 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Conformal Prediction with Adversarial Semi-bandit Feedback via Regret Minimization
Apr 20, 2026Uncertainty quantification is crucial in safety-critical systems, where decisions must be made under uncertainty. In particular, we consider the problem of online uncertainty quantification, where data points arrive sequentially. Online conformal prediction is a principled online uncertainty quantification method that dynamically constructs a prediction set at each time step. While existing methods for online conformal prediction provide long-run coverage guarantees without any distributional assumptions, they typically assume a full feedback setting in which the true label is always observed. In this paper, we propose a novel learning method for online conformal prediction with partial feedback from an adaptive adversary-a more challenging setup where the true label is revealed only when it lies inside the constructed prediction set. Specifically, we formulate online conformal prediction as an adversarial bandit problem by treating each candidate prediction set as an arm. Building on an existing algorithm for adversarial bandits, our method achieves a long-run coverage guarantee by explicitly establishing its connection to the regret of the learner. Finally, we empirically demonstrate the effectiveness of our method in both independent and identically distributed (i.i.d.) and non-i.i.d. settings, showing that it successfully controls the miscoverage rate while maintaining a reasonable size of the prediction set.
Transductive Generalization via Optimal Transport and Its Application to Graph Node Classification
Mar 10, 2026Many existing transductive bounds rely on classical complexity measures that are computationally intractable and often misaligned with empirical behavior. In this work, we establish new representation-based generalization bounds in a distribution-free transductive setting, where learned representations are dependent, and test features are accessible during training. We derive global and class-wise bounds via optimal transport, expressed in terms of Wasserstein distances between encoded feature distributions. We demonstrate that our bounds are efficiently computable and strongly correlate with empirical generalization in graph node classification, improving upon classical complexity measures. Additionally, our analysis reveals how the GNN aggregation process transforms the representation distributions, inducing a trade-off between intra-class concentration and inter-class separation. This yields depth-dependent characterizations that capture the non-monotonic relationship between depth and generalization error observed in practice. The code is available at https://github.com/ml-postech/Transductive-OT-Gen-Bound.
Probabilistic Multi-Agent Aircraft Landing Time Prediction
Dec 09, 2025Accurate and reliable aircraft landing time prediction is essential for effective resource allocation in air traffic management. However, the inherent uncertainty of aircraft trajectories and traffic flows poses significant challenges to both prediction accuracy and trustworthiness. Therefore, prediction models should not only provide point estimates of aircraft landing times but also the uncertainties associated with these predictions. Furthermore, aircraft trajectories are frequently influenced by the presence of nearby aircraft through air traffic control interventions such as radar vectoring. Consequently, landing time prediction models must account for multi-agent interactions in the airspace. In this work, we propose a probabilistic multi-agent aircraft landing time prediction framework that provides the landing times of multiple aircraft as distributions. We evaluate the proposed framework using an air traffic surveillance dataset collected from the terminal airspace of the Incheon International Airport in South Korea. The results demonstrate that the proposed model achieves higher prediction accuracy than the baselines and quantifies the associated uncertainties of its outcomes. In addition, the model uncovered underlying patterns in air traffic control through its attention scores, thereby enhancing explainability.
Adapting World Models with Latent-State Dynamics Residuals
Apr 03, 2025Simulation-to-reality reinforcement learning (RL) faces the critical challenge of reconciling discrepancies between simulated and real-world dynamics, which can severely degrade agent performance. A promising approach involves learning corrections to simulator forward dynamics represented as a residual error function, however this operation is impractical with high-dimensional states such as images. To overcome this, we propose ReDRAW, a latent-state autoregressive world model pretrained in simulation and calibrated to target environments through residual corrections of latent-state dynamics rather than of explicit observed states. Using this adapted world model, ReDRAW enables RL agents to be optimized with imagined rollouts under corrected dynamics and then deployed in the real world. In multiple vision-based MuJoCo domains and a physical robot visual lane-following task, ReDRAW effectively models changes to dynamics and avoids overfitting in low data regimes where traditional transfer methods fail.
TARDiS : Text Augmentation for Refining Diversity and Separability
Jan 06, 2025



