 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLG Uplus System with Multi-Speaker IDs and Discriminator-based Sub-Judges for the WildSpoof Challenge
Dec 09, 2025This paper describes our submission to the WildSpoof Challenge Track 2, which focuses on spoof-aware speaker verification (SASV) in the presence of high-quality text-to-speech (TTS) attacks. We adopt a ResNet-221 back-bone and study two speaker-labeling strategies, namelyDual-Speaker IDs and Multi-Speaker IDs, to explicitly enlarge the margin between bona fide and generated speech in the embedding space. In addition, we propose discriminator-based sub-judge systems that reuse internal features from HiFi-GAN and BigVGAN discriminators, aggregated via multi-query multi-head attentive statistics pooling(MQMHA). Experimental results on the SpoofCeleb corpus show that our system design is effective in improving agnostic detection cost function (a-DCF).
Enhancing Generalization in Data-free Quantization via Mixup-class Prompting
Jul 29, 2025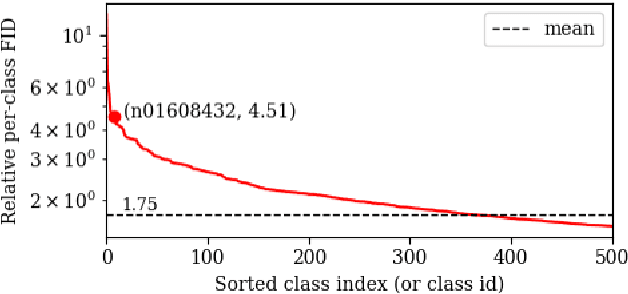
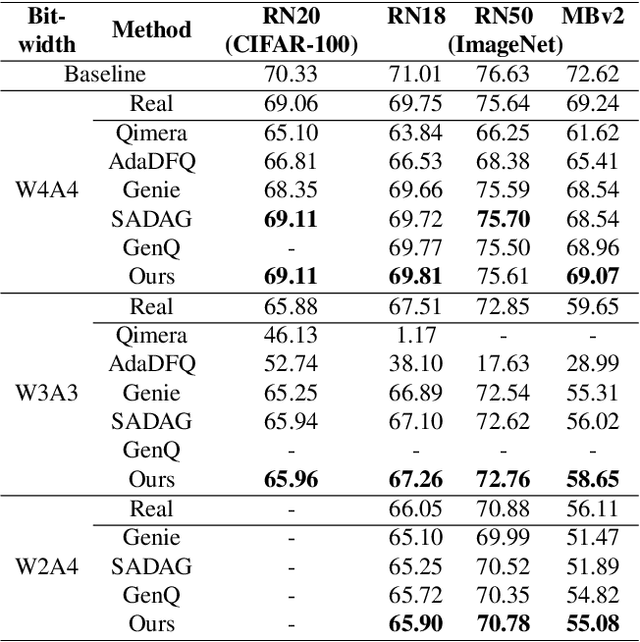
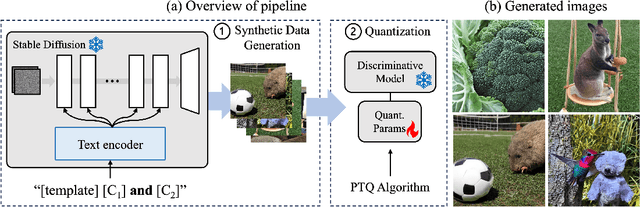
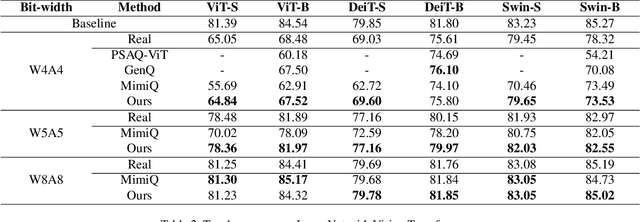
Post-training quantization (PTQ) improves efficiency but struggles with limited calibration data, especially under privacy constraints. Data-free quantization (DFQ) mitigates this by generating synthetic images using generative models such as generative adversarial networks (GANs) and text-conditioned latent diffusion models (LDMs), while applying existing PTQ algorithms. However, the relationship between generated synthetic images and the generalizability of the quantized model during PTQ remains underexplored. Without investigating this relationship, synthetic images generated by previous prompt engineering methods based on single-class prompts suffer from issues such as polysemy, leading to performance degradation. We propose \textbf{mixup-class prompt}, a mixup-based text prompting strategy that fuses multiple class labels at the text prompt level to generate diverse, robust synthetic data. This approach enhances generalization, and improves optimization stability in PTQ. We provide quantitative insights through gradient norm and generalization error analysis. Experiments on convolutional neural networks (CNNs) and vision transformers (ViTs) show that our method consistently outperforms state-of-the-art DFQ methods like GenQ. Furthermore, it pushes the performance boundary in extremely low-bit scenarios, achieving new state-of-the-art accuracy in challenging 2-bit weight, 4-bit activation (W2A4) quantization.
