 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextGuider: Training-Free Guidance for Text Rendering via Attention Alignment
Dec 13, 2025
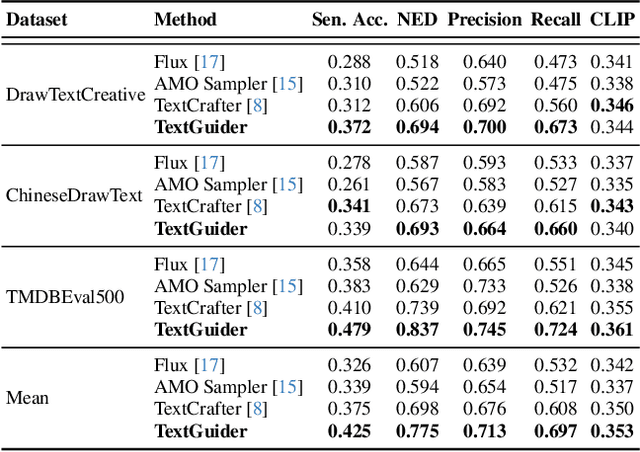
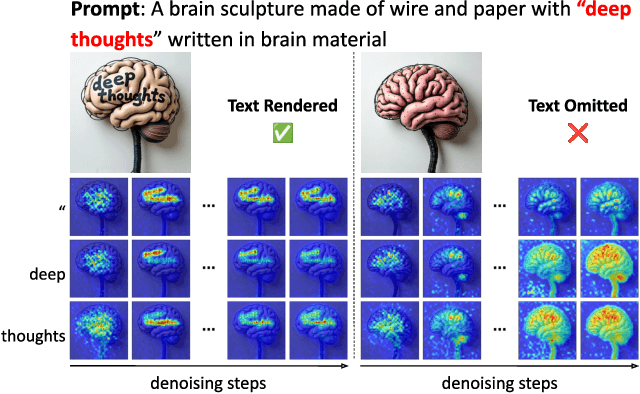
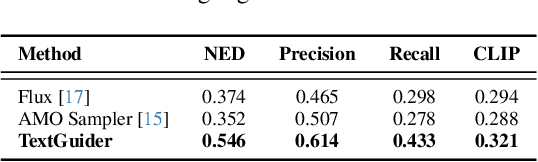
Despite recent advances, diffusion-based text-to-image models still struggle with accurate text rendering. Several studies have proposed fine-tuning or training-free refinement methods for accurate text rendering. However, the critical issue of text omission, where the desired text is partially or entirely missing, remains largely overlooked. In this work, we propose TextGuider, a novel training-free method that encourages accurate and complete text appearance by aligning textual content tokens and text regions in the image. Specifically, we analyze attention patterns in Multi-Modal Diffusion Transformer(MM-DiT) models, particularly for text-related tokens intended to be rendered in the image. Leveraging this observation, we apply latent guidance during the early stage of denoising steps based on two loss functions that we introduce. Our method achieves state-of-the-art performance in test-time text rendering, with significant gains in recall and strong results in OCR accuracy and CLIP score.
