 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSS-TPT: Stability and Suitability-Guided Test-Time Prompt Tuning for Adversarially Robust Vision-Language Models
Jun 05, 2026Vision-language models (VLMs) such as CLIP achieve strong zero-shot recognition but remain highly fragile under adversarial perturbations. Recent test-time adaptation defenses improve robustness by leveraging many augmented views, but this leads to impractical slowdown and a clear robustness-throughput trade-off. To address this challenge, we present Stability and Suitability-guided Test-time Prompt Tuning (SS-TPT), evaluating the quality of each augmented view via two complementary scores: (1) stability, measuring prediction invariance to weak augmentations, and (2) suitability, measuring feature-space density among views. These stability and suitability (SS) scores guide both adaptation and inference through an SS-guided consistency loss and an SS-weighted prediction, amplifying trustworthy views while suppressing corrupted ones. Extensive experiments demonstrate that SS-TPT significantly outperforms prior state-of-the-art methods, achieving superior robustness-throughput trade-offs across diverse datasets and varying numbers of views, thereby demonstrating both strong practicality and generality. Our code is available at https://github.com/sunoh-kim/SS-TPT.
When CLIP Sees More, It Fights Back Harder: Multi-View Guided Adaptive Counterattacks for Test-Time Adversarial Robustness
Jun 05, 2026Vision-language models such as CLIP have achieved remarkable zero-shot recognition capabilities, yet their robustness against adversarial perturbations remains limited. Test-time counterattack (TTC) was recently proposed to improve CLIP's robustness by perturbing an input image to steer it away from a corrupted state during inference. However, TTC remains fragile under strong attacks because its counterattack relies on a directly corrupted original view and employs a noise-driven hard-gating scheme that cannot adapt to varying corruption severity. To address these limitations, we introduce Multi-view guided Adaptive Counterattack (MAC), which performs counterattacks for multi-view with corruption-aware soft weighting. Specifically, MAC first constructs augmented views of an input image to obtain diverse embeddings. It then performs counterattacks to refine corrupted embeddings of views. Next, MAC adaptively scales the counterattack intensity for each view based on its estimated corruption degree. Finally, the adaptively counterattacked views are aggregated to yield a robust final prediction. Extensive experiments across 20 datasets and diverse attack scenarios demonstrate that MAC substantially improves robustness while preserving high inference speed and memory efficiency with its tuning-free design. Our code is available at https://github.com/sunoh-kim/MAC.
Finding Optimal Video Moment without Training: Gaussian Boundary Optimization for Weakly Supervised Video Grounding
Feb 03, 2026Weakly supervised temporal video grounding aims to localize query-relevant segments in untrimmed videos using only video-sentence pairs, without requiring ground-truth segment annotations that specify exact temporal boundaries. Recent approaches tackle this task by utilizing Gaussian-based temporal proposals to represent query-relevant segments. However, their inference strategies rely on heuristic mappings from Gaussian parameters to segment boundaries, resulting in suboptimal localization performance. To address this issue, we propose Gaussian Boundary Optimization (GBO), a novel inference framework that predicts segment boundaries by solving a principled optimization problem that balances proposal coverage and segment compactness. We derive a closed-form solution for this problem and rigorously analyze the optimality conditions under varying penalty regimes. Beyond its theoretical foundations, GBO offers several practical advantages: it is training-free and compatible with both single-Gaussian and mixture-based proposal architectures. Our experiments show that GBO significantly improves localization, achieving state-of-the-art results across standard benchmarks. Extensive experiments demonstrate the efficiency and generalizability of GBO across various proposal schemes. The code is available at \href{https://github.com/sunoh-kim/gbo}{https://github.com/sunoh-kim/gbo}.
Enhancing Weakly Supervised Video Grounding via Diverse Inference Strategies for Boundary and Prediction Selection
Mar 29, 2025Weakly supervised video grounding aims to localize temporal boundaries relevant to a given query without explicit ground-truth temporal boundaries. While existing methods primarily use Gaussian-based proposals, they overlook the importance of (1) boundary prediction and (2) top-1 prediction selection during inference. In their boundary prediction, boundaries are simply set at half a standard deviation away from a Gaussian mean on both sides, which may not accurately capture the optimal boundaries. In the top-1 prediction process, these existing methods rely heavily on intersections with other proposals, without considering the varying quality of each proposal. To address these issues, we explore various inference strategies by introducing (1) novel boundary prediction methods to capture diverse boundaries from multiple Gaussians and (2) new selection methods that take proposal quality into account. Extensive experiments on the ActivityNet Captions and Charades-STA datasets validate the effectiveness of our inference strategies, demonstrating performance improvements without requiring additional training.
Gaussian Mixture Proposals with Pull-Push Learning Scheme to Capture Diverse Events for Weakly Supervised Temporal Video Grounding
Dec 27, 2023