AMXFP4: Taming Activation Outliers with Asymmetric Microscaling Floating-Point for 4-bit LLM Inference
Nov 15, 2024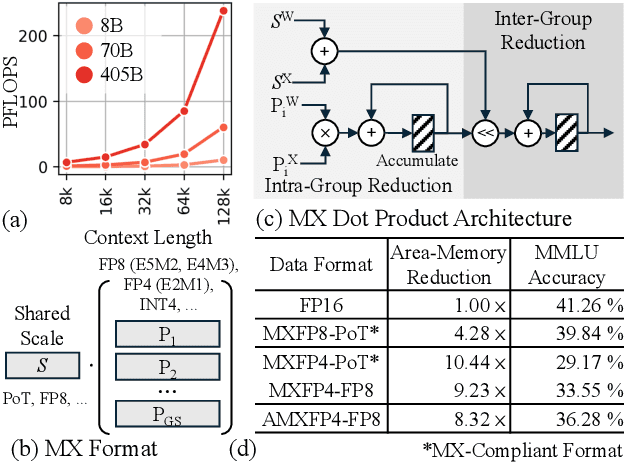
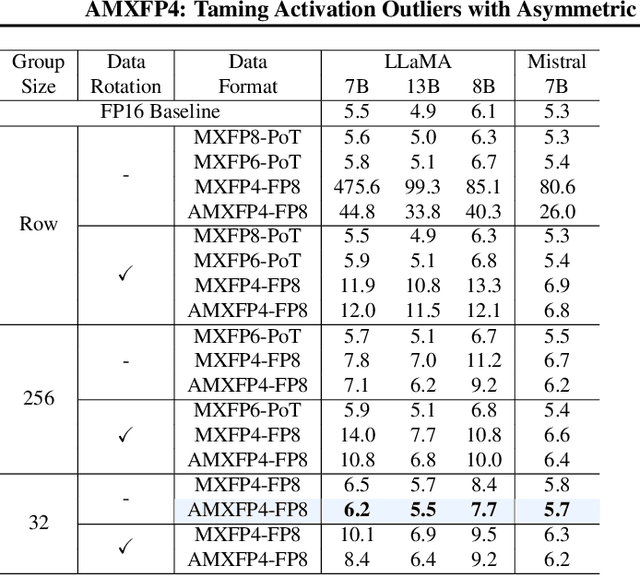
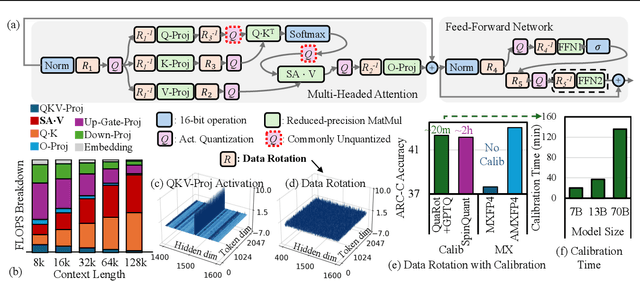
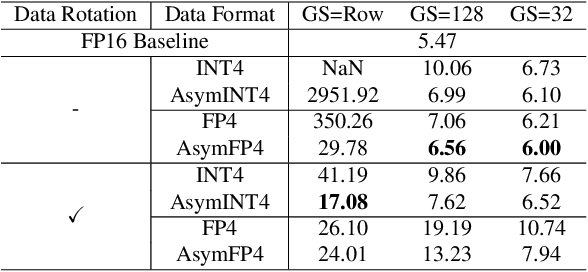
Scaling Large Language Models (LLMs) with extended context lengths has increased the need for efficient low-bit quantization to manage their substantial computational demands. However, reducing precision to 4 bits frequently degrades performance due to activation outliers. To address this, we propose Asymmetric Microscaling 4-bit Floating-Point (AMXFP4) for efficient LLM inference. This novel data format leverages asymmetric shared scales to mitigate outliers while naturally capturing the asymmetry introduced by group-wise quantization. Unlike conventional 4-bit quantization methods that rely on data rotation and costly calibration, AMXFP4 uses asymmetric shared scales for direct 4-bit casting, achieving near-ideal quantization accuracy across various LLM tasks, including multi-turn conversations, long-context reasoning, and visual question answering. Our AMXFP4 format significantly outperforms MXFP4 and other leading quantization techniques, enabling robust, calibration-free 4-bit inference.