Hierarchical Visual Feature Aggregation for OCR-Free Document Understanding
Nov 08, 2024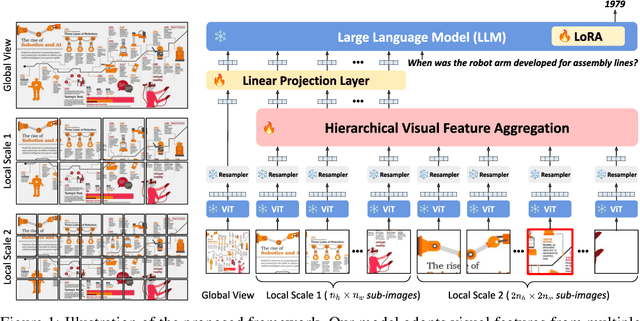

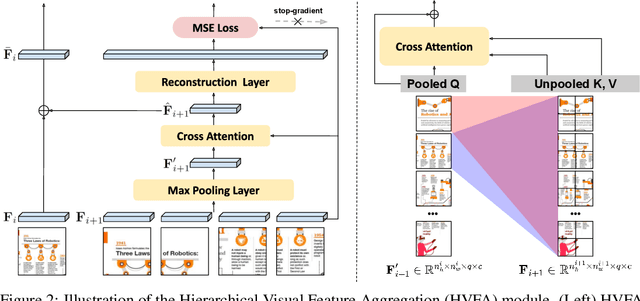
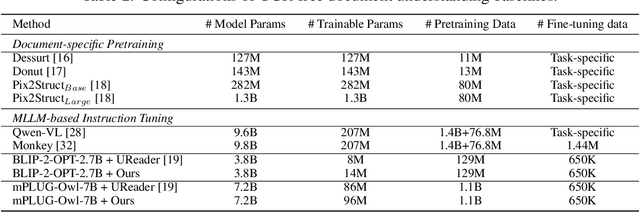
We present a novel OCR-free document understanding framework based on pretrained Multimodal Large Language Models (MLLMs). Our approach employs multi-scale visual features to effectively handle various font sizes within document images. To address the increasing costs of considering the multi-scale visual inputs for MLLMs, we propose the Hierarchical Visual Feature Aggregation (HVFA) module, designed to reduce the number of input tokens to LLMs. Leveraging a feature pyramid with cross-attentive pooling, our approach effectively manages the trade-off between information loss and efficiency without being affected by varying document image sizes. Furthermore, we introduce a novel instruction tuning task, which facilitates the model's text-reading capability by learning to predict the relative positions of input text, eventually minimizing the risk of truncated text caused by the limited capacity of LLMs. Comprehensive experiments validate the effectiveness of our approach, demonstrating superior performance in various document understanding tasks.
Active Learning for Finely-Categorized Image-Text Retrieval by Selecting Hard Negative Unpaired Samples
May 25, 2024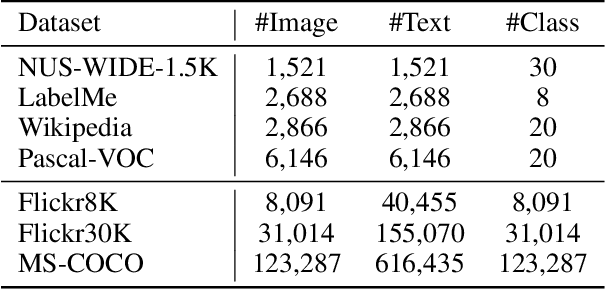

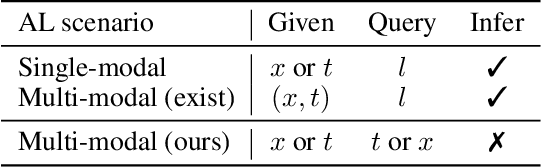
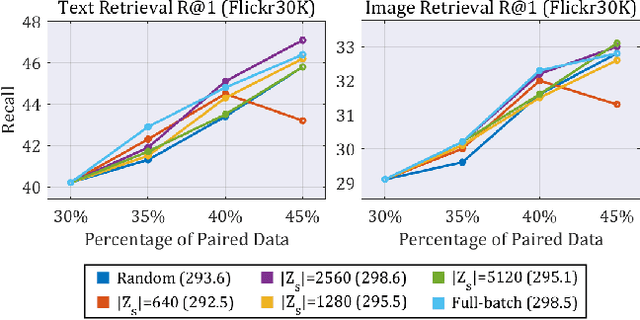
Securing a sufficient amount of paired data is important to train an image-text retrieval (ITR) model, but collecting paired data is very expensive. To address this issue, in this paper, we propose an active learning algorithm for ITR that can collect paired data cost-efficiently. Previous studies assume that image-text pairs are given and their category labels are asked to the annotator. However, in the recent ITR studies, the importance of category label is decreased since a retrieval model can be trained with only image-text pairs. For this reason, we set up an active learning scenario where unpaired images (or texts) are given and the annotator provides corresponding texts (or images) to make paired data. The key idea of the proposed AL algorithm is to select unpaired images (or texts) that can be hard negative samples for existing texts (or images). To this end, we introduce a novel scoring function to choose hard negative samples. We validate the effectiveness of the proposed method on Flickr30K and MS-COCO datasets.