Text augmentation (TA) is a critical technique for text classification, especially in few-shot settings. This paper introduces a novel LLM-based TA method, TARDiS, to address challenges inherent in the generation and alignment stages of two-stage TA methods. For the generation stage, we propose two generation processes, SEG and CEG, incorporating multiple class-specific prompts to enhance diversity and separability. For the alignment stage, we introduce a class adaptation (CA) method to ensure that generated examples align with their target classes through verification and modification. Experimental results demonstrate TARDiS's effectiveness, outperforming state-of-the-art LLM-based TA methods in various few-shot text classification tasks. An in-depth analysis confirms the detailed behaviors at each stage.
Make the Pertinent Salient: Task-Relevant Reconstruction for Visual Control with Distractions
Oct 13, 2024

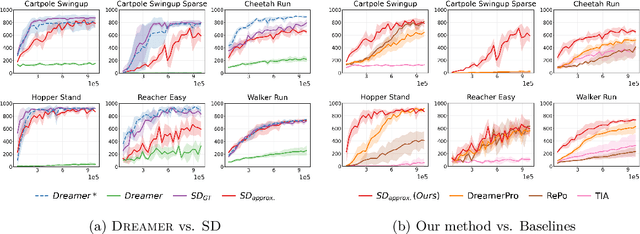
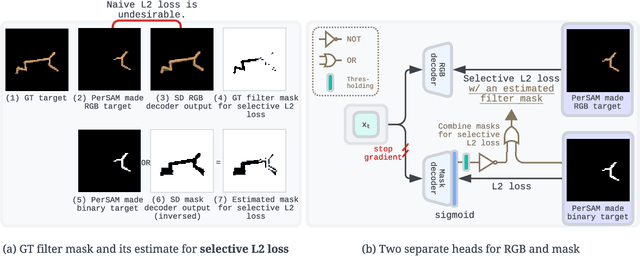
Recent advancements in Model-Based Reinforcement Learning (MBRL) have made it a powerful tool for visual control tasks. Despite improved data efficiency, it remains challenging to train MBRL agents with generalizable perception. Training in the presence of visual distractions is particularly difficult due to the high variation they introduce to representation learning. Building on DREAMER, a popular MBRL method, we propose a simple yet effective auxiliary task to facilitate representation learning in distracting environments. Under the assumption that task-relevant components of image observations are straightforward to identify with prior knowledge in a given task, we use a segmentation mask on image observations to only reconstruct task-relevant components. In doing so, we greatly reduce the complexity of representation learning by removing the need to encode task-irrelevant objects in the latent representation. Our method, Segmentation Dreamer (SD), can be used either with ground-truth masks easily accessible in simulation or by leveraging potentially imperfect segmentation foundation models. The latter is further improved by selectively applying the reconstruction loss to avoid providing misleading learning signals due to mask prediction errors. In modified DeepMind Control suite (DMC) and Meta-World tasks with added visual distractions, SD achieves significantly better sample efficiency and greater final performance than prior work. We find that SD is especially helpful in sparse reward tasks otherwise unsolvable by prior work, enabling the training of visually robust agents without the need for extensive reward engineering.
Realizable Continuous-Space Shields for Safe Reinforcement Learning
Oct 02, 2024



While Deep Reinforcement Learning (DRL) has achieved remarkable success across various domains, it remains vulnerable to occasional catastrophic failures without additional safeguards. One effective solution to prevent these failures is to use a shield that validates and adjusts the agent's actions to ensure compliance with a provided set of safety specifications. For real-life robot domains, it is desirable to be able to define such safety specifications over continuous state and action spaces to accurately account for system dynamics and calculate new safe actions that minimally alter the agent's output. In this paper, we propose the first shielding approach to automatically guarantee the realizability of safety requirements for continuous state and action spaces. Realizability is an essential property that confirms the shield will always be able to generate a safe action for any state in the environment. We formally prove that realizability can also be verified with a stateful shield, enabling the incorporation of non-Markovian safety requirements. Finally, we demonstrate the effectiveness of our approach in ensuring safety without compromising policy accuracy by applying it to a navigation problem and a multi-agent particle environment.
Rethinking Data Augmentation for Robust LiDAR Semantic Segmentation in Adverse Weather
Jul 02, 2024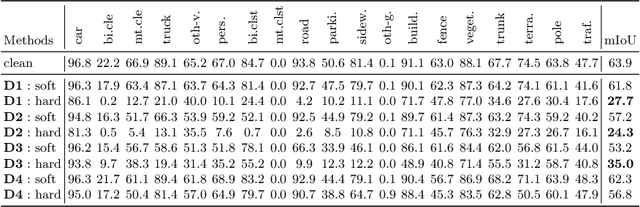