Equivariant Blurring Diffusion for Hierarchical Molecular Conformer Generation
Oct 26, 2024



How can diffusion models process 3D geometries in a coarse-to-fine manner, akin to our multiscale view of the world? In this paper, we address the question by focusing on a fundamental biochemical problem of generating 3D molecular conformers conditioned on molecular graphs in a multiscale manner. Our approach consists of two hierarchical stages: i) generation of coarse-grained fragment-level 3D structure from the molecular graph, and ii) generation of fine atomic details from the coarse-grained approximated structure while allowing the latter to be adjusted simultaneously. For the challenging second stage, which demands preserving coarse-grained information while ensuring SE(3) equivariance, we introduce a novel generative model termed Equivariant Blurring Diffusion (EBD), which defines a forward process that moves towards the fragment-level coarse-grained structure by blurring the fine atomic details of conformers, and a reverse process that performs the opposite operation using equivariant networks. We demonstrate the effectiveness of EBD by geometric and chemical comparison to state-of-the-art denoising diffusion models on a benchmark of drug-like molecules. Ablation studies draw insights on the design of EBD by thoroughly analyzing its architecture, which includes the design of the loss function and the data corruption process. Codes are released at https://github.com/Shen-Lab/EBD .
Confidence-Based Feature Imputation for Graphs with Partially Known Features
May 29, 2023



This paper investigates a missing feature imputation problem for graph learning tasks. Several methods have previously addressed learning tasks on graphs with missing features. However, in cases of high rates of missing features, they were unable to avoid significant performance degradation. To overcome this limitation, we introduce a novel concept of channel-wise confidence in a node feature, which is assigned to each imputed channel feature of a node for reflecting certainty of the imputation. We then design pseudo-confidence using the channel-wise shortest path distance between a missing-feature node and its nearest known-feature node to replace unavailable true confidence in an actual learning process. Based on the pseudo-confidence, we propose a novel feature imputation scheme that performs channel-wise inter-node diffusion and node-wise inter-channel propagation. The scheme can endure even at an exceedingly high missing rate (e.g., 99.5\%) and it achieves state-of-the-art accuracy for both semi-supervised node classification and link prediction on various datasets containing a high rate of missing features. Codes are available at https://github.com/daehoum1/pcfi.
Meta-node: A Concise Approach to Effectively Learn Complex Relationships in Heterogeneous Graphs
Oct 26, 2022



Existing message passing neural networks for heterogeneous graphs rely on the concepts of meta-paths or meta-graphs due to the intrinsic nature of heterogeneous graphs. However, the meta-paths and meta-graphs need to be pre-configured before learning and are highly dependent on expert knowledge to construct them. To tackle this challenge, we propose a novel concept of meta-node for message passing that can learn enriched relational knowledge from complex heterogeneous graphs without any meta-paths and meta-graphs by explicitly modeling the relations among the same type of nodes. Unlike meta-paths and meta-graphs, meta-nodes do not require any pre-processing steps that require expert knowledge. Going one step further, we propose a meta-node message passing scheme and apply our method to a contrastive learning model. In the experiments on node clustering and classification tasks, the proposed meta-node message passing method outperforms state-of-the-arts that depend on meta-paths. Our results demonstrate that effective heterogeneous graph learning is possible without the need for meta-paths that are frequently used in this field.
