 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELO: Efficient Layer-Specific Optimization for Continual Pretraining of Multilingual LLMs
Jan 07, 2026We propose an efficient layer-specific optimization (ELO) method designed to enhance continual pretraining (CP) for specific languages in multilingual large language models (MLLMs). This approach addresses the common challenges of high computational cost and degradation of source language performance associated with traditional CP. The ELO method consists of two main stages: (1) ELO Pretraining, where a small subset of specific layers, identified in our experiments as the critically important first and last layers, are detached from the original MLLM and trained with the target language. This significantly reduces not only the number of trainable parameters but also the total parameters computed during the forward pass, minimizing GPU memory consumption and accelerating the training process. (2) Layer Alignment, where the newly trained layers are reintegrated into the original model, followed by a brief full fine-tuning step on a small dataset to align the parameters. Experimental results demonstrate that the ELO method achieves a training speedup of up to 6.46 times compared to existing methods, while improving target language performance by up to 6.2\% on qualitative benchmarks and effectively preserving source language (English) capabilities.
Learning to Discriminate Information for Online Action Detection
Dec 10, 2019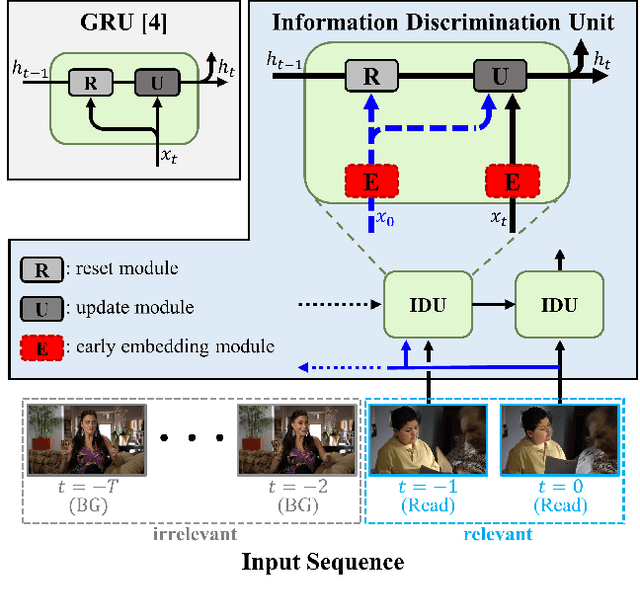
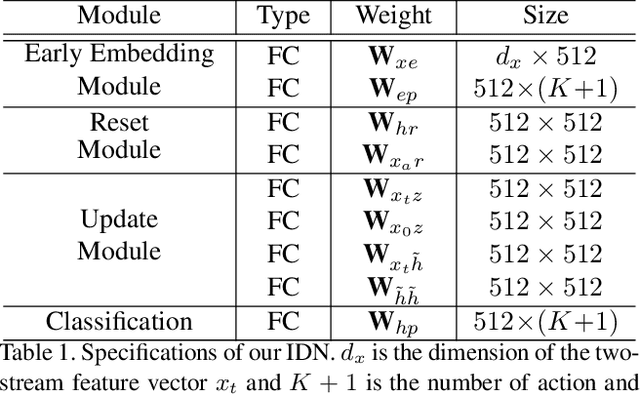
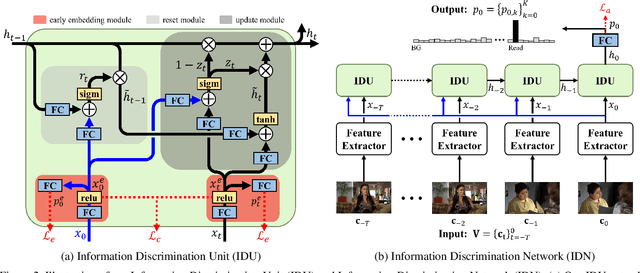
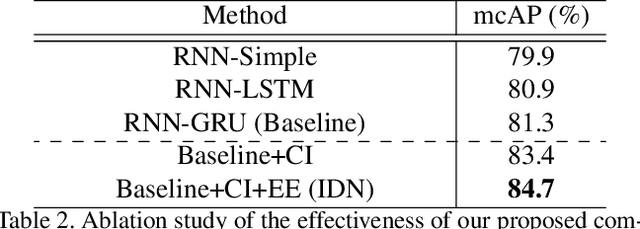