In the weakly supervised temporal video grounding study, previous methods use predetermined single Gaussian proposals which lack the ability to express diverse events described by the sentence query. To enhance the expression ability of a proposal, we propose a Gaussian mixture proposal (GMP) that can depict arbitrary shapes by learning importance, centroid, and range of every Gaussian in the mixture. In learning GMP, each Gaussian is not trained in a feature space but is implemented over a temporal location. Thus the conventional feature-based learning for Gaussian mixture model is not valid for our case. In our special setting, to learn moderately coupled Gaussian mixture capturing diverse events, we newly propose a pull-push learning scheme using pulling and pushing losses, each of which plays an opposite role to the other. The effects of components in our scheme are verified in-depth with extensive ablation studies and the overall scheme achieves state-of-the-art performance. Our code is available at https://github.com/sunoh-kim/pps.
Position-aware Location Regression Network for Temporal Video Grounding
Apr 12, 2022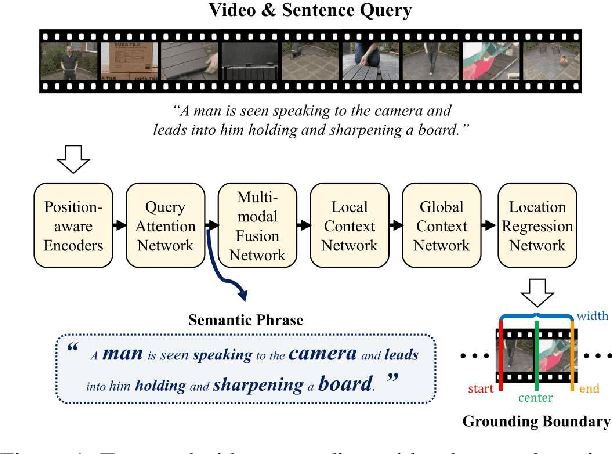
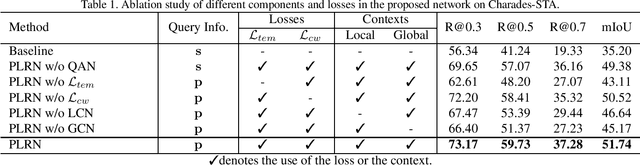
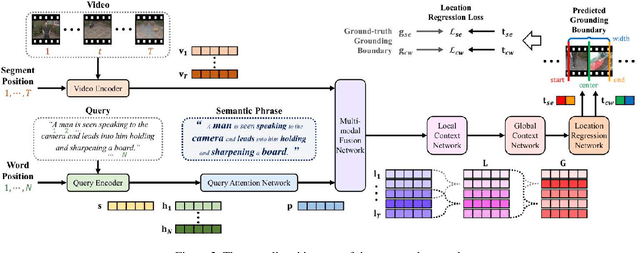

The key to successful grounding for video surveillance is to understand a semantic phrase corresponding to important actors and objects. Conventional methods ignore comprehensive contexts for the phrase or require heavy computation for multiple phrases. To understand comprehensive contexts with only one semantic phrase, we propose Position-aware Location Regression Network (PLRN) which exploits position-aware features of a query and a video. Specifically, PLRN first encodes both the video and query using positional information of words and video segments. Then, a semantic phrase feature is extracted from an encoded query with attention. The semantic phrase feature and encoded video are merged and made into a context-aware feature by reflecting local and global contexts. Finally, PLRN predicts start, end, center, and width values of a grounding boundary. Our experiments show that PLRN achieves competitive performance over existing methods with less computation time and memory.
Skeleton-based Action Recognition of People Handling Objects
Jan 21, 2019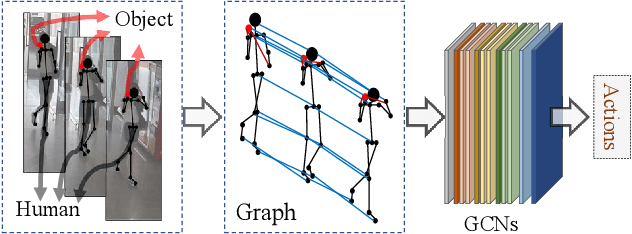


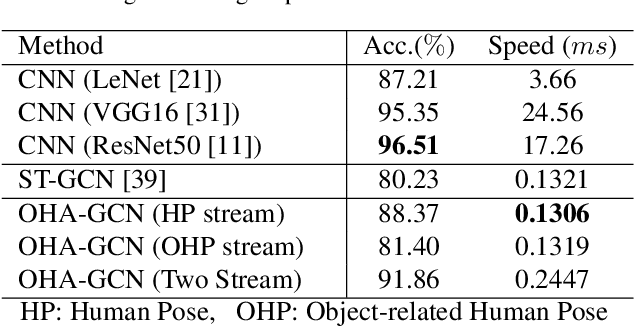
In visual surveillance systems, it is necessary to recognize the behavior of people handling objects such as a phone, a cup, or a plastic bag. In this paper, to address this problem, we propose a new framework for recognizing object-related human actions by graph convolutional networks using human and object poses. In this framework, we construct skeletal graphs of reliable human poses by selectively sampling the informative frames in a video, which include human joints with high confidence scores obtained in pose estimation. The skeletal graphs generated from the sampled frames represent human poses related to the object position in both the spatial and temporal domains, and these graphs are used as inputs to the graph convolutional networks. Through experiments over an open benchmark and our own data sets, we verify the validity of our framework in that our method outperforms the state-of-the-art method for skeleton-based action recognition.