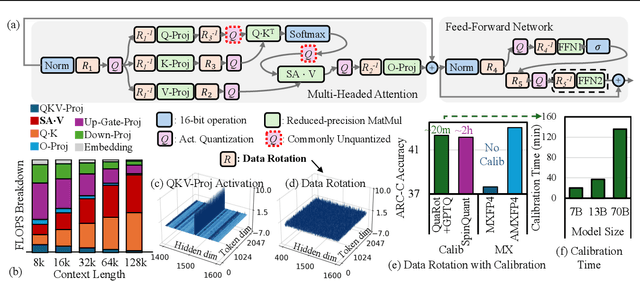
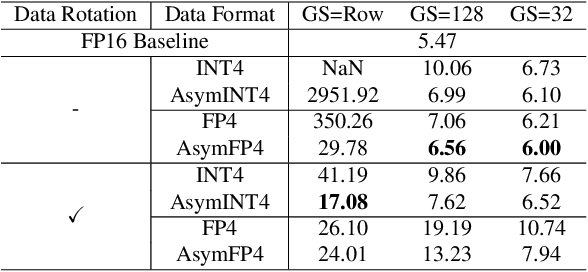
Scaling Large Language Models (LLMs) with extended context lengths has increased the need for efficient low-bit quantization to manage their substantial computational demands. However, reducing precision to 4 bits frequently degrades performance due to activation outliers. To address this, we propose Asymmetric Microscaling 4-bit Floating-Point (AMXFP4) for efficient LLM inference. This novel data format leverages asymmetric shared scales to mitigate outliers while naturally capturing the asymmetry introduced by group-wise quantization. Unlike conventional 4-bit quantization methods that rely on data rotation and costly calibration, AMXFP4 uses asymmetric shared scales for direct 4-bit casting, achieving near-ideal quantization accuracy across various LLM tasks, including multi-turn conversations, long-context reasoning, and visual question answering. Our AMXFP4 format significantly outperforms MXFP4 and other leading quantization techniques, enabling robust, calibration-free 4-bit inference.