MoST: Motion Style Transformer between Diverse Action Contents
Mar 20, 2024



While existing motion style transfer methods are effective between two motions with identical content, their performance significantly diminishes when transferring style between motions with different contents. This challenge lies in the lack of clear separation between content and style of a motion. To tackle this challenge, we propose a novel motion style transformer that effectively disentangles style from content and generates a plausible motion with transferred style from a source motion. Our distinctive approach to achieving the goal of disentanglement is twofold: (1) a new architecture for motion style transformer with `part-attentive style modulator across body parts' and `Siamese encoders that encode style and content features separately'; (2) style disentanglement loss. Our method outperforms existing methods and demonstrates exceptionally high quality, particularly in motion pairs with different contents, without the need for heuristic post-processing. Codes are available at https://github.com/Boeun-Kim/MoST.
UFO: Unidentified Foreground Object Detection in 3D Point Cloud
Jan 08, 2024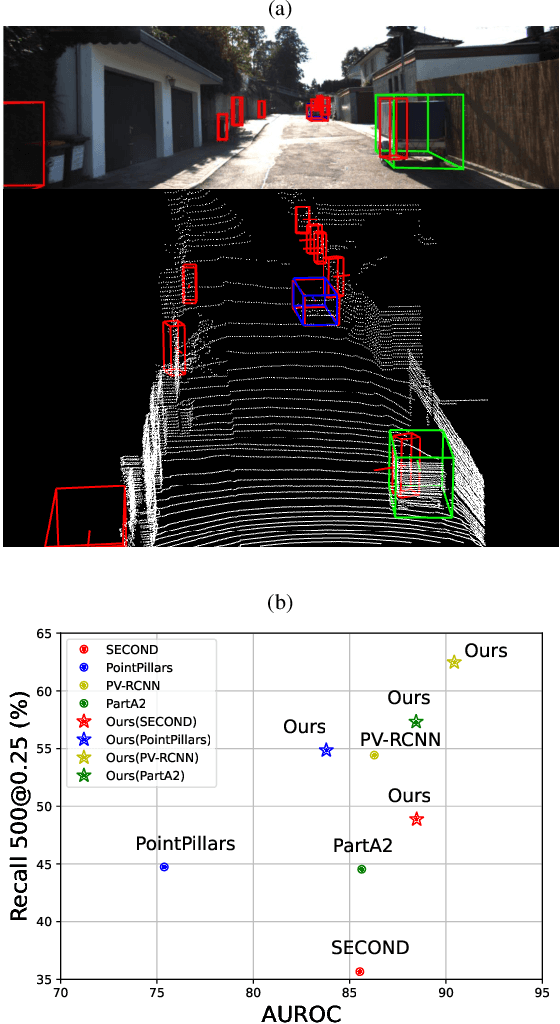
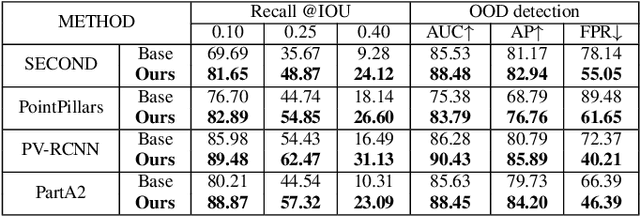
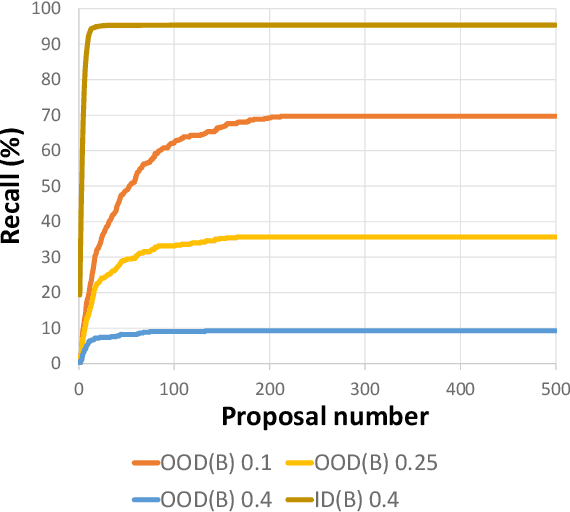
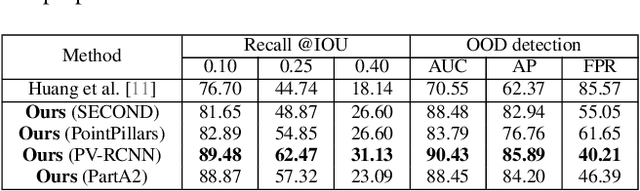
In this paper, we raise a new issue on Unidentified Foreground Object (UFO) detection in 3D point clouds, which is a crucial technology in autonomous driving in the wild. UFO detection is challenging in that existing 3D object detectors encounter extremely hard challenges in both 3D localization and Out-of-Distribution (OOD) detection. To tackle these challenges, we suggest a new UFO detection framework including three tasks: evaluation protocol, methodology, and benchmark. The evaluation includes a new approach to measure the performance on our goal, i.e. both localization and OOD detection of UFOs. The methodology includes practical techniques to enhance the performance of our goal. The benchmark is composed of the KITTI Misc benchmark and our additional synthetic benchmark for modeling a more diverse range of UFOs. The proposed framework consistently enhances performance by a large margin across all four baseline detectors: SECOND, PointPillars, PV-RCNN, and PartA2, giving insight for future work on UFO detection in the wild.