From a streaming video, online action detection aims to identify actions in the present. For this task, previous methods use recurrent networks to model the temporal sequence of current action frames. However, these methods overlook the fact that an input image sequence includes background and irrelevant actions as well as the action of interest. For online action detection, in this paper, we propose a novel recurrent unit to explicitly discriminate the information relevant to an ongoing action from others. Our unit, named Information Discrimination Unit (IDU), decides whether to accumulate input information based on its relevance to the current action. This enables our recurrent network with IDU to learn a more discriminative representation for identifying ongoing actions. In experiments on two benchmark datasets, TVSeries and THUMOS-14, the proposed method outperforms state-of-the-art methods by a significant margin. Moreover, we demonstrate the effectiveness of our recurrent unit by conducting comprehensive ablation studies.
SRG: Snippet Relatedness-based Temporal Action Proposal Generator
Nov 26, 2019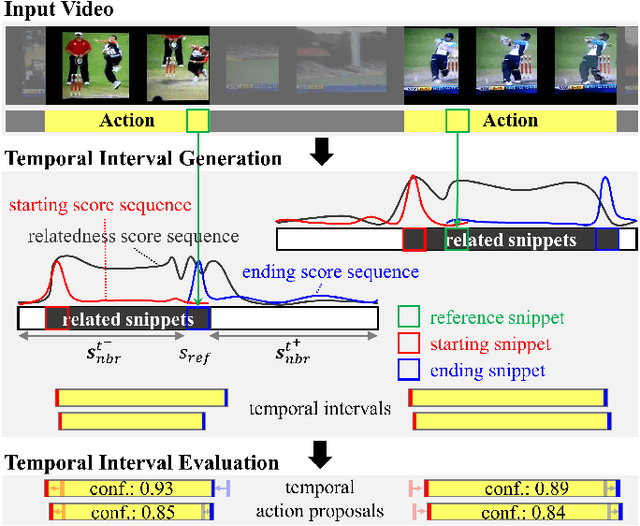
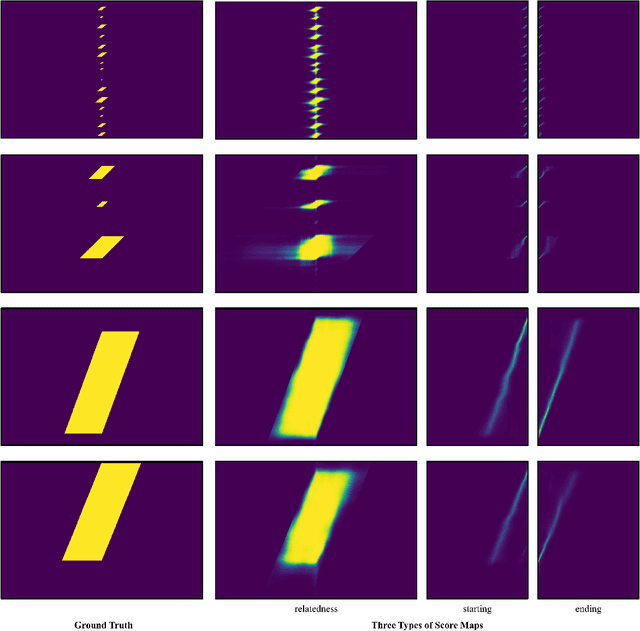
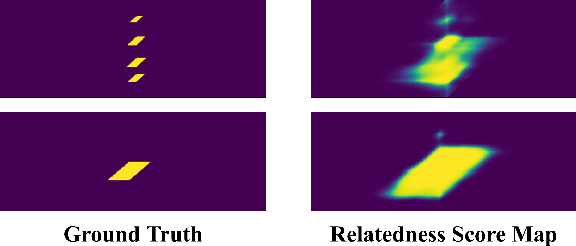
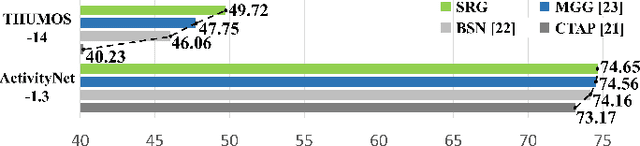
Recent temporal action proposal generation approaches have suggested integrating segment- and snippet score-based methodologies to produce proposals with high recall and accurate boundaries. In this paper, different from such a hybrid strategy, we focus on the potential of the snippet score-based approach. Specifically, we propose a new snippet score-based method, named Snippet Relatedness-based