Unsupervised Hyperbolic Representation Learning via Message Passing Auto-Encoders
Mar 30, 2021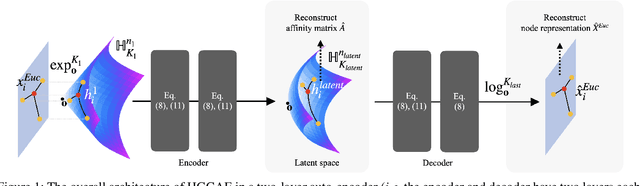
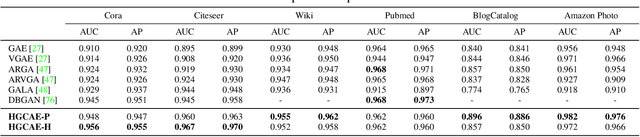

Most of the existing literature regarding hyperbolic embedding concentrate upon supervised learning, whereas the use of unsupervised hyperbolic embedding is less well explored. In this paper, we analyze how unsupervised tasks can benefit from learned representations in hyperbolic space. To explore how well the hierarchical structure of unlabeled data can be represented in hyperbolic spaces, we design a novel hyperbolic message passing auto-encoder whose overall auto-encoding is performed in hyperbolic space. The proposed model conducts auto-encoding the networks via fully utilizing hyperbolic geometry in message passing. Through extensive quantitative and qualitative analyses, we validate the properties and benefits of the unsupervised hyperbolic representations. Codes are available at https://github.com/junhocho/HGCAE.
Symmetric Graph Convolutional Autoencoder for Unsupervised Graph Representation Learning
Aug 07, 2019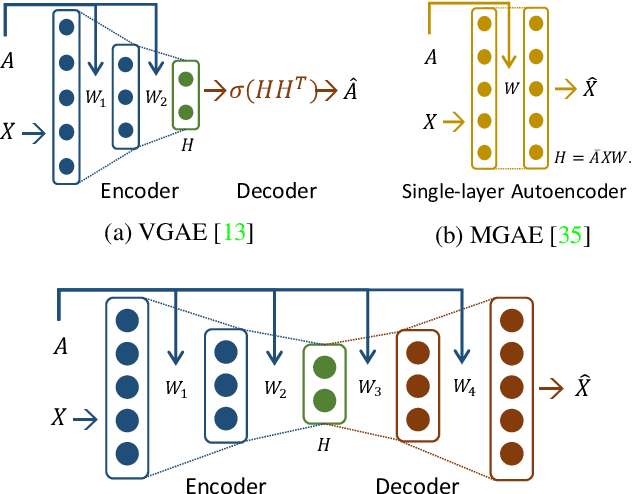
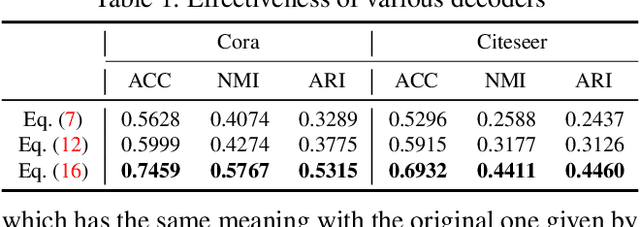

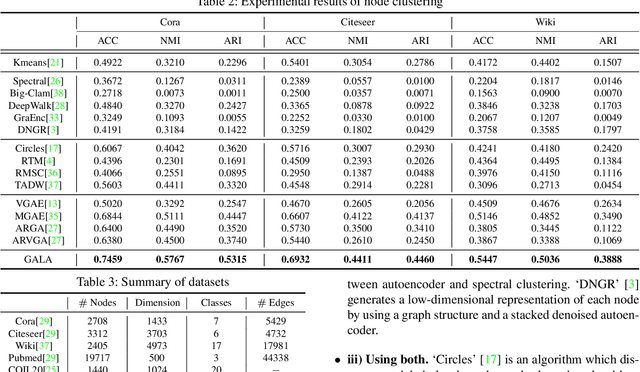
We propose a symmetric graph convolutional autoencoder which produces a low-dimensional latent representation from a graph. In contrast to the existing graph autoencoders with asymmetric decoder parts, the proposed autoencoder has a newly designed decoder which builds a completely symmetric autoencoder form. For the reconstruction of node features, the decoder is designed based on Laplacian sharpening as the counterpart of Laplacian smoothing of the encoder, which allows utilizing the graph structure in the whole processes of the proposed autoencoder architecture. In order to prevent the numerical instability of the network caused by the Laplacian sharpening introduction, we further propose a new numerically stable form of the Laplacian sharpening by incorporating the signed graphs. In addition, a new cost function which finds a latent representation and a latent affinity matrix simultaneously is devised to boost the performance of image clustering tasks. The experimental results on clustering, link prediction and visualization tasks strongly support that the proposed model is stable and outperforms various state-of-the-art algorithms.