Gaussian Mixture Proposals with Pull-Push Learning Scheme to Capture Diverse Events for Weakly Supervised Temporal Video Grounding
Dec 27, 2023In the weakly supervised temporal video grounding study, previous methods use predetermined single Gaussian proposals which lack the ability to express diverse events described by the sentence query. To enhance the expression ability of a proposal, we propose a Gaussian mixture proposal (GMP) that can depict arbitrary shapes by learning importance, centroid, and range of every Gaussian in the mixture. In learning GMP, each Gaussian is not trained in a feature space but is implemented over a temporal location. Thus the conventional feature-based learning for Gaussian mixture model is not valid for our case. In our special setting, to learn moderately coupled Gaussian mixture capturing diverse events, we newly propose a pull-push learning scheme using pulling and pushing losses, each of which plays an opposite role to the other. The effects of components in our scheme are verified in-depth with extensive ablation studies and the overall scheme achieves state-of-the-art performance. Our code is available at https://github.com/sunoh-kim/pps.
Three Factors to Improve Out-of-Distribution Detection
Aug 02, 2023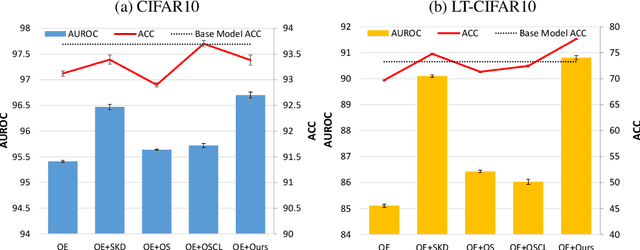
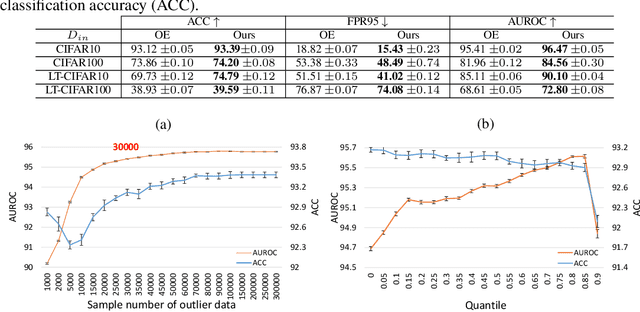
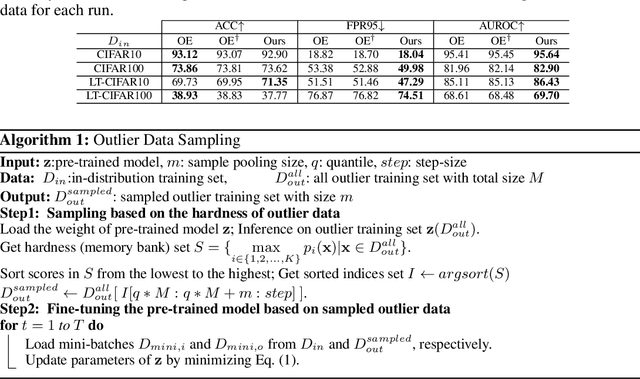

In the problem of out-of-distribution (OOD) detection, the usage of auxiliary data as outlier data for fine-tuning has demonstrated encouraging performance. However, previous methods have suffered from a trade-off between classification accuracy (ACC) and OOD detection performance (AUROC, FPR, AUPR). To improve this trade-off, we make three contributions: (i) Incorporating a self-knowledge distillation loss can enhance the accuracy of the network; (ii) Sampling semi-hard outlier data for training can improve OOD detection performance with minimal impact