Generator (SRG), with a novel concept of "snippet relatedness". Snippet relatedness represents which snippets are related to a specific action instance. To effectively learn this snippet relatedness, we present ``pyramid non-local operations'' for locally and globally capturing long-range dependencies among snippets. By employing these components, SRG first produces a 2D relatedness score map that enables the generation of various temporal intervals reliably covering most action instances with high overlap. Then, SRG evaluates the action confidence scores of these temporal intervals and refines their boundaries to obtain temporal action proposals. On THUMOS-14 and ActivityNet-1.3 datasets, SRG outperforms state-of-the-art methods for temporal action proposal generation. Furthermore, compared to competing proposal generators, SRG leads to significant improvements in temporal action detection.
CenterMask : Real-Time Anchor-Free Instance Segmentation
Nov 15, 2019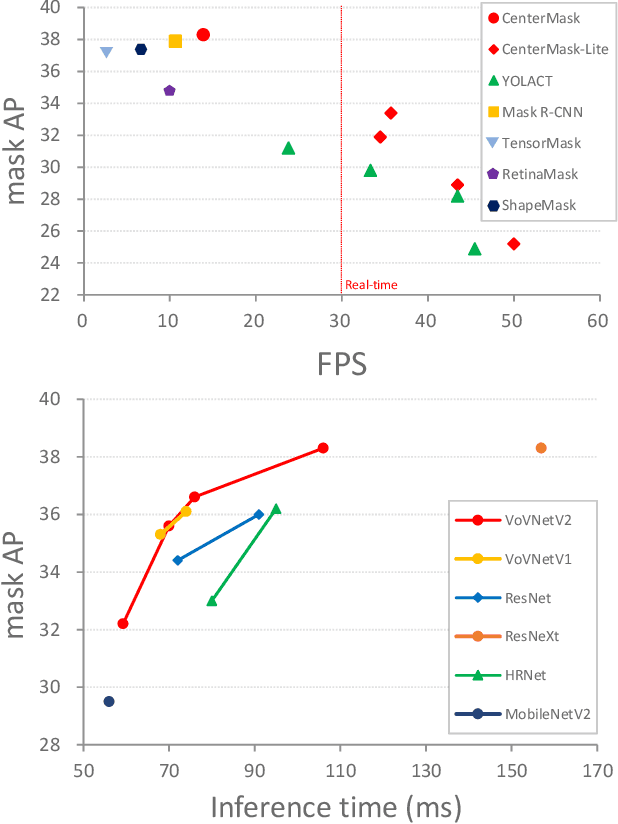
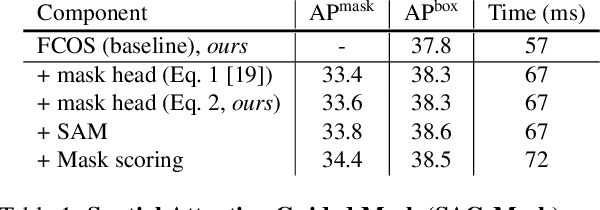
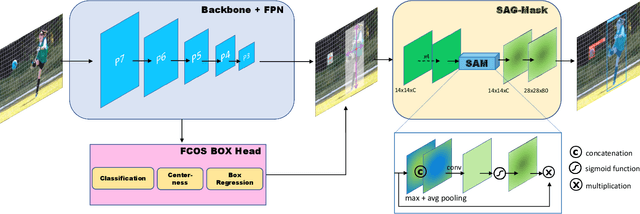
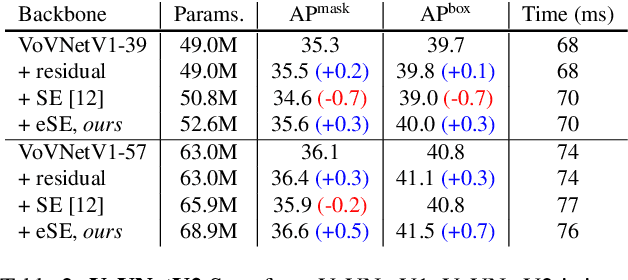
We propose a simple yet efficient anchor-free instance segmentation, called CenterMask, that adds a novel spatial attention-guided mask (SAG-Mask) branch to anchor-free one stage object detector (FCOS) in the same vein with Mask R-CNN. Plugged into the FCOS object detector, the SAG-Mask branch predicts a segmentation mask on each box with the spatial attention map that helps to focus on informative pixels and suppress noise. We also present an improved VoVNetV2 with two effective strategies: adds (1) residual connection for