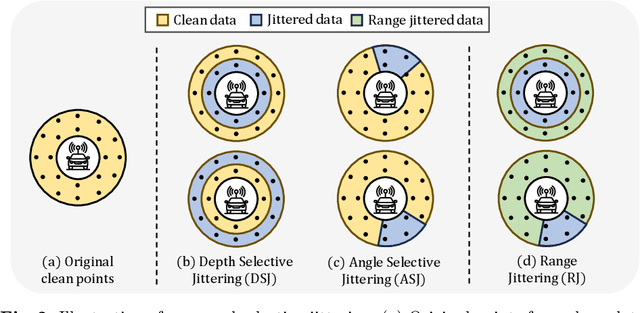
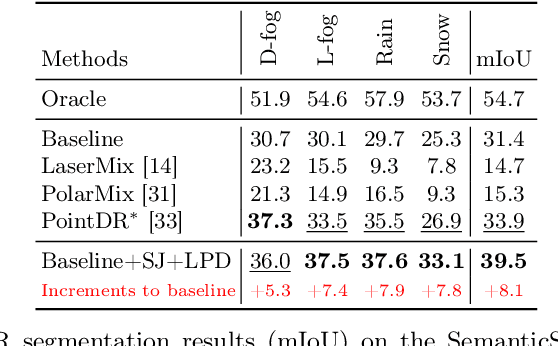
Existing LiDAR semantic segmentation methods often struggle with performance declines in adverse weather conditions. Previous research has addressed this issue by simulating adverse weather or employing universal data augmentation during training. However, these methods lack a detailed analysis and understanding of how adverse weather negatively affects LiDAR semantic segmentation performance. Motivated by this issue, we identified key factors of adverse weather and conducted a toy experiment to pinpoint the main causes of performance degradation: (1) Geometric perturbation due to refraction caused by fog or droplets in the air and (2) Point drop due to energy absorption and occlusions. Based on these findings, we propose new strategic data augmentation techniques. First, we introduced a Selective Jittering (SJ) that jitters points in the random range of depth (or angle) to mimic geometric perturbation. Additionally, we developed a Learnable Point Drop (LPD) to learn vulnerable erase patterns with Deep Q-Learning Network to approximate the point drop phenomenon from adverse weather conditions. Without precise weather simulation, these techniques strengthen the LiDAR semantic segmentation model by exposing it to vulnerable conditions identified by our data-centric analysis. Experimental results confirmed the suitability of the proposed data augmentation methods for enhancing robustness against adverse weather conditions. Our method attains a remarkable 39.5 mIoU on the SemanticKITTI-to-SemanticSTF benchmark, surpassing the previous state-of-the-art by over 5.4%p, tripling the improvement over the baseline compared to previous methods achieved.
Reinforcement Learning from Delayed Observations via World Models
Mar 18, 2024In standard Reinforcement Learning settings, agents typically assume immediate feedback about the effects of their actions after taking them. However, in practice, this assumption may not hold true due to physical constraints and can significantly impact the performance of RL algorithms. In this paper, we focus on addressing observation delays in partially observable environments. We propose leveraging world models, which have shown success in integrating past observations and learning dynamics, to handle observation delays. By reducing delayed POMDPs to delayed MDPs with world models, our methods can effectively handle partial observability, where existing approaches achieve sub-optimal performance or even degrade quickly as observability decreases. Experiments suggest that one of our methods can outperform a naive model-based approach by up to %30. Moreover, we evaluate our methods on visual input based delayed environment, for the first time showcasing delay-aware reinforcement learning on visual observations.
Selective Perception: Optimizing State Descriptions with Reinforcement Learning for Language Model Actors
Jul 21, 2023


Large language models (LLMs) are being applied as actors for sequential decision making tasks in domains such as robotics and games, utilizing their general world knowledge and planning abilities. However, previous work does little to explore what environment state information is provided to LLM actors via language. Exhaustively describing high-dimensional states can impair performance and raise inference costs for LLM actors. Previous LLM actors avoid the issue by relying on hand-engineered, task-specific protocols to determine which features to communicate about a state and which to leave out. In this work, we propose Brief Language INputs for DEcision-making Responses (BLINDER), a method for automatically selecting concise state descriptions by learning a value function for task-conditioned state descriptions. We evaluate BLINDER on the challenging video game NetHack and a robotic manipulation task. Our method improves task success rate, reduces input size and compute costs, and generalizes between LLM actors.