on accuracy; (iii) The introduction of our novel supervised contrastive learning can simultaneously improve OOD detection performance and the accuracy of the network. By incorporating all three factors, our approach enhances both accuracy and OOD detection performance by addressing the trade-off between classification and OOD detection. Our method achieves improvements over previous approaches in both performance metrics.
Balanced Energy Regularization Loss for Out-of-distribution Detection
Jun 18, 2023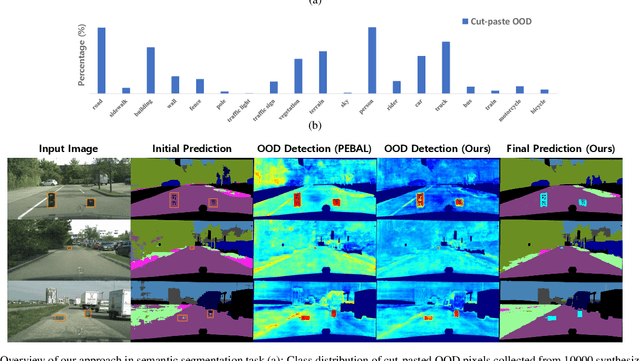
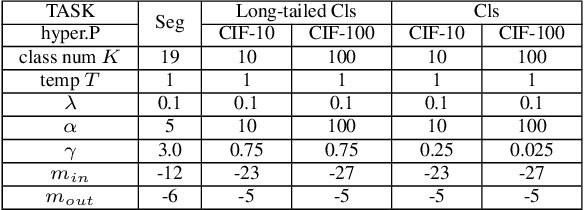
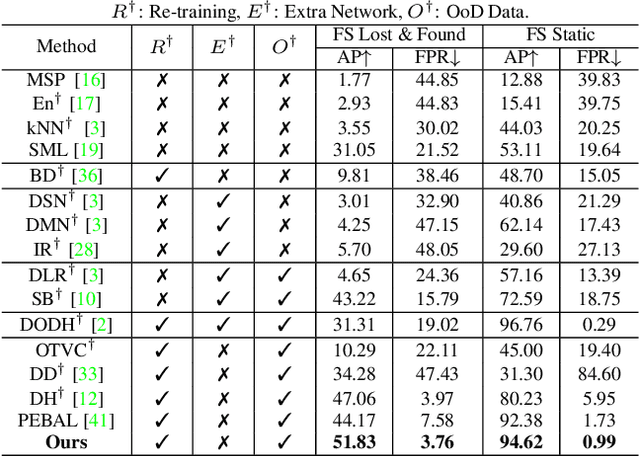
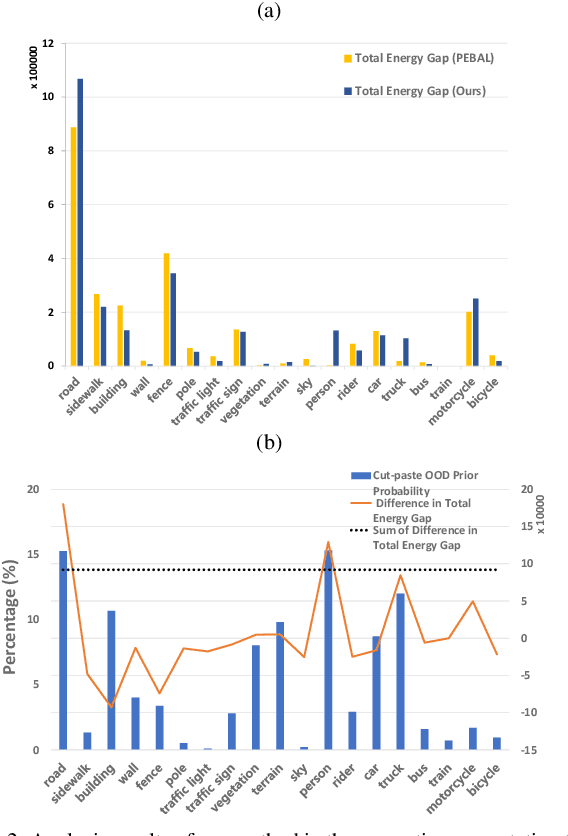
In the field of out-of-distribution (OOD) detection, a previous method that use auxiliary data as OOD data has shown promising performance. However, the method provides an equal loss to all auxiliary data to differentiate them from inliers. However, based on our observation, in various tasks, there is a general imbalance in the distribution of the auxiliary OOD data across classes. We propose a balanced energy regularization loss that is simple but generally effective for a variety of tasks. Our balanced energy regularization loss utilizes class-wise different prior probabilities for auxiliary data to address the class imbalance in OOD data. The main concept is to regularize auxiliary samples from majority classes, more heavily than those from minority classes. Our approach performs better for OOD detection in semantic segmentation, long-tailed image classification, and image classification than the prior energy regularization loss. Furthermore, our approach achieves state-of-the-art performance in two tasks: OOD detection in semantic segmentation and long-tailed image classification. Code is available at https://github.com/hyunjunChhoi/Balanced_Energy.
Confidence-Based Feature Imputation for Graphs with Partially Known Features
May 29, 2023