alleviating the saturation problem of larger VoVNet and (2) effective Squeeze-Excitation (eSE) deals with the information loss problem of original SE. With SAG-Mask and VoVNetV2, we deign CenterMask and CenterMask-Lite that are targeted to large and small models, respectively. CenterMask outperforms all previous state-of-the-art models at a much faster speed. CenterMask-Lite also achieves 33.4\% mask AP / 38.0\% box AP, outperforming the state-of-the-art by 2.6 / 7.0 AP gain, respectively, at over 35fps on Titan Xp. We hope that CenterMask and VoVNetV2 can serve as a solid baseline of real-time instance segmentation and backbone network for various vision tasks, respectively. Code will be released.
An Energy and GPU-Computation Efficient Backbone Network for Real-Time Object Detection
Apr 22, 2019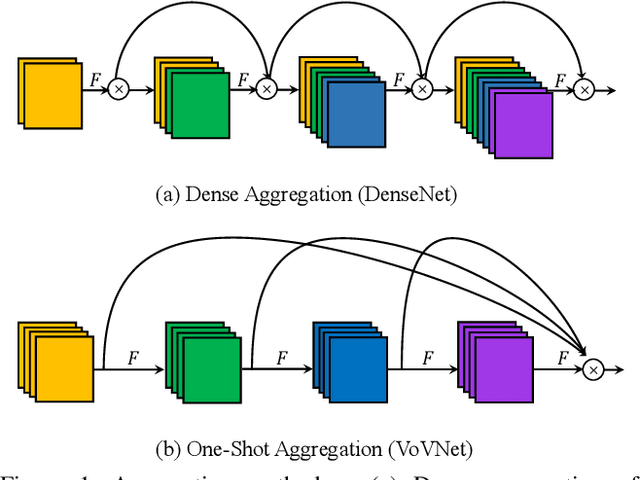
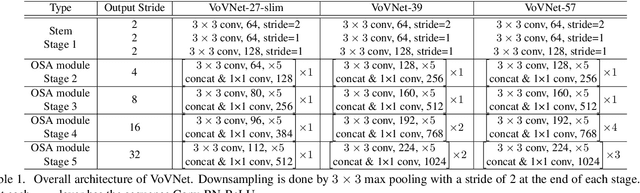
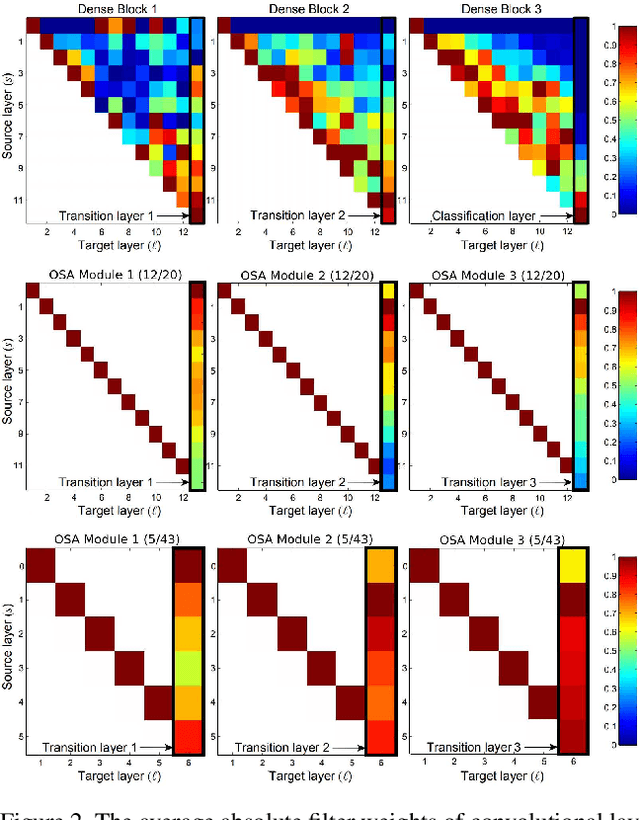
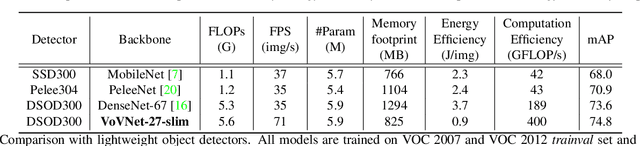
As DenseNet conserves intermediate features with diverse receptive fields by aggregating them with dense connection, it shows good performance on the object detection task. Although feature reuse enables DenseNet to produce strong features with a small number of model parameters and FLOPs, the detector with DenseNet backbone shows rather slow speed and low energy efficiency. We find the linearly increasing input channel by dense connection leads to heavy memory access cost, which causes computation overhead and more energy consumption. To solve the inefficiency of DenseNet, we propose an energy and computation efficient architecture called VoVNet comprised of One-Shot Aggregation (OSA). The OSA