This paper investigates a missing feature imputation problem for graph learning tasks. Several methods have previously addressed learning tasks on graphs with missing features. However, in cases of high rates of missing features, they were unable to avoid significant performance degradation. To overcome this limitation, we introduce a novel concept of channel-wise confidence in a node feature, which is assigned to each imputed channel feature of a node for reflecting certainty of the imputation. We then design pseudo-confidence using the channel-wise shortest path distance between a missing-feature node and its nearest known-feature node to replace unavailable true confidence in an actual learning process. Based on the pseudo-confidence, we propose a novel feature imputation scheme that performs channel-wise inter-node diffusion and node-wise inter-channel propagation. The scheme can endure even at an exceedingly high missing rate (e.g., 99.5\%) and it achieves state-of-the-art accuracy for both semi-supervised node classification and link prediction on various datasets containing a high rate of missing features. Codes are available at https://github.com/daehoum1/pcfi.
RoCOCO: Robust Benchmark MS-COCO to Stress-test Robustness of Image-Text Matching Models
Apr 21, 2023Recently, large-scale vision-language pre-training models and visual semantic embedding methods have significantly improved image-text matching (ITM) accuracy on MS COCO 5K test set. However, it is unclear how robust these state-of-the-art (SOTA) models are when using them in the wild. In this paper, we propose a novel evaluation benchmark to stress-test the robustness of ITM models. To this end, we add various fooling images and captions to a retrieval pool. Specifically, we change images by inserting unrelated images, and change captions by substituting a noun, which can change the meaning of a sentence. We discover that just adding these newly created images and captions to the test set can degrade performances (i.e., Recall@1) of a wide range of SOTA models (e.g., 81.9% $\rightarrow$ 64.5% in BLIP, 66.1% $\rightarrow$ 37.5% in VSE$\infty$). We expect that our findings can provide insights for improving the robustness of the vision-language models and devising more diverse stress-test methods in cross-modal retrieval task. Source code and dataset will be available at https://github.com/pseulki/rococo.