not only adopts the strength of DenseNet that represents diversified features with multi receptive fields but also overcomes the inefficiency of dense connection by aggregating all features only once in the last feature maps. To validate the effectiveness of VoVNet as a backbone network, we design both lightweight and large-scale VoVNet and apply them to one-stage and two-stage object detectors. Our VoVNet based detectors outperform DenseNet based ones with 2x faster speed and the energy consumptions are reduced by 1.6x - 4.1x. In addition to DenseNet, VoVNet also outperforms widely used ResNet backbone with faster speed and better energy efficiency. In particular, the small object detection performance has been significantly improved over DenseNet and ResNet.
Visual Relationship Detection with Language prior and Softmax
Apr 16, 2019

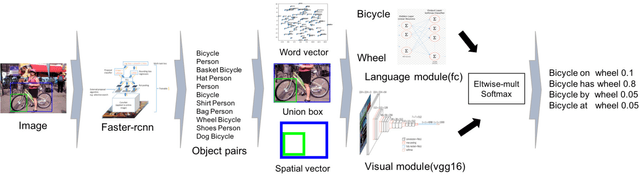
Visual relationship detection is an intermediate image understanding task that detects two objects and classifies a predicate that explains the relationship between two objects in an image. The three components are linguistically and visually correlated (e.g. "wear" is related to "person" and "shirt", while "laptop" is related to "table" and "on") thus, the solution space is huge because there are many possible cases between them. Language and visual modules are exploited and a sophisticated spatial vector is proposed. The models in this work outperformed the state of arts without costly linguistic knowledge distillation from a large text corpus and building complex loss functions. All experiments were only evaluated on Visual Relationship Detection and Visual Genome dataset.
* 6 pages, 4 figures
SC-FEGAN: Face Editing Generative Adversarial Network with User's Sketch and Color
Feb 18, 2019

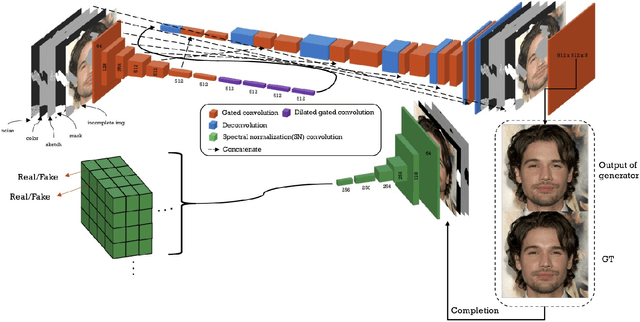

We present a novel image editing system that generates images as the user provides free-form mask, sketch and color as an input. Our system consist of a end-to-end trainable convolutional network. Contrary to the existing methods, our system wholly utilizes free-form user input with color and shape. This allows the system to respond to the user's sketch and color input, using it as a guideline to generate an image. In our particular work, we trained network with additional style loss which made it possible to generate realistic results, despite large portions of the image being removed. Our proposed network architecture SC-FEGAN is well suited to generate high quality synthetic image using intuitive user inputs.
Skeleton-based Action Recognition of People Handling Objects
Jan 21, 2019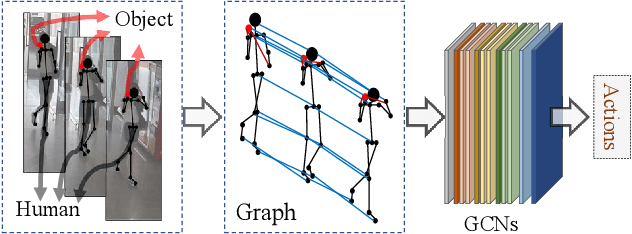


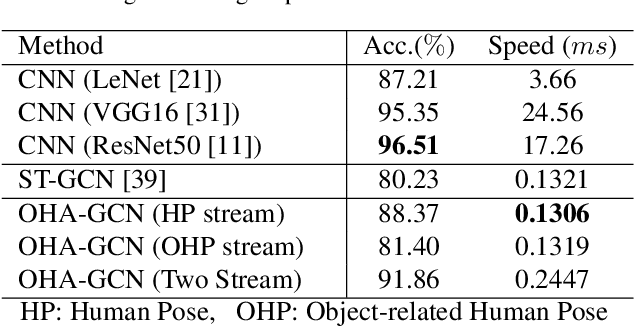
In visual surveillance systems, it is necessary to recognize the behavior of people handling objects such as a phone, a cup, or a plastic bag. In this paper, to address this problem, we propose a new framework for recognizing object-related human actions by graph convolutional networks using human and object poses. In this framework, we construct skeletal graphs of reliable human poses by selectively sampling the informative frames in a video, which include human joints with high confidence scores obtained in pose estimation. The skeletal graphs generated from the sampled frames represent human poses related to the object position in both the spatial and temporal domains, and these graphs are used as inputs to the graph convolutional networks. Through experiments over an open benchmark and our own data sets, we verify the validity of our framework in that our method outperforms the state-of-the-art method for skeleton-based action recognition.